- Al-Najim A, Al-Amoudi A, Ooishi K, et al. Intelligent maintenance recommender system[C]//2022 7th International Conference on Data Science and Machine Learning Applications (CDMA). IEEE, 2022: 212-218.
推荐引擎是智能系统,可根据用户的兴趣向特定用户(个人或公司)推荐最合适的项目(产品或服务)。由于兴趣和倾向是未来选择的有效指示,推荐分析通常基于有关项目、用户以及服务提供商和用户之间先前交互的相关信息。推荐系统的目标是通过评估用户的活动和/或其他用户的行为来预测用户的偏好和兴趣,从而提供个性化服务。
J. Lu, D. Wu, M. Mao, W. Wang, and G. Zhang, “Recommender system application developments: A survey,” Decis. Support Syst., vol. 74, pp. 12–32, 2015, doi: 10.1016/j.dss.2015.03.008.
推荐系统在质量和效率方面显示出显着的改进,这为服务提供商和用户层面的决策过程增加了价值。
Portugal, P. Alencar, and D. Cowan, “The use of machine learning algorithms in recommender systems: A systematic review,” Expert Syst. Appl., vol. 97, no. November 2015, pp. 205–227, 2018, doi: 10.1016/j.eswa.2017.12.020.
例如,推荐系统在降低搜索和选择产品的交易成本、增加电子商务业务的收入方面发挥着至关重要的作用。为了最大化用户利益,需要采用准确、高效的技术为用户提供适当、可靠的推荐。
F. O. Isinkaye, Y. O. Folajimi, and B. A. Ojokoh, “Recommendation systems: Principles, methods and evaluation,” Egypt. Informatics J., vol. 16, no. 3, pp. 261–273, 2015, doi: 10.1016/j.eij.2015.06.005.
如今,推荐系统已应用于许多领域,例如 Netflix [4] 等视频服务、亚马逊 [5] 等在线商店以及 Twitter [6] 等社交媒体。
C. A. Gomez-Uribe and N. Hunt, “The netflix recommender system: Algorithms, business value, and innovation,” ACM Trans. Manag. Inf. Syst., vol. 6, no. 4, 2015, doi: 10.1145/2843948.
G. Linden, B. Smith, and J. York, “Amazon.com recommendations: Item-to-item collaborative filtering,” IEEE Internet Comput., vol. 7, no. 1, pp. 76–80, 2003, doi: 10.1109/MIC.2003.1167344.
N. Ben-Lhachemi and E. H. Nfaoui, “Using tweets embeddings for hashtag recommendation in twitter,” Procedia Comput. Sci., vol. 127, pp. 7–15, 2018, doi: 10.1016/j.procs.2018.01.092.
在工业领域,维护是确保工厂过程安全、可靠、高效的关键操作之一。工厂维护团队的关键绩效指标(KPI)是更短的计划外停机时间。为了减少与预防性维护相关的停机时间和维护成本,公司已转向主要基于高级分析和大数据的预测性维护,以便能够识别故障的根本原因并更有效地预测故障何时发生。另一方面,一旦发生突发资产故障,维护团队应迅速制定并执行维护计划。然而,规划需要时间和经验,因为失败的情况各不相同,可供选择的选项也很多。维护团队需要从选项中选择适当的维护操作。如果选择了错误的维护操作,恢复和返工时间会使停机时间增加更多。因此维护动作的准确性非常重要。最近,维护作业推荐系统的实施开始引起业界的关注。
文献中发现的相关工作之一是由 Ying Huang 等人提出的。作者提出了一个推荐系统,为给定的维护请求推荐最合适的维护文档。该系统使用推荐引擎概念,根据与历史数据的相似性、专家知识和聚类技术来推荐合适的维护文档。
Ying Huang, Mickaël Gardoni, Amadou Coulibaly, et al. “A decision support system designed for personalized maintenance recommendation based on proactive maintenance”, In ICED, 2009
Min 开发了一种基于协同过滤的机器学习推荐系统,旨在减少 oil well 设施的意外停机。开发的推荐系统利用客户之间的相似性来预测未来的购买并提出产品推荐。该模型能够为客户减少约 250 万美元的成本,并将每位客户每年的意外设备故障减少 1.7%。
A. Min, “Reducing Oil Well Downtime with a Machine Learning Recommender System Reducing Oil Well Downtime with a Machine Learning Recommender System,” 2020.
Wang 等人提出了一种基于矩阵分解技术的轴承状态识别协同过滤推荐系统。通过该方法对外环上不同位置的故障和不同类型的故障进行了分析。系统经过测试,准确率达到90%以上。
G. Wang, Y. He, Y. Peng, and H. Li, “Bearing Fault Identification Method Based on Collaborative Filtering Recommendation Technology,” Shock Vib., vol. 2019, 2019, doi: 10.1155/2019/7378526.
Das 在构建了基于交替最小二乘非负矩阵分解(ALS NMF)技术的协同过滤推荐系统来预测工业设备中的问题类型。系统在测试集上实现的准确率为 49.3%。尽管系统的准确度较低,但它能够识别设备中一些未知的问题类型。
S. Das, “Maintenance action recommendation using collaborative filtering,” Int. J. Progn. Heal. Manag., vol. 4, no. 2, pp. 1–7, 2013.
Anthony 提出了一种维护推荐系统,使用计算机化维护管理系统(CMMS)数据作为文本信息,使用能源管理和控制系统(EMCS)数据作为传感器数据。文本数据已使用扩展布尔模型进行处理。推荐引擎比较文本问题描述符和传感器数据描述符,以确定先前的维护操作和即将到来的维护操作之间的相似程度。
B. Anthony, “Design of a Maintenance and Operations Recommender,” Ensemble, vol. 15, no. 4, pp. 250–260, 2013.
Sun 等人提出了一种基于时间序列的推荐系统来预测石油钻井行业项目的安全检查顺序。系统预测每个项目的安全检查次数,并对其进行排序,生成安全检查流程。当系统进行测试时,发现它能够提供更好的安全检查程序。
S. B. Sun, X. L. Dong, L. Zhang, Z. J. Jing, and F. Min, “Time series based interactive recommendation for petroleum drilling safety check,” Proc. - Int. Conf. Mach. Learn. Cybern., vol. 1, no. 1, pp. 13–18, 2016, doi: 10.1109/ICMLC.2016.7860870.
识别故障的根本原因只是维护活动的第一步。然而,为了在行业中执行适当的维护操作,需要更多有关所需准备、设备、工具和技能的信息,以遵守维护程序和安全要求。虽然文献中的其他论文旨在利用推荐系统来识别故障根本原因,但本研究活动旨在开发一个推荐系统来推荐所需的维护程序。除了识别故障根本原因之外,我们的系统还可以自动建议必要的维护计划,包括所需的维护操作、准备活动工作、安全要求以及适合给定故障的任何其他操作。因此,维护团队可以在短时间内确定适当的维护准备操作。该系统可以增加的另一个价值是知识积累和向年轻成员的转移。
推荐系统 #
本节介绍推荐系统的两种方法,它们利用人工智能技术来推荐针对给定缺陷采取的维护操作。第一种方法是单阶段推荐器,它根据新缺陷与数据集中其他缺陷之间的相似性来推荐维护操作。然后,推荐系统根据最相似的缺陷建议合适的维护操作。第二种方法是多阶段推荐系统,其中推荐集是逐步生成的。在每次迭代中,我们推荐一个项目/特征,然后该项目/特征将用作输入的一部分来估计下一个项目/特征,依此类推,直到推荐所有所需的特征。
数据集 #
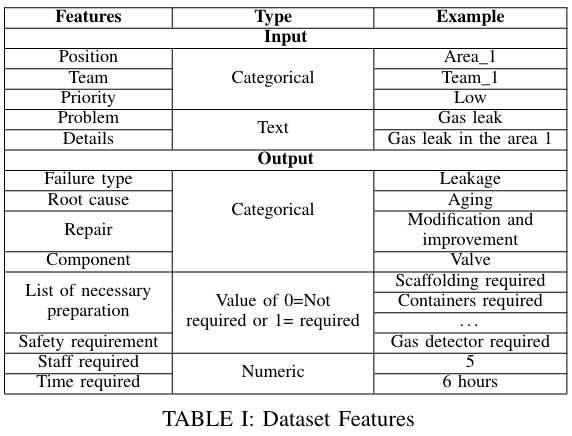
使用的数据集是从一家化工厂过去十年生成的实际维护数据库中收集的。数据集中的每一行对应一个唯一的缺陷,其中列对应缺陷特征和相关的维护操作。在这个系统中,我们读取五个不同的输入:位置、优先级、团队、问题描述和详细描述。输出将是故障类型、根本原因、维修、组件、所需时间、所需人员数量以及必要的准备措施列表,如 TABLE I 所示。
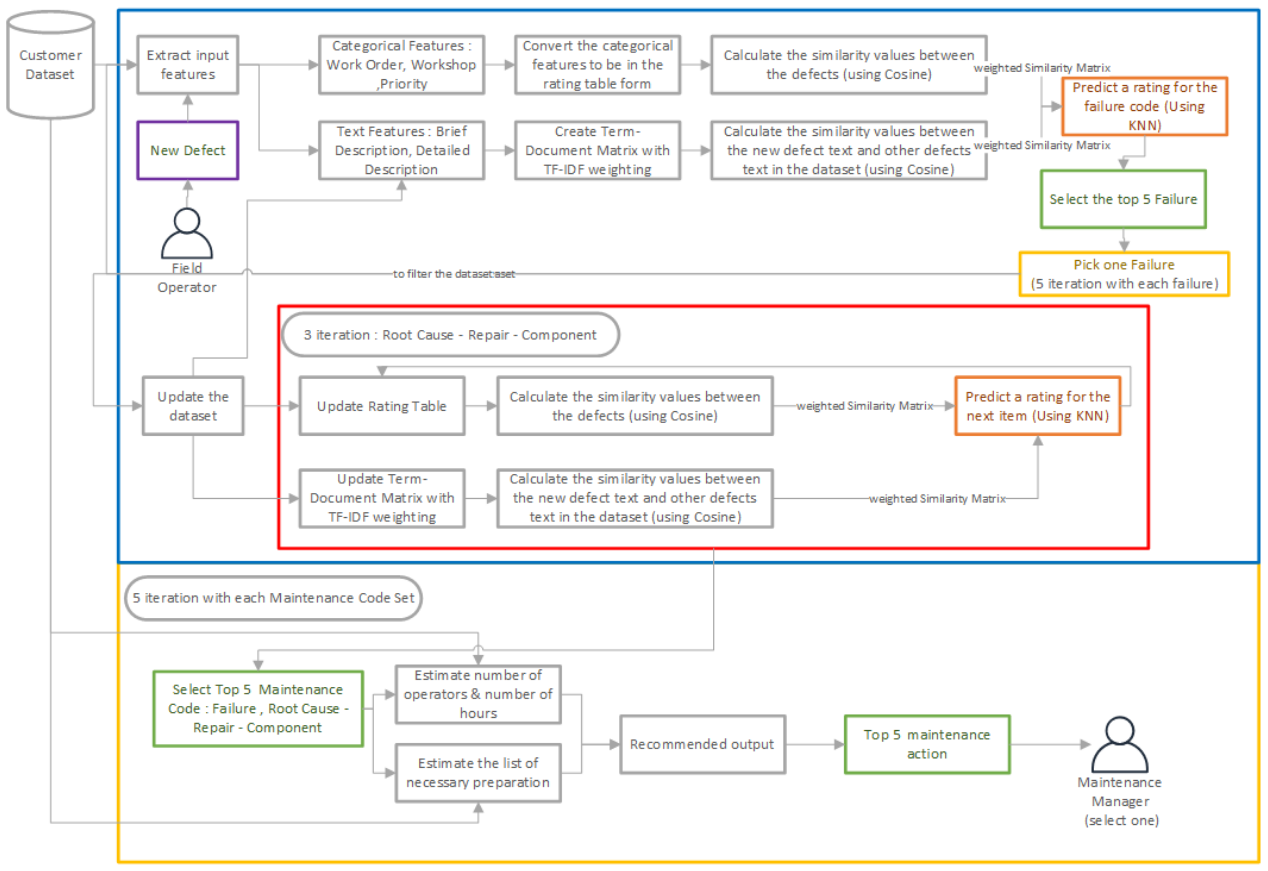
单阶段推荐系统 #
该系统由三个模块组成。
- 第一个模块是数据准备模块,系统从外部 CSV 文件读取数据并构建评级表以将其传递到下一阶段。
- 第二个模块是推荐引擎模块,系统读取新缺陷的信息以及前一个模块传递过来的评级表,构建新缺陷与历史数据中每个缺陷的相似度矩阵,并输出前五名类似的缺陷。
- 第三个模块是维护动作提取模块。在该模块中,系统从原始数据集中提取前一个模块传递的前五个相似缺陷所采取的维护操作,并将其推荐给用户。
下图说明了系统的工作流程。
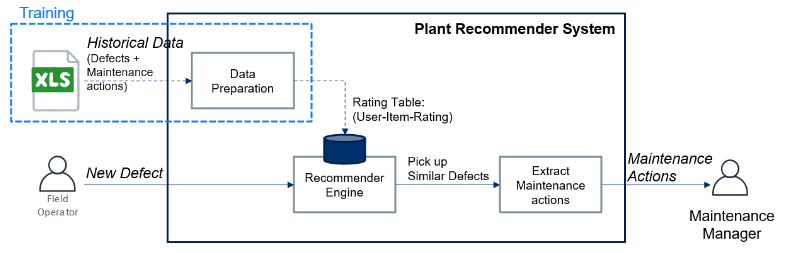
1. 数据预处理
第一个模块是数据准备模块,其中构建评级表并将其传递给推荐引擎。
评级表由三列组成,分别包含以下信息:用户ID、项目信息和评级。
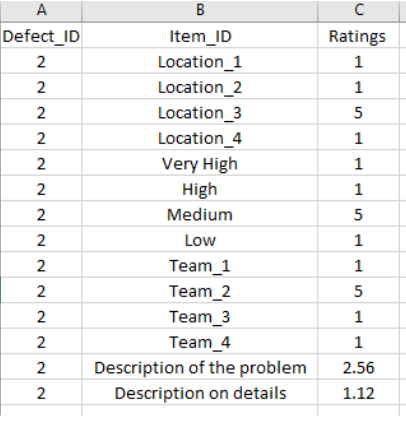
- 在此项目中,我们将每个缺陷视为唯一用户,因此第一列将包含缺陷 ID。第二列包含将根据数据类型进行处理的项目信息,可将其分为两组。第一组包含类别输入,其中包括位置、优先级和团队。
- 第二列将填充该组可能的特征值(例如位置 1、位置 2、优先级 1、优先级 2、团队 1、团队 2…等)。而包括文本输入(简要和详细描述)的第二组将通过插入指示两个输入的标签在评级表上进行处理(即,在第二列中,我们将插入一个用于简要描述的标签,另一个用于详细描述的标签)的描述)。
- 第三列包含将根据相应功能的数据类型分配的评级值。如果数据类型是分类的,则评级值为 5 或 1。值 5 表示特定缺陷的真实项目对。例如,如果分配给位置 3 上的缺陷 2 的评级为 5,则这意味着缺陷 2 发生在位置 3。而其他位置上的缺陷 2 的评级将为 1,因为缺陷 2 未发生在其他位置。另一方面,文本输入具有一个评级值,该评级值表示新缺陷的文本输入与数据集中其他缺陷之间的相似度,该相似度是使用余弦相似度计算的。
余弦算法的输入是一个术语文档矩阵,该矩阵是通过称为术语频率 - 逆文档频率 (TFIDF) 的信息检索算法生成的。 术语-文档矩阵由包含所有缺陷的关键术语的行和包含缺陷标识符(缺陷 ID)的列组成。 单元格内是每个单词的频率,按输入大小加权。 TF-IDF算法由以下公式计算
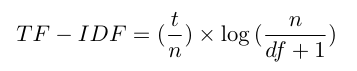
- t:文档 d 中某个单词出现的次数
- n:文档总数
- df:包含给定单词的文档数量
2. 推荐引擎
在此模块中,推荐引擎是根据前一个模块的评级表构建的,以查找最相似的缺陷。一般来说,推荐系统会预测新用户可以给项目的评分,以推荐评分最高的项目。然而,由于缺少评级反馈,因此无法在系统中应用评级预测。因此,我们取消了最后一步,即评级预测,并仅找到与新缺陷最相似的缺陷。使用余弦相似度计算相似度,找出新缺陷与数据集中每个缺陷之间的距离,并构建相似度矩阵。两个向量之间的余弦相似度可以由下式给出:
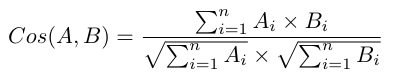
从这个矩阵中,我们选择前五个相似的缺陷并将它们传递到最后一个模块。 在最后一个模块中,我们从原始数据集中提取前五个相似缺陷所采取的维护操作以进行推荐,从而结束该过程。
多级推荐系统 #