
一个HTTP请求的处理过程 #
Spring Web 最核心的流程无非就是一个 HTTP 请求的处理过程。这里我以 Spring Boot 的使用为例,以尽量简单的方式带你梳理下。
首先,回顾下我们是怎么添加一个 HTTP 接口的,示例如下:
@RestController
public class HelloWorldController {
@RequestMapping(path = "hi", method = RequestMethod.GET)
public String hi(){
return "helloworld";
};
}
这是我们最喜闻乐见的一个程序,但是对于很多程序员而言,其实完全不知道为什么这样就工作起来了。毕竟,不知道原理,它也能工作起来。
但是,假设你是一个严谨且有追求的人,你大概率是有好奇心去了解它的。而且相信我,这个问题面试也可能会问到。我们一起来看看它背后的故事。
其实仔细看这段程序,你会发现一些关键的“元素”:
- 请求的 Path:hi
- 请求的方法:Get
- 对应方法的执行:hi()
那么,假设让你自己去实现 HTTP 的请求处理,你可能会写出这样一段伪代码:
public class HttpRequestHandler{
Map<RequestKey, Method> mapper = new HashMap<>();
public Object handle(HttpRequest httpRequest){
RequestKey requestKey = getRequestKey(httpRequest);
Method method = this.mapper.getValue(requestKey);
Object[] args = resolveArgsAccordingToMethod(httpRequest, method);
return method.invoke(controllerObject, args);
};
}
那么现在需要哪些组件来完成一个请求的对应和执行呢?
- 需要有一个地方(例如 Map)去维护从 HTTP path/method 到具体执行方法的映射;
- 当一个请求来临时,根据请求的关键信息来获取对应的需要执行的方法;
- 根据方法定义解析出调用方法的参数值,然后通过反射调用方法,获取返回结果。
除此之外,你还需要一个东西,就是利用底层通信层来解析出你的 HTTP 请求。只有解析出请求了,才能知道 path/method 等信息,才有后续的执行,否则也是“巧妇难为无米之炊”了。
所以综合来看,你大体上需要这些过程才能完成一个请求的解析和处理。那么接下来我们就按照处理顺序分别看下 Spring Boot 是如何实现的,对应的一些关键实现又长什么样。
首先,解析 HTTP 请求。对于 Spring 而言,它本身并不提供通信层的支持,它是依赖于 Tomcat、Jetty 等容器来完成通信层的支持,例如当我们引入 Spring Boot 时,我们就间接依赖了 Tomcat。依赖关系图如下:
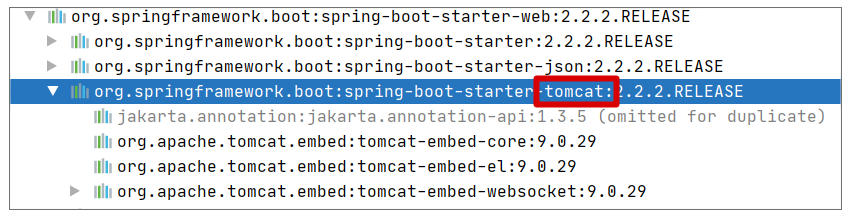
另外,正是这种自由组合的关系,让我们可以做到直接置换容器而不影响功能。例如我们可以通过下面的配置从默认的 Tomcat 切换到 Jetty:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-tomcat</artifactId>
</exclusion>
</exclusions>-
</dependency>
<!-- Use Jetty instead -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jetty</artifactId>
</dependency>
依赖了 Tomcat 后,Spring Boot 在启动的时候,就会把 Tomcat 启动起来做好接收连接的准备。
关于 Tomcat 如何被启动,你可以通过下面的调用栈来大致了解下它的过程:
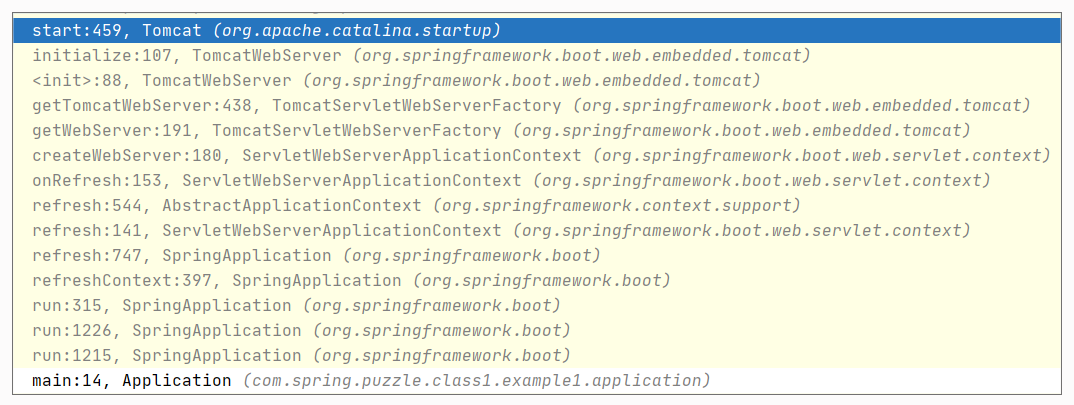
说白了,就是调用下述代码行就会启动 Tomcat:
SpringApplication.run(Application.class, args);
那为什么使用的是 Tomcat?你可以看下面这个类,或许就明白了:
//org.springframework.boot.autoconfigure.web.servlet.ServletWebServerFactoryConfiguration
class ServletWebServerFactoryConfiguration {
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass({ Servlet.class, Tomcat.class, UpgradeProtocol.class })
@ConditionalOnMissingBean(value = ServletWebServerFactory.class, search = SearchStrategy.CURRENT)
public static class EmbeddedTomcat {
@Bean
public TomcatServletWebServerFactory tomcatServletWebServerFactory(
//省略非关键代码
return factory;
}
}
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass({ Servlet.class, Server.class, Loader.class, WebAppContext.class })
@ConditionalOnMissingBean(value = ServletWebServerFactory.class, search = SearchStrategy.CURRENT)
public static class EmbeddedJetty {
@Bean
public JettyServletWebServerFactory JettyServletWebServerFactory(
ObjectProvider<JettyServerCustomizer> serverCustomizers) {
//省略非关键代码
return factory;
}
}
//省略其他容器配置
}
前面我们默认依赖了 Tomcat 内嵌容器的 JAR,所以下面的条件会成立,进而就依赖上了 Tomcat:
@ConditionalOnClass({ Servlet.class, Tomcat.class, UpgradeProtocol.class })
有了 Tomcat 后,当一个 HTTP 请求访问时,会触发 Tomcat 底层提供的 NIO 通信来完成数据的接收,这点我们可以从下面的代码(org.apache.tomcat.util.net.NioEndpoint.Poller#run)中看出来:
@Override
public void run() {
while (true) {
//省略其他非关键代码
//轮询注册的兴趣事件
if (wakeupCounter.getAndSet(-1) > 0) {
keyCount = selector.selectNow();
} else {
keyCount = selector.select(selectorTimeout);
//省略其他非关键代码
Iterator<SelectionKey> iterator =
keyCount > 0 ? selector.selectedKeys().iterator() : null;
while (iterator != null && iterator.hasNext()) {
SelectionKey sk = iterator.next();
NioSocketWrapper socketWrapper = (NioSocketWrapper)
//处理事件
processKey(sk, socketWrapper);
//省略其他非关键代码
}
//省略其他非关键代码
}
}
上述代码会完成请求事件的监听和处理,最终在 processKey 中把请求事件丢入线程池去处理。请求事件的接收具体调用栈如下:
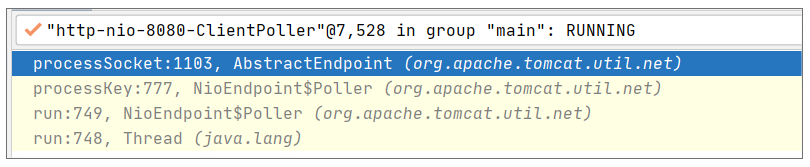
线程池对这个请求的处理的调用栈如下:
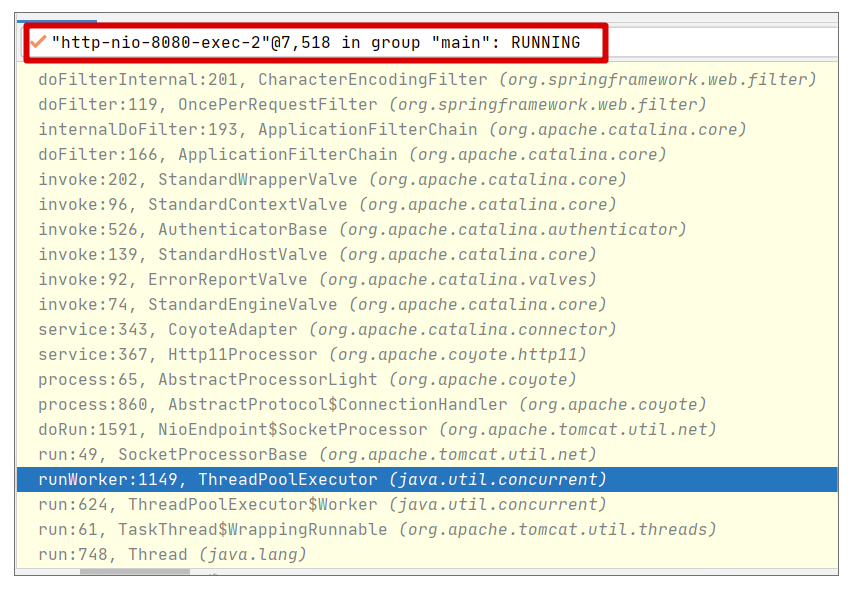
在上述调用中,最终会进入 Spring Boot 的处理核心,即 DispatcherServlet(上述调用栈没有继续截取完整调用,所以未显示)。可以说,DispatcherServlet 是用来处理 HTTP 请求的中央调度入口程序,为每一个 Web 请求映射一个请求的处理执行体(API controller/method)。
我们可以看下它的核心是什么?它本质上就是一种 Servlet,所以它是由下面的 Servlet 核心方法触发:
javax.servlet.http.HttpServlet#service(javax.servlet.ServletRequest, javax.servlet.ServletResponse)
最终它执行到的是下面的 doService(),这个方法完成了请求的分发和处理:
@Override
protected void doService(HttpServletRequest request, HttpServletResponse response) throws Exception {
doDispatch(request, response);
}
我们可以看下它是如何分发和执行的:
protected void doDispatch(HttpServletRequest request, HttpServletResponse response) throws Exception {
// 省略其他非关键代码
// 1. 分发:Determine handler for the current request.
HandlerExecutionChain mappedHandler = getHandler(processedRequest);
// 省略其他非关键代码
//Determine handler adapter for the current request.
HandlerAdapter ha = getHandlerAdapter(mappedHandler.getHandler());
// 省略其他非关键代码
// 2. 执行:Actually invoke the handler.
mv = ha.handle(processedRequest, response, mappedHandler.getHandler());
// 省略其他非关键代码
}
在上述代码中,很明显有两个关键步骤:
- 分发,即根据请求寻找对应的执行方法
寻找方法参考 DispatcherServlet#getHandler,具体的查找远比开始给出的 Map 查找来得复杂,但是无非还是一个根据请求寻找候选执行方法的过程,这里我们可以通过一个调试视图感受下这种对应关系:
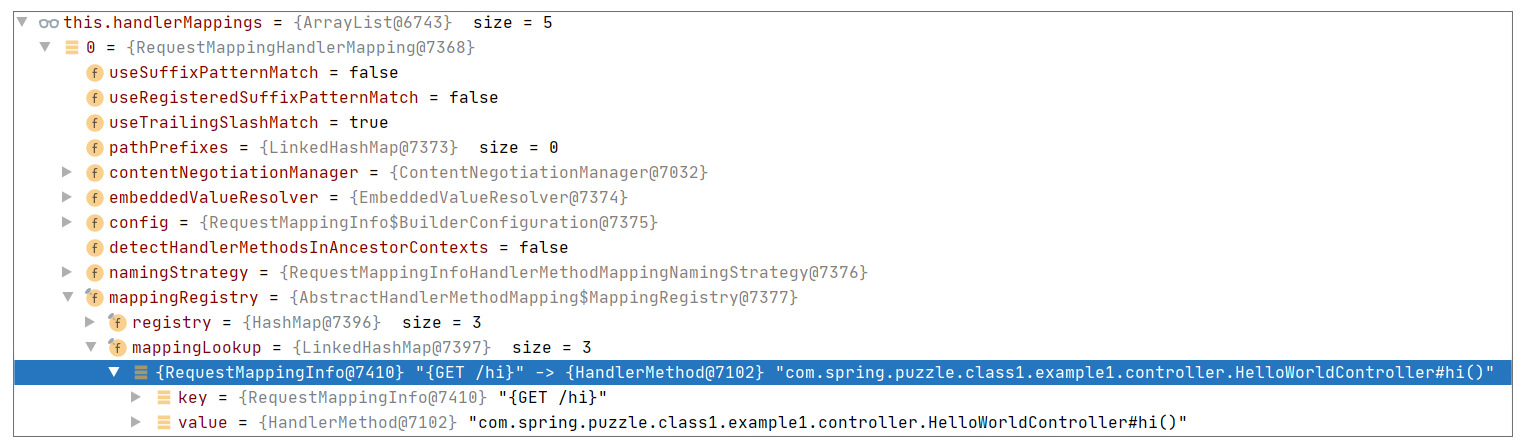
这里的关键映射 Map,其实就是上述调试视图中的 RequestMappingHandlerMapping。
- 执行,反射执行寻找到的执行方法
这点可以参考下面的调试视图来验证这个结论,参考代码 org.springframework.web.method.support.InvocableHandlerMethod#doInvoke:
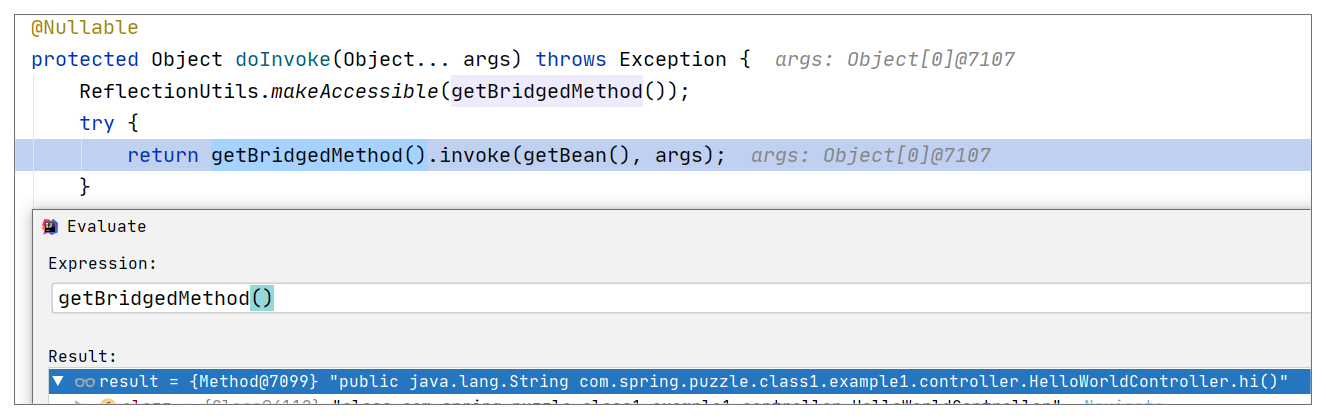
最终我们是通过反射来调用执行方法的。
通过上面的梳理,你应该基本了解了一个 HTTP 请求是如何执行的。但是你可能会产生这样一个疑惑:Handler 的映射是如何构建出来的呢?
说白了,核心关键就是 RequestMappingHandlerMapping 这个 Bean 的构建过程。
它的构建完成后,会调用 afterPropertiesSet 来做一些额外的事,这里我们可以先看下它的调用栈:

其中关键的操作是 AbstractHandlerMethodMapping#processCandidateBean 方法:
protected void processCandidateBean(String beanName) {
//省略非关键代码
if (beanType != null && isHandler(beanType)) {
detectHandlerMethods(beanName);
}
}
isHandler(beanType) 的实现参考以下关键代码:
@Override
protected boolean isHandler(Class<?> beanType) {
return (AnnotatedElementUtils.hasAnnotation(beanType, Controller.class) ||
AnnotatedElementUtils.hasAnnotation(beanType, RequestMapping.class));
}
这里你会发现,判断的关键条件是,是否标记了合适的注解(Controller 或者 RequestMapping)。只有标记了,才能添加到 Map 信息。换言之,Spring 在构建 RequestMappingHandlerMapping 时,会处理所有标记 Controller 和 RequestMapping 的注解,然后解析它们构建出请求到处理的映射关系。
以上即为 Spring Boot 处理一个 HTTP 请求的核心过程,无非就是绑定一个内嵌容器(Tomcat/Jetty/ 其他)来接收请求,然后为请求寻找一个合适的方法,最后反射执行它。当然,这中间还会掺杂无数的细节,不过这不重要,抓住这个核心思想对你接下来理解 Spring Web 中各种类型的错误案例才是大有裨益的!
09|Spring Web URL 解析常见错误 #
这里说的 Web 服务就是指使用 HTTP 协议的服务。而对于 HTTP 请求,首先要处理的就是 URL,所以今天我们就先来介绍下,在 URL 的处理上,Spring 都有哪些经典的案例。闲话少叙,下面我们直接开始演示吧。
案例 1:当 @PathVariable 遇到 /
在解析一个 URL 时,我们经常会使用 @PathVariable 这个注解。例如我们会经常见到如下风格的代码:
@RestController
@Slf4j
public class HelloWorldController {
@RequestMapping(path = "/hi1/{name}", method = RequestMethod.GET)
public String hello1(@PathVariable("name") String name){
return name;
};
}
当我们使用 http://localhost:8080/hi1/xiaoming 访问这个服务时,会返回"xiaoming",即 Spring 会把 name 设置为 URL 中对应的值。
看起来顺风顺水,但是假设这个 name 中含有特殊字符 / 时(例如http://localhost:8080/hi1/xiao/ming),会如何?如果我们不假思索,或许答案是"xiao/ming"?然而稍微敏锐点的程序员都会判定这个访问是会报错的,具体错误参考:
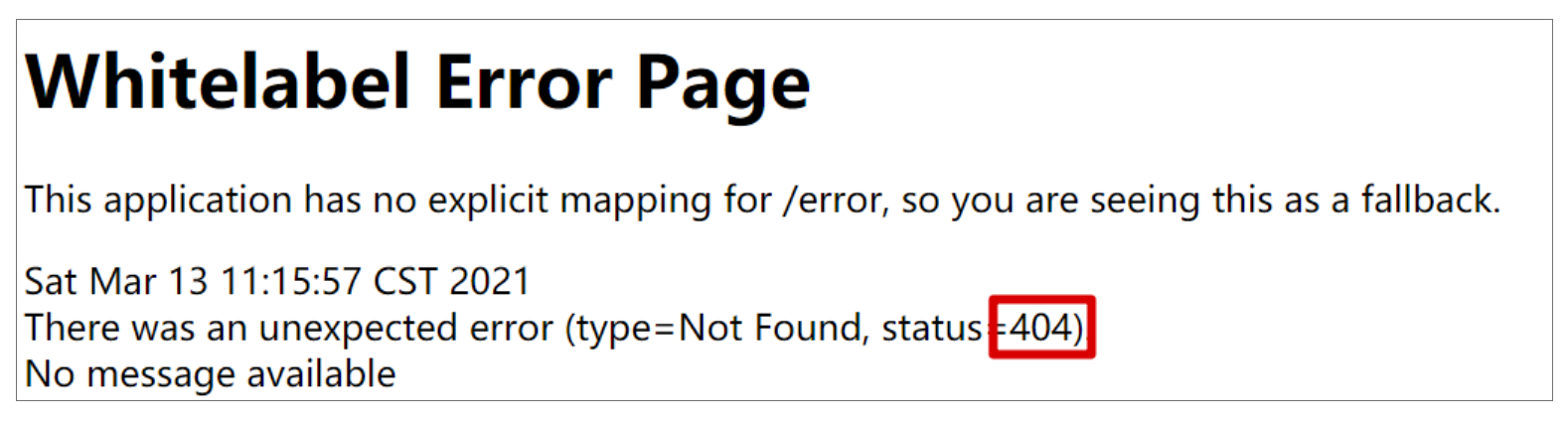
如图所示,当 name 中含有 /,这个接口不会为 name 获取任何值,而是直接报 Not Found 错误。当然这里的“找不到”并不是指 name 找不到,而是指服务于这个特殊请求的接口。
实际上,这里还存在另外一种错误,即当 name 的字符串以 / 结尾时,/ 会被自动去掉。例如我们访问 http://localhost:8080/hi1/xiaoming/,Spring 并不会报错,而是返回 xiaoming。
针对这两种类型的错误,应该如何理解并修正呢?
案例解析
实际上,这两种错误都是 URL 匹配执行方法的相关问题,所以我们有必要先了解下 URL 匹配执行方法的大致过程。参考 AbstractHandlerMethodMapping#lookupHandlerMethod:
@Nullable
protected HandlerMethod lookupHandlerMethod(String lookupPath, HttpServletRequest request) throws Exception {
List<Match> matches = new ArrayList<>();
//尝试按照 URL 进行精准匹配
List<T> directPathMatches = this.mappingRegistry.getMappingsByUrl(lookupPath);
if (directPathMatches != null) {
//精确匹配上,存储匹配结果
addMatchingMappings(directPathMatches, matches, request);
}
if (matches.isEmpty()) {
//没有精确匹配上,尝试根据请求来匹配
addMatchingMappings(this.mappingRegistry.getMappings().keySet(), matches, request);
}
if (!matches.isEmpty()) {
Comparator<Match> comparator = new MatchComparator(getMappingComparator(request));
matches.sort(comparator);
Match bestMatch = matches.get(0);
if (matches.size() > 1) {
//处理多个匹配的情况
}
//省略其他非关键代码
return bestMatch.handlerMethod;
}
else {
//匹配不上,直接报错
return handleNoMatch(this.mappingRegistry.getMappings().keySet(), lookupPath, request);
}
大体分为这样几个基本步骤。
- 根据 Path 进行精确匹配
这个步骤执行的代码语句是"this.mappingRegistry.getMappingsByUrl(lookupPath)",实际上,它是查询 MappingRegistry#urlLookup,它的值可以用调试视图查看,如下图所示:
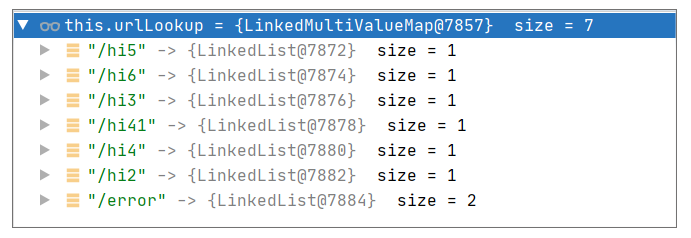
查询 urlLookup 是一个精确匹配 Path 的过程。很明显,http://localhost:8080/hi1/xiao/ming 的 lookupPath 是"/hi1/xiao/ming",并不能得到任何精确匹配。这里需要补充的是,"/hi1/{name}“这种定义本身也没有出现在 urlLookup 中。
- 假设 Path 没有精确匹配上,则执行模糊匹配
在步骤 1 匹配失败时,会根据请求来尝试模糊匹配,待匹配的匹配方法可参考下图:
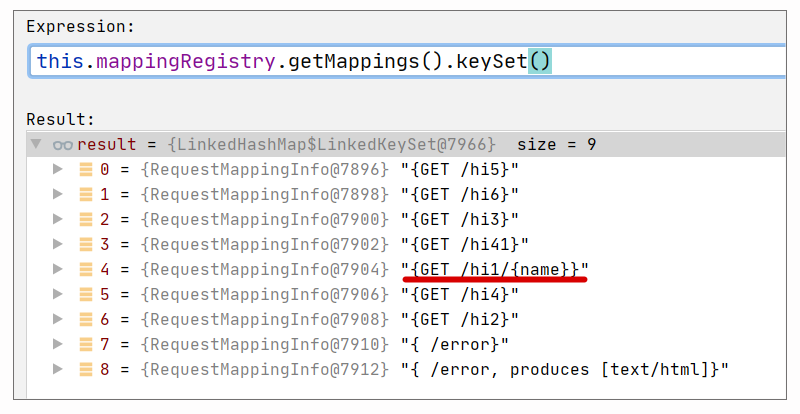
显然,"/hi1/{name}“这个匹配方法已经出现在待匹配候选中了。具体匹配过程可以参考方法 RequestMappingInfo#getMatchingCondition:
public RequestMappingInfo getMatchingCondition(HttpServletRequest request) {
RequestMethodsRequestCondition methods = this.methodsCondition.getMatchingCondition(request);
if (methods == null) {
return null;
}
ParamsRequestCondition params = this.paramsCondition.getMatchingCondition(request);
if (params == null) {
return null;
}
//省略其他匹配条件
PatternsRequestCondition patterns = this.patternsCondition.getMatchingCondition(request);
if (patterns == null) {
return null;
}
//省略其他匹配条件
return new RequestMappingInfo(this.name, patterns,
methods, params, headers, consumes, produces, custom.getCondition());
}
现在我们知道匹配会查询所有的信息,例如 Header、Body 类型以及 URL 等。如果有一项不符合条件,则不匹配。
在我们的案例中,当使用 http://localhost:8080/hi1/xiaoming 访问时,其中 patternsCondition 是可以匹配上的。实际的匹配方法执行是通过 AntPathMatcher#match 来执行,判断的相关参数可参考以下调试视图:

但是当我们使用 http://localhost:8080/hi1/xiao/ming 来访问时,AntPathMatcher 执行的结果是 /hi1/xiao/ming 匹配不上 /hi1/{name}。
- 根据匹配情况返回结果
如果找到匹配的方法,则返回方法;如果没有,则返回 null。
在本案例中,http://localhost:8080/hi1/xiao/ming 因为找不到匹配方法最终报 404 错误。追根溯源就是 AntPathMatcher 匹配不了”/hi1/xiao/ming"和”/hi1/{name}"。
另外,我们再回头思考 http://localhost:8080/hi1/xiaoming/ 为什么没有报错而是直接去掉了 /。这里我直接贴出了负责执行 AntPathMatcher 匹配的
PatternsRequestCondition#getMatchingPattern 方法的部分关键代码:
private String getMatchingPattern(String pattern, String lookupPath) {
//省略其他非关键代码
if (this.pathMatcher.match(pattern, lookupPath)) {
return pattern;
}
//尝试加一个/来匹配
if (this.useTrailingSlashMatch) {
if (!pattern.endsWith("/") && this.pathMatcher.match(pattern + "/", lookupPath)) {
return pattern + "/";
}
}
return null;
}
在这段代码中,AntPathMatcher 匹配不了"/hi1/xiaoming/“和”/hi1/{name}",所以不会直接返回。进而,在 useTrailingSlashMatch 这个参数启用时(默认启用),会把 Pattern 结尾加上 / 再尝试匹配一次。如果能匹配上,在最终返回 Pattern 时就隐式自动加 /。
很明显,我们的案例符合这种情况,等于说我们最终是用了 /hi1/{name}/ 这个 Pattern,而不再是 /hi1/{name}。所以自然 URL 解析 name 结果是去掉 / 的。
问题修正
针对这个案例,有了源码的剖析,我们可能会想到可以先用"**“匹配上路径,等进入方法后再尝试去解析,这样就可以万无一失吧。具体修改代码如下:
@RequestMapping(path = "/hi1/**", method = RequestMethod.GET)
public String hi1(HttpServletRequest request){
String requestURI = request.getRequestURI();
return requestURI.split("/hi1/")[1];
};
但是这种修改方法还是存在漏洞,假设我们路径的 name 中刚好又含有”/hi1/",则 split 后返回的值就并不是我们想要的。实际上,更合适的修订代码示例如下:
private AntPathMatcher antPathMatcher = new AntPathMatcher();
@RequestMapping(path = "/hi1/**", method = RequestMethod.GET)
public String hi1(HttpServletRequest request){
String path = (String) request.getAttribute(HandlerMapping.PATH_WITHIN_HANDLER_MAPPING_ATTRIBUTE);
//matchPattern 即为"/hi1/**"
String matchPattern = (String) request.getAttribute(HandlerMapping.BEST_MATCHING_PATTERN_ATTRIBUTE);
return antPathMatcher.extractPathWithinPattern(matchPattern, path);
};
现在我们知道匹配会查询所有的信息,例如 Header、Body 类型以及 URL 等。如果有一项不符合条件,则不匹配。
在我们的案例中,当使用 http://localhost:8080/hi1/xiaoming 访问时,其中 patternsCondition 是可以匹配上的。实际的匹配方法执行是通过 AntPathMatcher#match 来执行,判断的相关参数可参考以下调试视图:

但是当我们使用 http://localhost:8080/hi1/xiao/ming 来访问时,AntPathMatcher 执行的结果是"/hi1/xiao/ming"匹配不上"/hi1/{name}"。
- 根据匹配情况返回结果
如果找到匹配的方法,则返回方法;如果没有,则返回 null。
在本案例中,http://localhost:8080/hi1/xiao/ming 因为找不到匹配方法最终报 404 错误。追根溯源就是 AntPathMatcher 匹配不了"/hi1/xiao/ming"和"/hi1/{name}"。
另外,我们再回头思考 http://localhost:8080/hi1/xiaoming/ 为什么没有报错而是直接去掉了 /。这里我直接贴出了负责执行 AntPathMatcher 匹配的 PatternsRequestCondition#getMatchingPattern 方法的部分关键代码:
private String getMatchingPattern(String pattern, String lookupPath) {
//省略其他非关键代码
if (this.pathMatcher.match(pattern, lookupPath)) {
return pattern;
}
//尝试加一个/来匹配
if (this.useTrailingSlashMatch) {
if (!pattern.endsWith("/") && this.pathMatcher.match(pattern + "/", lookupPath)) {
return pattern + "/";
}
}
return null;
}
在这段代码中,AntPathMatcher 匹配不了"/hi1/xiaoming/“和”/hi1/{name}",所以不会直接返回。进而,在 useTrailingSlashMatch 这个参数启用时(默认启用),会把 Pattern 结尾加上 / 再尝试匹配一次。如果能匹配上,在最终返回 Pattern 时就隐式自动加 /。
很明显,我们的案例符合这种情况,等于说我们最终是用了"/hi1/{name}/“这个 Pattern,而不再是”/hi1/{name}"。所以自然 URL 解析 name 结果是去掉 / 的。
问题修正
针对这个案例,有了源码的剖析,我们可能会想到可以先用"**“匹配上路径,等进入方法后再尝试去解析,这样就可以万无一失吧。具体修改代码如下:
@RequestMapping(path = "/hi1/**", method = RequestMethod.GET)
public String hi1(HttpServletRequest request){
String requestURI = request.getRequestURI();
return requestURI.split("/hi1/")[1];
};
但是这种修改方法还是存在漏洞,假设我们路径的 name 中刚好又含有”/hi1/",则 split 后返回的值就并不是我们想要的。实际上,更合适的修订代码示例如下:
private AntPathMatcher antPathMatcher = new AntPathMatcher();
@RequestMapping(path = "/hi1/**", method = RequestMethod.GET)
public String hi1(HttpServletRequest request){
String path = (String) request.getAttribute(HandlerMapping.PATH_WITHIN_HANDLER_MAPPING_ATTRIBUTE);
//matchPattern 即为"/hi1/**"
String matchPattern = (String) request.getAttribute(HandlerMapping.BEST_MATCHING_PATTERN_ATTRIBUTE);
return antPathMatcher.extractPathWithinPattern(matchPattern, path);
};
经过修改,两个错误都得以解决了。当然也存在一些其他的方案,例如对传递的参数进行 URL 编码以避免出现 /,或者干脆直接把这个变量作为请求参数、Header 等,而不是作为 URL 的一部分。你完全可以根据具体情况来选择合适的方案。
案例 2:错误使用 @RequestParam、@PathVarible 等注解
我们常常使用 @RequestParam 和 @PathVarible 来获取请求参数(request parameters)以及 path 中的部分。但是在频繁使用这些参数时,不知道你有没有觉得它们的使用方式并不友好,例如我们去获取一个请求参数 name,我们会定义如下:
@RequestParam("name") String name
此时,我们会发现变量名称大概率会被定义成 RequestParam 值。所以我们是不是可以用下面这种方式来定义:
@RequestParam String name
这种方式确实是可以的,本地测试也能通过。这里我还给出了完整的代码,你可以感受下这两者的区别。
@RequestMapping(path = "/hi1", method = RequestMethod.GET)
public String hi1(@RequestParam("name") String name){
return name;
};
@RequestMapping(path = "/hi2", method = RequestMethod.GET)
public String hi2(@RequestParam String name){
return name;
};
很明显,对于喜欢追究极致简洁的同学来说,这个酷炫的功能是一个福音。但当我们换一个项目时,有可能上线后就失效了,然后报错 500,提示匹配不上。
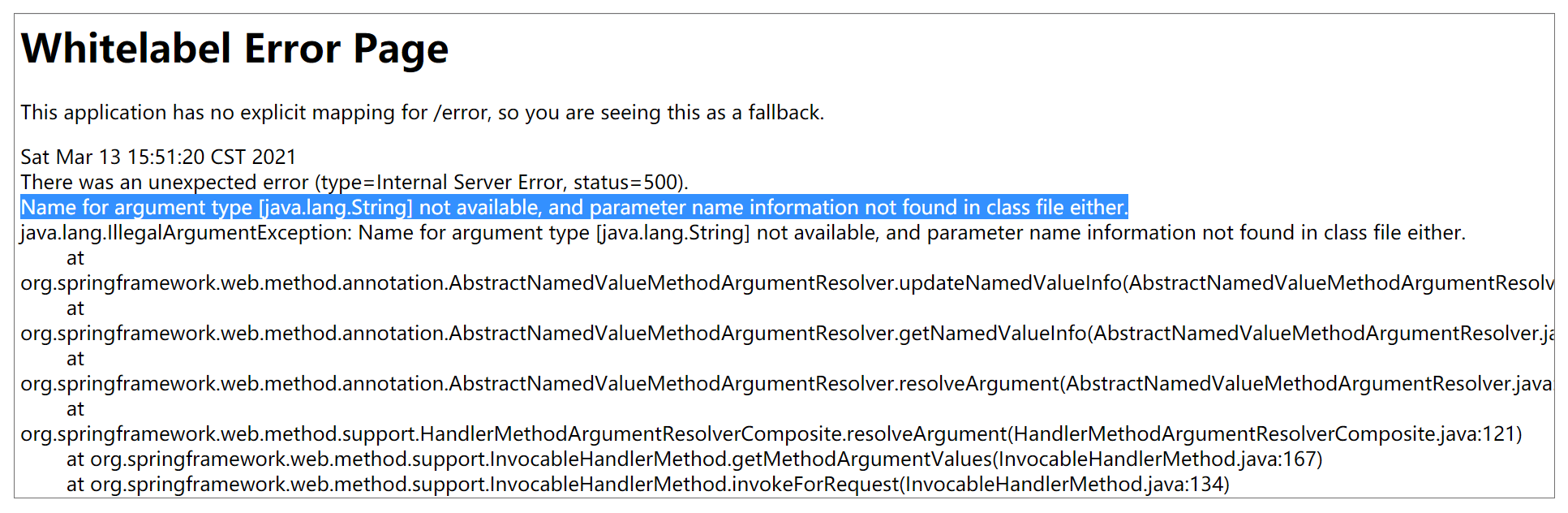
案例解析
要理解这个问题出现的原因,首先我们需要把这个问题复现出来。例如我们可以修改下 pom.xml 来关掉两个选项:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<debug>false</debug>
<parameters>false</parameters>
</configuration>
</plugin>
上述配置显示关闭了 parameters 和 debug,这 2 个参数的作用你可以参考下面的表格:

通过上述描述,我们可以看出这 2 个参数控制了一些 debug 信息是否加进 class 文件中。我们可以开启这两个参数来编译,然后使用下面的命令来查看信息:
javap -verbose HelloWorldController.class
执行完命令后,我们会看到以下 class 信息:
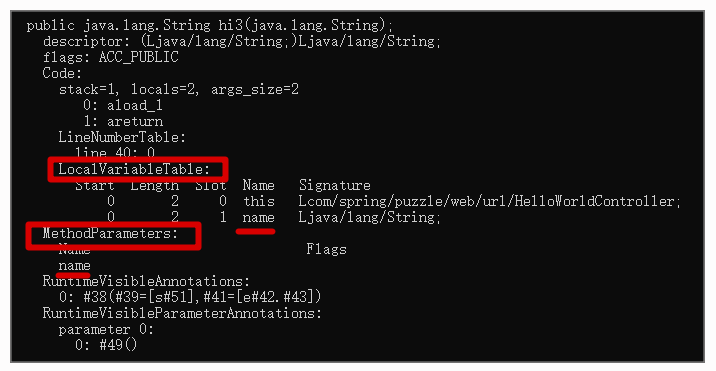
debug 参数开启的部分信息就是 LocalVaribleTable,而 paramters 参数开启的信息就是 MethodParameters。观察它们的信息,你会发现它们都含有参数名 name。
如果你关闭这两个参数,则 name 这个名称自然就没有了。而这个方法本身在 @RequestParam 中又没有指定名称,那么 Spring 此时还能找到解析的方法么?
答案是否定的,这里我们可以顺带说下 Spring 解析请求参数名称的过程,参考代码 AbstractNamedValueMethodArgumentResolver#updateNamedValueInfo:
private NamedValueInfo updateNamedValueInfo(MethodParameter parameter, NamedValueInfo info) {
String name = info.name;
if (info.name.isEmpty()) {
name = parameter.getParameterName();
if (name == null) {
throw new IllegalArgumentException(
"Name for argument type [" + parameter.getNestedParameterType().getName() +
"] not available, and parameter name information not found in class file either.");
}
}
String defaultValue = (ValueConstants.DEFAULT_NONE.equals(info.defaultValue) ? null : info.defaultValue);
return new NamedValueInfo(name, info.required, defaultValue);
}
其中 NamedValueInfo 的 name 为 @RequestParam 指定的值。很明显,在本案例中,为 null。
所以这里我们就会尝试调用 parameter.getParameterName() 来获取参数名作为解析请求参数的名称。但是,很明显,关掉上面两个开关后,就不可能在 class 文件中找到参数名了,这点可以从下面的调试试图中得到验证:
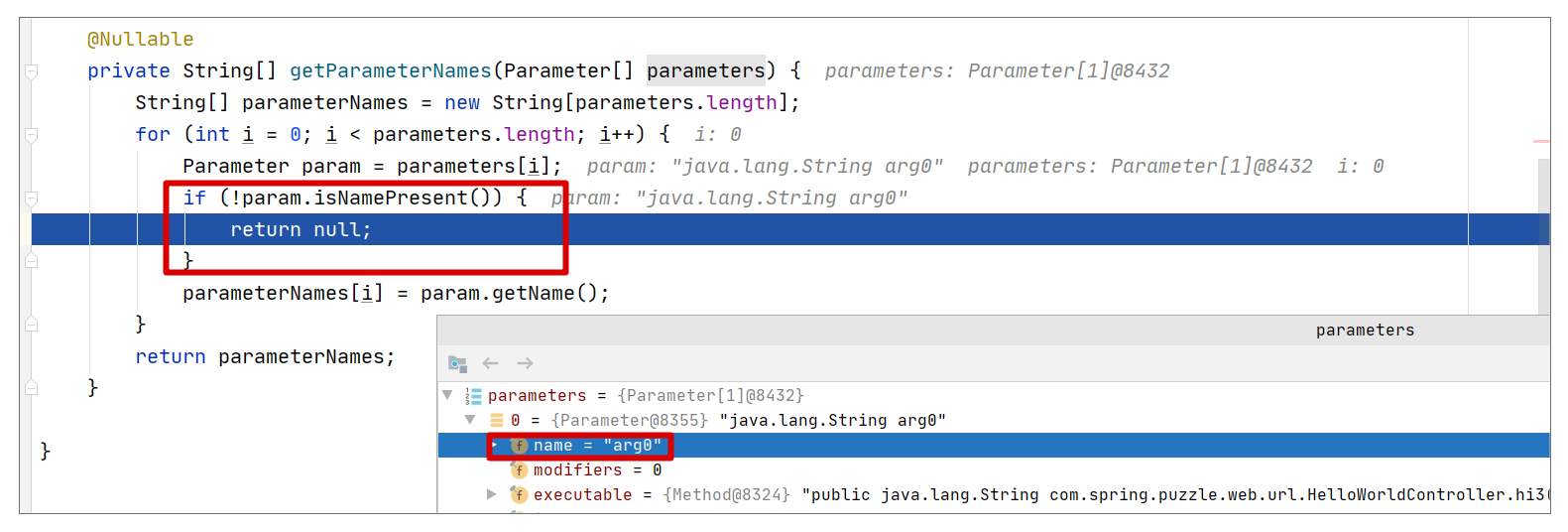
当参数名不存在,@RequestParam 也没有指明,自然就无法决定到底要用什么名称去获取请求参数,所以就会报本案例的错误。
问题修正
模拟出了问题是如何发生的,我们自然可以通过开启这两个参数让其工作起来。但是思考这两个参数的作用,很明显,它可以让我们的程序体积更小,所以很多项目都会青睐去关闭这两个参数。
为了以不变应万变,正确的修正方式是必须显式在 @RequestParam 中指定请求参数名。具体修改如下:
@RequestParam("name") String name
通过这个案例,我们可以看出:很多功能貌似可以永远工作,但是实际上,只是在特定的条件下而已。另外,这里再拓展下,IDE 都喜欢开启相关 debug 参数,所以 IDE 里运行的程序不见得对产线适应,例如针对 parameters 这个参数,IDEA 默认就开启了。
另外,本案例围绕的都是 @RequestParam,其实 @PathVarible 也有一样的问题。这里你要注意。
那么说到这里,我顺带提一个可能出现的小困惑:我们这里讨论的参数,和 @QueryParam、@PathParam 有什么区别?实际上,后者都是 JAX-RS 自身的注解,不需要额外导包。而 @RequestParam 和 @PathVariable 是 Spring 框架中的注解,需要额外导入依赖包。另外不同注解的参数也不完全一致。
案例 3:未考虑参数是否可选
在上面的案例中,我们提到了 @RequestParam 的使用。而对于它的使用,我们常常会遇到另外一个问题。当需要特别多的请求参数时,我们往往会忽略其中一些参数是否可选。例如存在类似这样的代码:
@RequestMapping(path = "/hi4", method = RequestMethod.GET)
public String hi4(@RequestParam("name") String name, @RequestParam("address") String address){
return name + ":" + address;
};
在访问 http://localhost:8080/hi4?name=xiaoming&address=beijing 时并不会出问题,但是一旦用户仅仅使用 name 做请求(即 http://localhost:8080/hi4?name=xiaoming )时,则会直接报错如下:
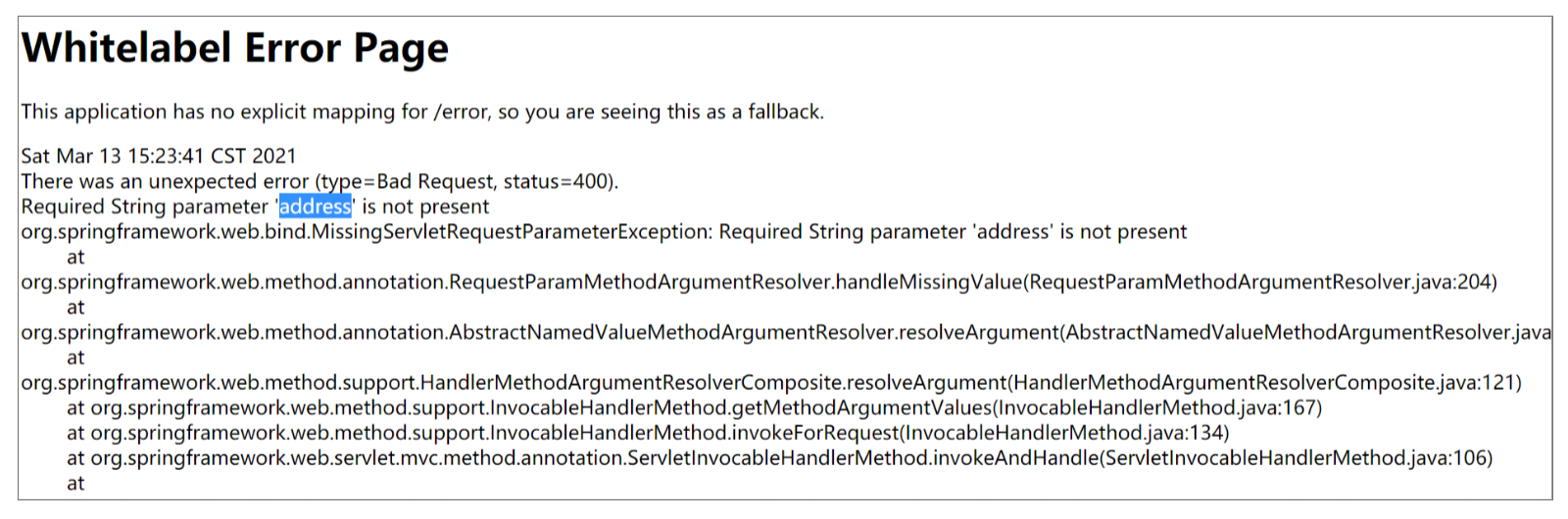
此时,返回错误码 400,提示请求格式错误:此处缺少 address 参数。
实际上,部分初学者即使面对这个错误,也会觉得惊讶,既然不存在 address,address 应该设置为 null,而不应该是直接报错不是么?接下来我们就分析下。
案例解析
要了解这个错误出现的根本原因,你就需要了解请求参数的发生位置。
实际上,这里我们也能按注解名(@RequestParam)来确定解析发生的位置是在 RequestParamMethodArgumentResolver 中。为什么是它?追根溯源,针对当前案例,当根据 URL 匹配上要执行的方法是 hi4 后,要反射调用它,必须解析出方法参数 name 和 address 才可以。而它们被 @RequestParam 注解修饰,所以解析器借助 RequestParamMethodArgumentResolver 就成了很自然的事情。
接下来我们看下 RequestParamMethodArgumentResolver 对参数解析的一些关键操作,参考其父类方法 AbstractNamedValueMethodArgumentResolver#resolveArgument:
public final Object resolveArgument(MethodParameter parameter, @Nullable ModelAndViewContainer mavContainer,
NativeWebRequest webRequest, @Nullable WebDataBinderFactory binderFactory) throws Exception {
NamedValueInfo namedValueInfo = getNamedValueInfo(parameter);
MethodParameter nestedParameter = parameter.nestedIfOptional();
//省略其他非关键代码
//获取请求参数
Object arg = resolveName(resolvedName.toString(), nestedParameter, webRequest);
if (arg == null) {
if (namedValueInfo.defaultValue != null) {
arg = resolveStringValue(namedValueInfo.defaultValue);
}
else if (namedValueInfo.required && !nestedParameter.isOptional()) {
handleMissingValue(namedValueInfo.name, nestedParameter, webRequest);
}
arg = handleNullValue(namedValueInfo.name, arg, nestedParameter.getNestedParameterType());
}
//省略后续代码:类型转化等工作
return arg;
}
如代码所示,当缺少请求参数的时候,通常我们会按照以下几个步骤进行处理。
- 查看 namedValueInfo 的默认值,如果存在则使用它
这个变量实际是通过下面的方法来获取的,参考 RequestParamMethodArgumentResolver#createNamedValueInfo:
@Override
protected NamedValueInfo createNamedValueInfo(MethodParameter parameter) {
RequestParam ann = parameter.getParameterAnnotation(RequestParam.class);
return (ann != null ? new RequestParamNamedValueInfo(ann) : new RequestParamNamedValueInfo());
}
实际上就是 @RequestParam 的相关信息,我们调试下,就可以验证这个结论,具体如下图所示:

- 在 @RequestParam 没有指明默认值时,会查看这个参数是否必须,如果必须,则按错误处理
判断参数是否必须的代码即为下述关键代码行:
namedValueInfo.required && !nestedParameter.isOptional()
很明显,若要判定一个参数是否是必须的,需要同时满足两个条件:条件 1 是 @RequestParam 指明了必须(即属性 required 为 true,实际上它也是默认值),条件 2 是要求 @RequestParam 标记的参数本身不是可选的。
我们可以通过 MethodParameter#isOptional 方法看下可选的具体含义:
public boolean isOptional() {
return (getParameterType() == Optional.class || hasNullableAnnotation() ||
(KotlinDetector.isKotlinReflectPresent() &&
KotlinDetector.isKotlinType(getContainingClass()) &&
KotlinDelegate.isOptional(this)));
}
在不使用 Kotlin 的情况下,所谓可选,就是参数的类型为 Optional,或者任何标记了注解名为 Nullable 且 RetentionPolicy 为 RUNTIM 的注解。
- 如果不是必须,则按 null 去做具体处理
如果接受类型是 boolean,返回 false,如果是基本类型则直接报错,这里不做展开。
结合我们的案例,我们的参数符合步骤 2 中判定为必选的条件,所以最终会执行方法 AbstractNamedValueMethodArgumentResolver#handleMissingValue:
protected void handleMissingValue(String name, MethodParameter parameter) throws ServletException {
throw new ServletRequestBindingException("Missing argument '" + name +
"' for method parameter of type " + parameter.getNestedParameterType().getSimpleName());
}
问题修正
通过案例解析,我们很容易就能修正这个问题,就是让参数有默认值或为非可选即可,具体方法包含以下几种。
- 设置 @RequestParam 的默认值
修改代码如下:
@RequestParam(value = "address", defaultValue = "no address") String address
- 设置 @RequestParam 的 required 值
@RequestParam(value = "address", required = false) String address
- 标记任何名为 Nullable 且 RetentionPolicy 为 RUNTIME 的注解
修改代码如下:
//org.springframework.lang.Nullable 可以
//edu.umd.cs.findbugs.annotations.Nullable 可以
@RequestParam(value = "address") @Nullable String address
- 修改参数类型为 Optional
修改代码如下:
@RequestParam(value = "address") Optionaladdress
从这些修正方法不难看出:假设你不学习源码,解决方法就可能只局限于一两种,但是深入源码后,解决方法就变得格外多了。这里要特别强调的是:在 Spring Web 中,默认情况下,请求参数是必选项。
案例 4:请求参数格式错误
当我们使用 Spring URL 相关的注解,会发现 Spring 是能够完成自动转化的。例如在下面的代码中,age 可以被直接定义为 int 这种基本类型(Integer 也可以),而不是必须是 String 类型。
@RequestMapping(path = "/hi5", method = RequestMethod.GET)
public String hi5(@RequestParam("name") String name, @RequestParam("age") int age){
return name + " is " + age + " years old";
};
鉴于 Spring 的强大转化功能,我们断定 Spring 也支持日期类型的转化(也确实如此),于是我们可能会写出类似下面这样的代码:
@RequestMapping(path = "/hi6", method = RequestMethod.GET)
public String hi6(@RequestParam("Date") Date date){
return "date is " + date ;
};
然后,我们使用一些看似明显符合日期格式的 URL 来访问,例如 http://localhost:8080/hi6?date=2021-5-1 20:26:53,我们会发现 Spring 并不能完成转化,而是报错如下:
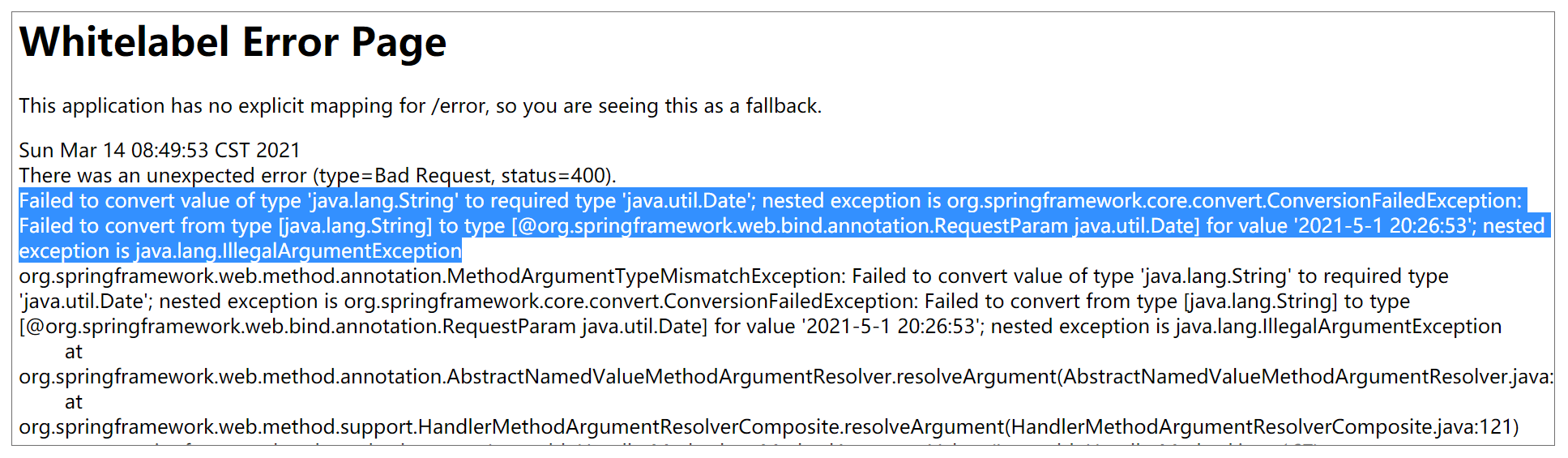
此时,返回错误码 400,错误信息为"Failed to convert value of type ‘java.lang.String’ to required type ‘java.util.Date"。
如何理解这个案例?如果实现自动转化,我们又需要做什么?
案例解析
不管是使用 @PathVarible 还是 @RequetParam,我们一般解析出的结果都是一个 String 或 String 数组。例如,使用 @RequetParam 解析的关键代码参考 RequestParamMethodArgumentResolver#resolveName 方法:
@Nullable
protected Object resolveName(String name, MethodParameter parameter, NativeWebRequest request) throws Exception {
//省略其他非关键代码
if (arg == null) {
String[] paramValues = request.getParameterValues(name);
if (paramValues != null) {
arg = (paramValues.length == 1 ? paramValues[0] : paramValues);
}
}
return arg;
}
这里我们调用的"request.getParameterValues(name)",返回的是一个 String 数组,最终给上层调用者返回的是单个 String(如果只有一个元素时)或者 String 数组。
所以很明显,在这个测试程序中,我们给上层返回的是一个 String,这个 String 的值最终是需要做转化才能赋值给其他类型。例如对于案例中的"int age"定义,是需要转化为 int 基本类型的。这个基本流程可以通过 AbstractNamedValueMethodArgumentResolver#resolveArgument 的关键代码来验证:
public final Object resolveArgument(MethodParameter parameter, @Nullable ModelAndViewContainer mavContainer,
NativeWebRequest webRequest, @Nullable WebDataBinderFactory binderFactory) throws Exception {
//省略其他非关键代码
Object arg = resolveName(resolvedName.toString(), nestedParameter, webRequest);
//以此为界,前面代码为解析请求参数,后续代码为转化解析出的参数
if (binderFactory != null) {
WebDataBinder binder = binderFactory.createBinder(webRequest, null, namedValueInfo.name);
try {
arg = binder.convertIfNecessary(arg, parameter.getParameterType(), parameter);
}
//省略其他非关键代码
}
//省略其他非关键代码
return arg;
}
在这里你只需要回忆出它是需要根据源类型和目标类型寻找转化器来执行转化的。在这里,对于 age 而言,最终找出的转化器是 StringToNumberConverterFactory。而对于 Date 型的 Date 变量,在本案例中,最终找到的是 ObjectToObjectConverter。它的转化过程参考下面的代码:
public Object convert(@Nullable Object source, TypeDescriptor sourceType, TypeDescriptor targetType) {
if (source == null) {
return null;
}
Class<?> sourceClass = sourceType.getType();
Class<?> targetClass = targetType.getType();
//根据源类型去获取构建出目标类型的方法:可以是工厂方法(例如 valueOf、from 方法)也可以是构造器
Member member = getValidatedMember(targetClass, sourceClass);
try {
if (member instanceof Method) {
//如果是工厂方法,通过反射创建目标实例
}
else if (member instanceof Constructor) {
//如果是构造器,通过反射创建实例
Constructor<?> ctor = (Constructor<?>) member;
ReflectionUtils.makeAccessible(ctor);
return ctor.newInstance(source);
}
}
catch (InvocationTargetException ex) {
throw new ConversionFailedException(sourceType, targetType, source, ex.getTargetException());
}
catch (Throwable ex) {
throw new ConversionFailedException(sourceType, targetType, source, ex);
}
当使用 ObjectToObjectConverter 进行转化时,是根据反射机制带着源目标类型来查找可能的构造目标实例方法,例如构造器或者工厂方法,然后再次通过反射机制来创建一个目标对象。所以对于 Date 而言,最终调用的是下面的 Date 构造器:
public Date(String s) {
this(parse(s));
}
然而,我们传入的 2021-5-1 20:26:53 虽然确实是一种日期格式,但用来作为 Date 构造器参数是不支持的,最终报错,并被上层捕获,转化为 ConversionFailedException 异常。这就是这个案例背后的故事了。
问题修正
那么怎么解决呢?提供两种方法。
- 使用 Date 支持的格式
例如下面的测试 URL 就可以工作起来:
http://localhost:8080/hi6?date=Sat, 12 Aug 1995 13:30:00 GMT
- 使用好内置格式转化器
实际上,在 Spring 中,要完成 String 对于 Date 的转化,ObjectToObjectConverter 并不是最好的转化器。我们可以使用更强大的 AnnotationParserConverter。在 Spring 初始化时,会构建一些针对日期型的转化器,即相应的一些 AnnotationParserConverter 的实例。但是为什么有时候用不上呢?
这是因为 AnnotationParserConverter 有目标类型的要求,这点我们可以通过调试角度来看下,参考 FormattingConversionService#addFormatterForFieldAnnotation 方法的调试试图:

这是适应于 String 到 Date 类型的转化器 AnnotationParserConverter 实例的构造过程,其需要的 annototationType 参数为 DateTimeFormat。
annototationType 的作用正是为了帮助判断是否能用这个转化器,这一点可以参考代码 AnnotationParserConverter#matches:
@Override
public boolean matches(TypeDescriptor sourceType, TypeDescriptor targetType) {
return targetType.hasAnnotation(this.annotationType);
}
最终构建出来的转化器相关信息可以参考下图:

图中构造出的转化器是可以用来转化 String 到 Date,但是它要求我们标记 @DateTimeFormat。很明显,我们的参数 Date 并没有标记这个注解,所以这里为了使用这个转化器,我们可以使用上它并提供合适的格式。这样就可以让原来不工作的 URL 工作起来,具体修改代码如下:
@DateTimeFormat(pattern="yyyy-MM-dd HH:mm:ss") Date date
以上即为本案例的解决方案。除此之外,我们完全可以制定一个转化器来帮助我们完成转化,这里不再赘述。另外,通过这个案例,我们可以看出:尽管 Spring 给我们提供了很多内置的转化功能,但是我们一定要注意,格式是否符合对应的要求,否则代码就可能会失效。
10 | Spring Web Header 解析常见错误 #
对于一个 HTTP 请求而言,URL 固然重要,但是为了便于用户使用,URL 的长度有限,所能携带的信息也因此受到了制约。
如果想提供更多的信息,Header 往往是不二之举。不言而喻,Header 是介于 URL 和 Body 之外的第二大重要组成,它提供了更多的信息以及围绕这些信息的相关能力,例如 Content-Type 指定了我们的请求或者响应的内容类型,便于我们去做解码。虽然 Spring 对于 Header 的解析,大体流程和 URL 相同,但是 Header 本身具有自己的特点。例如,Header 不像 URL 只能出现在请求中。所以,Header 处理相关的错误和 URL 又不尽相同。接下来我们看看具体的案例。
案例 1:接受 Header 使用错 Map 类型
在 Spring 中解析 Header 时,我们在多数场合中是直接按需解析的。例如,我们想使用一个名为 myHeaderName 的 Header,我们会书写代码如下:
@RequestMapping(path = "/hi", method = RequestMethod.GET)
public String hi(@RequestHeader("myHeaderName") String name){
//省略 body 处理
};
定义一个参数,标记上 @RequestHeader,指定要解析的 Header 名即可。但是假设我们需要解析的 Header 很多时,按照上面的方式很明显会使得参数越来越多。在这种情况下,我们一般都会使用 Map 去把所有的 Header 都接收到,然后直接对 Map 进行处理。于是我们可能会写出下面的代码:
@RequestMapping(path = "/hi1", method = RequestMethod.GET)
public String hi1(@RequestHeader() Map map){
return map.toString();
};
粗略测试程序,你会发现一切都很好。而且上面的代码也符合针对接口编程的范式,即使用了 Map 这个接口类型。但是上面的接口定义在遇到下面的请求时,就会超出预期。请求如下:
GET http://localhost:8080/hi1
myheader: h1
myheader: h2
这里存在一个 Header 名为 myHeader,不过这个 Header 有两个值。此时我们执行请求,会发现返回的结果并不能将这两个值如数返回。结果示例如下:
{myheader=h1, host=localhost:8080, connection=Keep-Alive, user-agent=Apache-HttpClient/4.5.12 (Java/11.0.6), accept-encoding=gzip,deflate}
如何理解这个常见错误及背后原理?接下来我们就具体解析下。
案例解析
实际上,当我们看到这个测试结果,大多数同学已经能反应过来了。对于一个多值的 Header,在实践中,通常有两种方式来实现,一种是采用下面的方式:
Key: value1,value2
而另外一种方式就是我们测试请求中的格式:
Key:value1
Key:value2
对于方式 1,我们使用 Map 接口自然不成问题。但是如果使用的是方式 2,我们就不能拿到所有的值。这里我们可以翻阅代码查下 Map 是如何接收到所有请求的。
对于一个 Header 的解析,主要有两种方式,分别实现在 RequestHeaderMethodArgumentResolver 和 RequestHeaderMapMethodArgumentResolver 中,它们都继承于 AbstractNamedValueMethodArgumentResolver,但是应用的场景不同,我们可以对比下它们的 supportsParameter(),来对比它们适合的场景:

在上图中,左边是 RequestHeaderMapMethodArgumentResolver 的方法。通过比较可以发现,对于一个标记了 @RequestHeader 的参数,如果它的类型是 Map,则使用 RequestHeaderMapMethodArgumentResolver,否则一般使用的是 RequestHeaderMethodArgumentResolver。
在我们的案例中,很明显,参数类型定义为 Map,所以使用的自然是 RequestHeaderMapMethodArgumentResolver。接下来,我们继续查看它是如何解析 Header 的,关键代码参考 resolveArgument():
@Override
public Object resolveArgument(MethodParameter parameter, @Nullable ModelAndViewContainer mavContainer,
NativeWebRequest webRequest, @Nullable WebDataBinderFactory binderFactory) throws Exception {
Class<?> paramType = parameter.getParameterType();
if (MultiValueMap.class.isAssignableFrom(paramType)) {
MultiValueMap<String, String> result;
if (HttpHeaders.class.isAssignableFrom(paramType)) {
result = new HttpHeaders();
}
else {
result = new LinkedMultiValueMap<>();
}
for (Iterator<String> iterator = webRequest.getHeaderNames(); iterator.hasNext();) {
String headerName = iterator.next();
String[] headerValues = webRequest.getHeaderValues(headerName);
if (headerValues != null) {
for (String headerValue : headerValues) {
result.add(headerName, headerValue);
}
}
}
return result;
}
else {
Map<String, String> result = new LinkedHashMap<>();
for (Iterator<String> iterator = webRequest.getHeaderNames(); iterator.hasNext();) {
String headerName = iterator.next();
//只取了一个“值”
String headerValue = webRequest.getHeader(headerName);
if (headerValue != null) {
result.put(headerName, headerValue);
}
}
return result;
}
}
针对我们的案例,这里并不是 MultiValueMap,所以我们会走入 else 分支。这个分支首先会定义一个 LinkedHashMap,然后将请求一一放置进去,并返回。其中第 29 行是去解析获取 Header 值的实际调用,在不同的容器下实现不同。例如在 Tomcat 容器下,它的执行方法参考 MimeHeaders#getValue:
public MessageBytes getValue(String name) {
for (int i = 0; i < count; i++) {
if (headers[i].getName().equalsIgnoreCase(name)) {
return headers[i].getValue();
}
}
return null;
}
当一个请求出现多个同名 Header 时,我们只要匹配上任何一个即立马返回。所以在本案例中,只返回了一个 Header 的值。
其实换一个角度思考这个问题,毕竟前面已经定义的接收类型是 LinkedHashMap,它的 Value 的泛型类型是 String,也不适合去组织多个值的情况。综上,不管是结合代码还是常识,本案例的代码都不能获取到 myHeader 的所有值。
问题修正
现在我们要修正这个问题。在案例解析部分,其实我已经给出了答案。
在 RequestHeaderMapMethodArgumentResolver 的 resolveArgument() 中,假设我们的参数类型是 MultiValueMap,我们一般会创建一个 LinkedMultiValueMap,然后使用下面的语句来获取 Header 的值并添加到 Map 中去:
String[] headerValues = webRequest.getHeaderValues(headerName)
参考上面的语句,不用细究,我们也能看出,我们是可以获取多个 Header 值的。另外假设我们定义的是 HttpHeaders(也是一种 MultiValueMap),我们会直接创建一个 HttpHeaders 来存储所有的 Header。
有了上面的解析,我们可以得出这样一个结论:要完整接收到所有的 Header,不能直接使用 Map 而应该使用 MultiValueMap。我们可以采用以下两种方式来修正这个问题:
//方式 1
@RequestHeader() MultiValueMap map
//方式 2
@RequestHeader() HttpHeaders map
重新运行测试,你会发现结果符合预期:
[myheader:"h1", "h2", host:"localhost:8080", connection:"Keep-Alive", user-agent:"Apache-HttpClient/4.5.12 (Java/11.0.6)", accept-encoding:"gzip,deflate"]
对比来说,方式 2 更值得推荐,因为它使用了大多数人常用的 Header 获取方法,例如获取 Content-Type 直接调用它的 getContentType() 即可,诸如此类,非常好用。
反思这个案例,我们为什么会犯这种错误呢?追根溯源,还是在于我们很少看到一个 Header 有多个值的情况,从而让我们疏忽地用错了接收类型。
案例 2:错认为 Header 名称首字母可以一直忽略大小写
在 HTTP 协议中,Header 的名称是无所谓大小写的。在使用各种框架构建 Web 时,我们都会把这个事实铭记于心。我们可以验证下这个想法。例如,我们有一个 Web 服务接口如下:
@RequestMapping(path = "/hi2", method = RequestMethod.GET)
public String hi2(@RequestHeader("MyHeader") String myHeader){
return myHeader;
};
然后,我们使用下面的请求来测试这个接口是可以获取到对应的值的:
GET http://localhost:8080/hi2
myheader: myheadervalue
另外,结合案例 1,我们知道可以使用 Map 来接收所有的 Header,那么这种方式下是否也可以忽略大小写呢?这里我们不妨使用下面的代码来比较下:
@RequestMapping(path = "/hi2", method = RequestMethod.GET)
public String hi2(@RequestHeader("MyHeader") String myHeader, @RequestHeader MultiValueMap map){
return myHeader + " compare with : " + map.get("MyHeader");
};
再次运行之前的测试请求,我们得出下面的结果:
myheadervalue compare with : null
综合来看,直接获取 Header 是可以忽略大小写的,但是如果从接收过来的 Map 中获取 Header 是不能忽略大小写的。稍微不注意,我们就很容易认为 Header 在任何情况下,都可以不区分大小写来获取值。
那么针对这个案例,如何去理解?
案例解析
我们知道,对于"@RequestHeader(“MyHeader”) String myHeader"的定义,Spring 使用的是 RequestHeaderMethodArgumentResolver 来做解析。解析的方法参考 RequestHeaderMethodArgumentResolver#resolveName:
protected Object resolveName(String name, MethodParameter parameter, NativeWebRequest request) throws Exception {
String[] headerValues = request.getHeaderValues(name);
if (headerValues != null) {
return (headerValues.length == 1 ? headerValues[0] : headerValues);
}
else {
return null;
}
}
从上述方法的关键调用"request.getHeaderValues(name)“去按图索骥,我们可以找到查找 Header 的最根本方法,即 org.apache.tomcat.util.http.ValuesEnumerator#findNext:
private void findNext() {
next=null;
for(; pos< size; pos++ ) {
MessageBytes n1=headers.getName( pos );
if( n1.equalsIgnoreCase( name )) {
next=headers.getValue( pos );
break;
}
}
pos++;
}
在上述方法中,name 即为查询的 Header 名称,可以看出这里是忽略大小写的。
而如果我们用 Map 来接收所有的 Header,我们来看下这个 Map 最后存取的 Header 和获取的方法有没有忽略大小写。
有了案例 1 的解析,针对当前的类似案例,结合具体的代码,我们很容易得出下面两个结论。
- 存取 Map 的 Header 是没有忽略大小写的
参考案例 1 解析部分贴出的代码,可以看出,在存取 Header 时,需要的 key 是遍历 webRequest.getHeaderNames() 的返回结果。而这个方法的执行过程参考 org.apache.tomcat.util.http.NamesEnumerator#findNext:
private void findNext() {
next=null;
for(; pos< size; pos++ ) {
next=headers.getName( pos ).toString();
for( int j=0; j<pos ; j++ ) {
if( headers.getName( j ).equalsIgnoreCase( next )) {
// duplicate.
next=null;
break;
}
}
if( next!=null ) {
// it's not a duplicate
break;
}
}
// next time findNext is called it will try the
// next element
pos++;
}
这里,返回结果并没有针对 Header 的名称做任何大小写忽略或转化工作。
- 从 Map 中获取的 Header 也没有忽略大小写
这点可以从返回是 LinkedHashMap 类型看出,LinkedHashMap 的 get() 未忽略大小写。
接下来我们看下怎么解决。
问题修正
就从接收类型 Map 中获取 Header 时注意下大小写就可以了,修正代码如下:
@RequestMapping(path = "/hi2", method = RequestMethod.GET)
public String hi2(@RequestHeader("MyHeader") String myHeader, @RequestHeader MultiValueMap map){
return myHeader + " compare with : " + map.get("myHeader");
};
另外,你可以思考一个问题,如果我们使用 HTTP Headers 来接收请求,那么从它里面获取 Header 是否可以忽略大小写呢?
这点你可以通过它的构造器推测出来,其构造器代码如下:
public HttpHeaders() {
this(CollectionUtils.toMultiValueMap(new LinkedCaseInsensitiveMap<>(8, Locale.ENGLISH)));
}
可以看出,它使用的是 LinkedCaseInsensitiveMap,而不是普通的 LinkedHashMap。所以这里是可以忽略大小写的,我们不妨这样修正:
@RequestMapping(path = "/hi2", method = RequestMethod.GET)
public String hi2(@RequestHeader("MyHeader") String myHeader, @RequestHeader HttpHeaders map){
return myHeader + " compare with : " + map.get("MyHeader");
};
再运行下程序,结果已经符合我们的预期了:
myheadervalue compare with : [myheadervalue]
通过这个案例,我们可以看出:在实际使用时,虽然 HTTP 协议规范可以忽略大小写,但是不是所有框架提供的接口方法都是可以忽略大小写的。这点你一定要注意!
案例 3:试图在 Controller 中随意自定义 CONTENT_TYPE 等
和开头我们提到的 Header 和 URL 不同,Header 可以出现在返回中。正因为如此,一些应用会试图去定制一些 Header 去处理。例如使用 Spring Boot 基于 Tomcat 内置容器的开发中,存在下面这样一段代码去设置两个 Header,其中一个是常用的 CONTENT_TYPE,另外一个是自定义的,命名为 myHeader。
@RequestMapping(path = "/hi3", method = RequestMethod.GET)
public String hi3(HttpServletResponse httpServletResponse){
httpServletResponse.addHeader("myheader", "myheadervalue");
httpServletResponse.addHeader(HttpHeaders.CONTENT_TYPE, "application/json");
return "ok";
};
运行程序测试下(访问 GET http://localhost:8080/hi3 ),我们会得到如下结果:
GET http://localhost:8080/hi3
HTTP/1.1 200
myheader: myheadervalue
Content-Type: text/plain;charset=UTF-8
Content-Length: 2
Date: Wed, 17 Mar 2021 08:59:56 GMT
Keep-Alive: timeout=60
Connection: keep-alive
可以看到 myHeader 设置成功了,但是 Content-Type 并没有设置成我们想要的"application/json”,而是"text/plain;charset=UTF-8"。为什么会出现这种错误?
案例解析
首先我们来看下在 Spring Boot 使用内嵌 Tomcat 容器时,尝试添加 Header 会执行哪些关键步骤。
第一步我们可以查看 org.apache.catalina.connector.Response#addHeader 方法,代码如下:
private void addHeader(String name, String value, Charset charset) {
//省略其他非关键代码
char cc=name.charAt(0);
if (cc=='C' || cc=='c') {
//判断是不是 Content-Type,如果是不要把这个 Header 作为 header 添加到 org.apache.coyote.Response
if (checkSpecialHeader(name, value))
return;
}
getCoyoteResponse().addHeader(name, value, charset);
}
参考代码及注释,正常添加一个 Header 是可以添加到 Header 集里面去的,但是如果这是一个 Content-Type,则事情会变得不一样。它并不会如此做,而是去做另外一件事,即通过 Response#checkSpecialHeader 的调用来设置 org.apache.coyote.Response#contentType 为 application/json,关键代码如下:
private boolean checkSpecialHeader(String name, String value) {
if (name.equalsIgnoreCase("Content-Type")) {
setContentType(value);
return true;
}
return false;
}
最终我们获取到的 Response 如下:
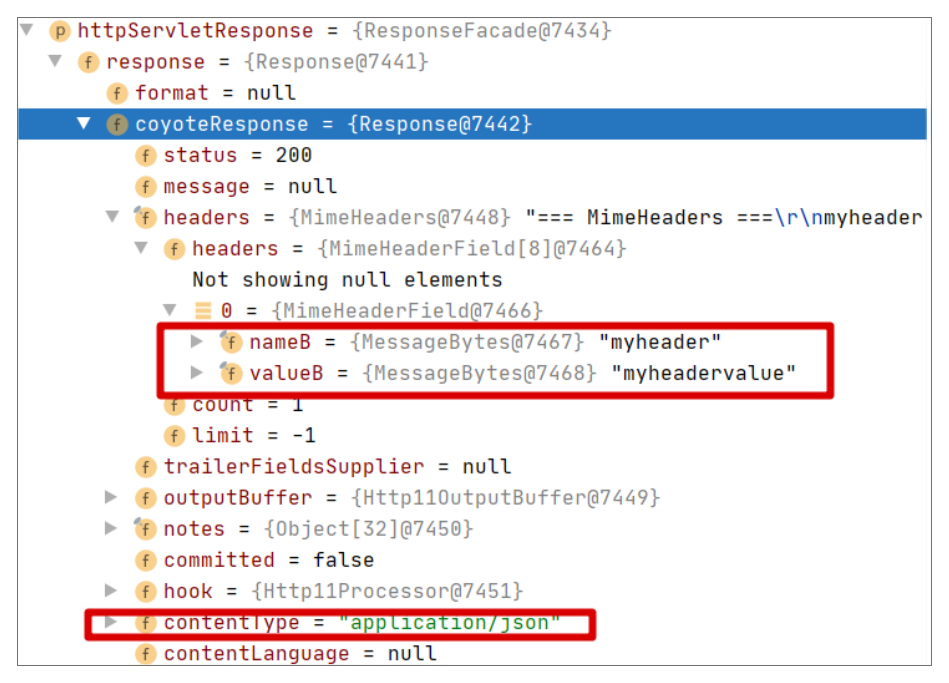
从上图可以看出,Headers 里并没有 Content-Type,而我们设置的 Content-Type 已经作为 coyoteResponse 成员的值了。当然也不意味着后面一定不会返回,我们可以继续跟踪后续执行。
在案例代码返回 ok 后,我们需要对返回结果进行处理,执行方法为 RequestResponseBodyMethodProcessor#handleReturnValue,关键代码如下:
@Override
public void handleReturnValue(@Nullable Object returnValue, MethodParameter returnType,
ModelAndViewContainer mavContainer, NativeWebRequest webRequest)
throws IOException, HttpMediaTypeNotAcceptableException, HttpMessageNotWritableException {
mavContainer.setRequestHandled(true);
ServletServerHttpRequest inputMessage = createInputMessage(webRequest);
ServletServerHttpResponse outputMessage = createOutputMessage(webRequest);
//对返回值(案例中为“ok”)根据返回类型做编码转化处理
writeWithMessageConverters(returnValue, returnType, inputMessage, outputMessage);
}
而在上述代码的调用中,writeWithMessageConverters 会根据返回值及类型做转化,同时也会做一些额外的事情。它的一些关键实现步骤参考下面几步:
- 决定用哪一种 MediaType 返回
参考下面的关键代码:
//决策返回值是何种 MediaType
MediaType selectedMediaType = null;
MediaType contentType = outputMessage.getHeaders().getContentType();
boolean isContentTypePreset = contentType != null && contentType.isConcrete();
//如果 header 中有 contentType,则用其作为选择的 selectedMediaType。
if (isContentTypePreset) {
selectedMediaType = contentType;
}
//没有,则根据“Accept”头、返回值等核算用哪一种
else {
HttpServletRequest request = inputMessage.getServletRequest();
List<MediaType> acceptableTypes = getAcceptableMediaTypes(request);
List<MediaType> producibleTypes = getProducibleMediaTypes(request, valueType, targetType);
//省略其他非关键代码
List<MediaType> mediaTypesToUse = new ArrayList<>();
for (MediaType requestedType : acceptableTypes) {
for (MediaType producibleType : producibleTypes) {
if (requestedType.isCompatibleWith(producibleType)) {
mediaTypesToUse.add(getMostSpecificMediaType(requestedType, producibleType));
}
}
}
//省略其他关键代码
for (MediaType mediaType : mediaTypesToUse) {
if (mediaType.isConcrete()) {
selectedMediaType = mediaType;
break;
}
//省略其他关键代码
}
这里我解释一下,上述代码是先根据是否具有 Content-Type 头来决定返回的 MediaType,通过前面的分析它是一种特殊的 Header,在 Controller 层并没有被添加到 Header 中去,所以在这里只能根据返回的类型、请求的 Accept 等信息协商出最终用哪种 MediaType。
实际上这里最终使用的是 MediaType#TEXT_PLAIN。这里还需要补充说明下,没有选择 JSON 是因为在都支持的情况下,TEXT_PLAIN 默认优先级更高,参考代码 WebMvcConfigurationSupport#addDefaultHttpMessageConverters 可以看出转化器是有优先顺序的,所以用上述代码中的 getProducibleMediaTypes() 遍历 Converter 来收集可用 MediaType 也是有顺序的。
- 选择消息转化器并完成转化
决定完 MediaType 信息后,即可去选择转化器并执行转化,关键代码如下:
for (HttpMessageConverter<?> converter : this.messageConverters) {
GenericHttpMessageConverter genericConverter = (converter instanceof GenericHttpMessageConverter ?
(GenericHttpMessageConverter<?>) converter : null);
if (genericConverter != null ?
((GenericHttpMessageConverter) converter).canWrite(targetType, valueType, selectedMediaType) :
converter.canWrite(valueType, selectedMediaType)) {
//省略其他非关键代码
if (body != null) {
//省略其他非关键代码
if (genericConverter != null) {
genericConverter.write(body, targetType, selectedMediaType, outputMessage);
}
else {
((HttpMessageConverter) converter).write(body, selectedMediaType, outputMessage);
}
}
//省略其他非关键代码
}
}
如代码所示,即结合 targetType(String)、valueType(String)、selectedMediaType(MediaType#TEXT_PLAIN)三个信息来决策可以使用哪种消息 Converter。常见候选 Converter 可以参考下图:
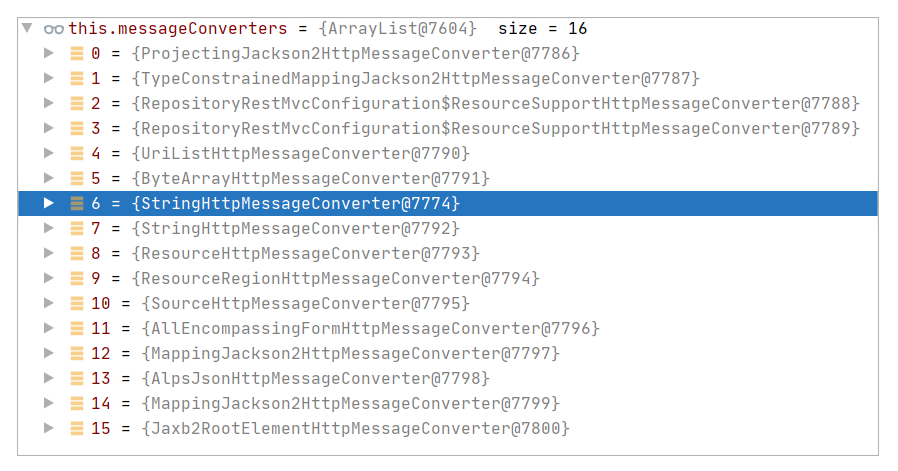
最终,本案例选择的是 StringHttpMessageConverter,在最终调用父类方法 AbstractHttpMessageConverter#write 执行转化时,会尝试添加 Content-Type。具体代码参考 AbstractHttpMessageConverter#addDefaultHeaders:
protected void addDefaultHeaders(HttpHeaders headers, T t, @Nullable MediaType contentType) throws IOException {
if (headers.getContentType() == null) {
MediaType contentTypeToUse = contentType;
if (contentType == null || contentType.isWildcardType() || contentType.isWildcardSubtype()) {
contentTypeToUse = getDefaultContentType(t);
}
else if (MediaType.APPLICATION_OCTET_STREAM.equals(contentType)) {
MediaType mediaType = getDefaultContentType(t);
contentTypeToUse = (mediaType != null ? mediaType : contentTypeToUse);
}
if (contentTypeToUse != null) {
if (contentTypeToUse.getCharset() == null) {
//尝试添加字符集
Charset defaultCharset = getDefaultCharset();
if (defaultCharset != null) {
contentTypeToUse = new MediaType(contentTypeToUse, defaultCharset);
}
}
headers.setContentType(contentTypeToUse);
}
}
//省略其他非关键代码
}
结合案例,参考代码,我们可以看出,我们使用的是 MediaType#TEXT_PLAIN 作为 Content-Type 的 Header,毕竟之前我们添加 Content-Type 这个 Header 并没有成功。最终运行结果也就不出意外了,即"Content-Type: text/plain;charset=UTF-8"。
通过案例分析可以总结出,虽然我们在 Controller 设置了 Content-Type,但是它是一种特殊的 Header,所以在 Spring Boot 基于内嵌 Tomcat 开发时并不一定能设置成功,最终返回的 Content-Type 是根据实际的返回值及类型等多个因素来决定的。
问题修正
针对这个问题,如果想设置成功,我们就必须让其真正的返回就是 JSON 类型,这样才能刚好生效。而且从上面的分析也可以看出,返回符合预期也并非是在 Controller 设置的功劳。不过围绕目标,我们也可以这样去修改下:
- 修改请求中的 Accept 头,约束返回类型
参考代码如下:
GET http://localhost:8080/hi3
Accept:application/json
即带上 Accept 头,这样服务器在最终决定 MediaType 时,会选择 Accept 的值。具体执行可参考方法 AbstractMessageConverterMethodProcessor#getAcceptableMediaTypes。
- 标记返回类型
主动显式指明类型,修改方法如下:
@RequestMapping(path = "/hi3", method = RequestMethod.GET, produces = {"application/json"})
即使用 produces 属性来指明即可。这样的方式影响的是可以返回的 Media 类型,一旦设置,下面的方法就可以只返回一个指明的类型了。参考 AbstractMessageConverterMethodProcessor#getProducibleMediaTypes:
protected List<MediaType> getProducibleMediaTypes(
HttpServletRequest request, Class<?> valueClass, @Nullable Type targetType) {
Set<MediaType> mediaTypes =
(Set<MediaType>) request.getAttribute(HandlerMapping.PRODUCIBLE_MEDIA_TYPES_ATTRIBUTE);
if (!CollectionUtils.isEmpty(mediaTypes)) {
return new ArrayList<>(mediaTypes);
}
//省略其他非关键代码
}
上述两种方式,一个修改了 getAcceptableMediaTypes 返回值,一个修改了 getProducibleMediaTypes,这样就可以控制最终协商的结果为 JSON 了。从而影响后续的执行结果。
不过这里需要额外注意的是,虽然我们最终结果返回的 Content-Type 头是 JSON 了,但是对于内容的加工,仍然采用的是 StringHttpMessageConverter,感兴趣的话你可以自己去研究下原因。
11 | Spring Web Body 转化常见错误 #
在 Spring 中,对于 Body 的处理很多是借助第三方编解码器来完成的。例如常见的 JSON 解析,Spring 都是借助于 Jackson、Gson 等常见工具来完成。所以在 Body 处理中,我们遇到的很多错误都是第三方工具使用中的一些问题。
真正对于 Spring 而言,错误并不多,特别是 Spring Boot 的自动包装以及对常见问题的不断完善,让我们能犯的错误已经很少了。不过,毕竟不是每个项目都是直接基于 Spring Boot 的,所以还是会存在一些问题,接下来我们就一起梳理下。
案例 1:No converter found for return value of type
在直接用 Spring MVC 而非 Spring Boot 来编写 Web 程序时,我们基本都会遇到 “No converter found for return value of type” 这种错误。实际上,我们编写的代码都非常简单,例如下面这段代码:
//定义的数据对象
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Student {
private String name;
private Integer age;
}
//定义的 API 借口
@RestController
public class HelloController {
@GetMapping("/hi1")
public Student hi1() {
return new Student("xiaoming", Integer.valueOf(12));
}
}
然后,我们的 pom.xml 文件也都是最基本的必备项,关键配置如下:
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-webmvc</artifactId>
<version>5.2.3.RELEASE</version>
</dependency>
但是当我们运行起程序,执行测试代码,就会报错如下:
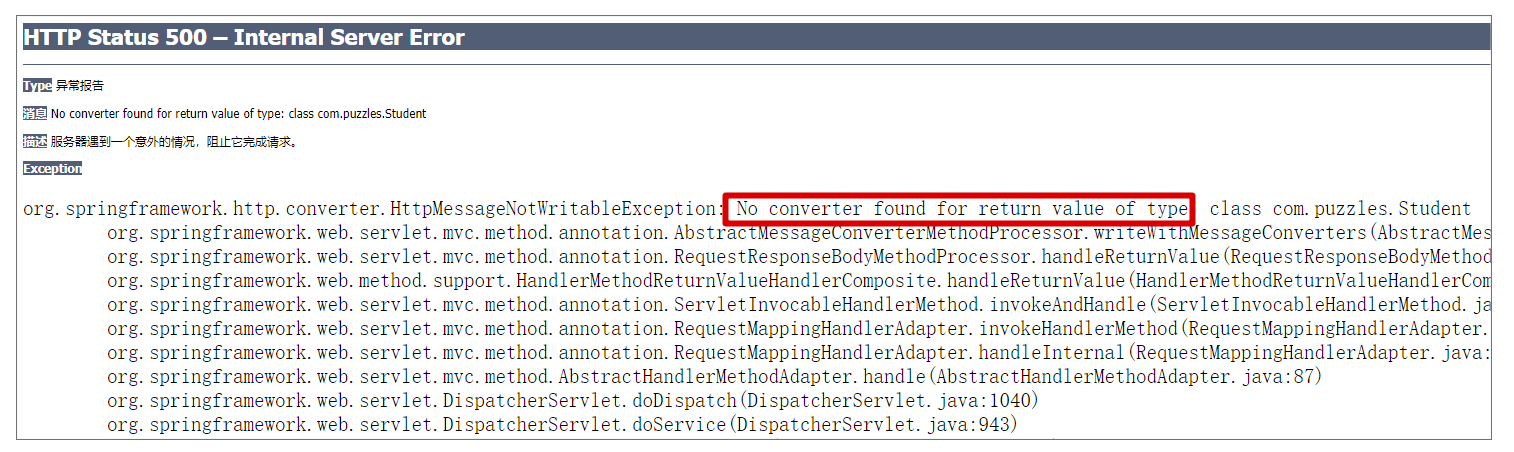
从上述代码及配置来看,并没有什么明显的错误,可为什么会报错呢?难道框架不支持?
案例解析
要了解这个案例出现的原因,需要我们对如何处理响应有一个初步的认识。
当我们的请求到达 Controller 层后,我们获取到了一个对象,即案例中的 new Student(“xiaoming”, Integer.valueOf(12)),那么这个对象应该怎么返回给客户端呢?
用 JSON 还是用 XML,还是其他类型编码?此时就需要一个决策,我们可以先找到这个决策的关键代码所在,参考方法 AbstractMessageConverterMethodProcessor#writeWithMessageConverters:
HttpServletRequest request = inputMessage.getServletRequest();
List<MediaType> acceptableTypes = getAcceptableMediaTypes(request);
List<MediaType> producibleTypes = getProducibleMediaTypes(request, valueType, targetType);
if (body != null && producibleTypes.isEmpty()) {
throw new HttpMessageNotWritableException(
"No converter found for return value of type: " + valueType);
}
List<MediaType> mediaTypesToUse = new ArrayList<>();
for (MediaType requestedType : acceptableTypes) {
for (MediaType producibleType : producibleTypes) {
if (requestedType.isCompatibleWith(producibleType)) {
mediaTypesToUse.add(getMostSpecificMediaType(requestedType, producibleType));
}
}
}
实际上节课我们就贴出过相关代码并分析过,所以这里只是带着你简要分析下上述代码的基本逻辑:
- 查看请求的头中是否有 ACCEPT 头,如果没有则可以使用任何类型;
- 查看当前针对返回类型(即 Student 实例)可以采用的编码类型;
- 取上面两步获取结果的交集来决定用什么方式返回。
比较代码,我们可以看出,假设第 2 步中就没有找到合适的编码方式,则直接报案例中的错误,具体的关键代码行如下:
if (body != null && producibleTypes.isEmpty()) {
throw new HttpMessageNotWritableException(
"No converter found for return value of type: " + valueType);
}
那么当前可采用的编码类型是怎么决策出来的呢?我们可以进一步查看方法 AbstractMessageConverterMethodProcessor#getProducibleMediaTypes:
protected List<MediaType> getProducibleMediaTypes(
HttpServletRequest request, Class<?> valueClass, @Nullable Type targetType) {
Set<MediaType> mediaTypes =
(Set<MediaType>) request.getAttribute(HandlerMapping.PRODUCIBLE_MEDIA_TYPES_ATTRIBUTE);
if (!CollectionUtils.isEmpty(mediaTypes)) {
return new ArrayList<>(mediaTypes);
}
else if (!this.allSupportedMediaTypes.isEmpty()) {
List<MediaType> result = new ArrayList<>();
for (HttpMessageConverter<?> converter : this.messageConverters) {
if (converter instanceof GenericHttpMessageConverter && targetType != null) {
if (((GenericHttpMessageConverter<?>) converter).canWrite(targetType, valueClass, null)) {
result.addAll(converter.getSupportedMediaTypes());
}
}
else if (converter.canWrite(valueClass, null)) {
result.addAll(converter.getSupportedMediaTypes());
}
}
return result;
}
else {
return Collections.singletonList(MediaType.ALL);
}
}
假设当前没有显式指定返回类型(例如给 GetMapping 指定 produces 属性),那么则会遍历所有已经注册的 HttpMessageConverter 查看是否支持当前类型,从而最终返回所有支持的类型。那么这些 MessageConverter 是怎么注册过来的?
在 Spring MVC(非 Spring Boot)启动后,我们都会构建 RequestMappingHandlerAdapter 类型的 Bean 来负责路由和处理请求。
具体而言,当我们使用 时,我们会通过 AnnotationDrivenBeanDefinitionParser 来构建这个 Bean。而在它的构建过程中,会决策出以后要使用哪些 HttpMessageConverter,相关代码参考 AnnotationDrivenBeanDefinitionParser#getMessageConverters:
messageConverters.add(createConverterDefinition(ByteArrayHttpMessageConverter.class, source));
RootBeanDefinition stringConverterDef = createConverterDefinition(StringHttpMessageConverter.class, source);
stringConverterDef.getPropertyValues().add("writeAcceptCharset", false);
messageConverters.add(stringConverterDef);
messageConverters.add(createConverterDefinition(ResourceHttpMessageConverter.class, source));
//省略其他非关键代码
if (jackson2Present) {
Class<?> type = MappingJackson2HttpMessageConverter.class;
RootBeanDefinition jacksonConverterDef = createConverterDefinition(type, source);
GenericBeanDefinition jacksonFactoryDef = createObjectMapperFactoryDefinition(source);
jacksonConverterDef.getConstructorArgumentValues().addIndexedArgumentValue(0, jacksonFactoryDef);
messageConverters.add(jacksonConverterDef);
}
else if (gsonPresent) { messageConverters.add(createConverterDefinition(GsonHttpMessageConverter.class, source));
}
//省略其他非关键代码
这里我们会默认使用一些编解码器,例如 StringHttpMessageConverter,但是像 JSON、XML 等类型,若要加载编解码,则需要 jackson2Present、gsonPresent 等变量为 true。
这里我们可以选取 gsonPresent 看下何时为 true,参考下面的关键代码行:
gsonPresent = ClassUtils.isPresent(“com.google.gson.Gson”, classLoader);
假设我们依赖了 Gson 包,我们就可以添加上 GsonHttpMessageConverter 这种转化器。但是可惜的是,我们的案例并没有依赖上任何 JSON 的库,所以最终在候选的转换器列表里,并不存在 JSON 相关的转化器。最终候选列表示例如下:
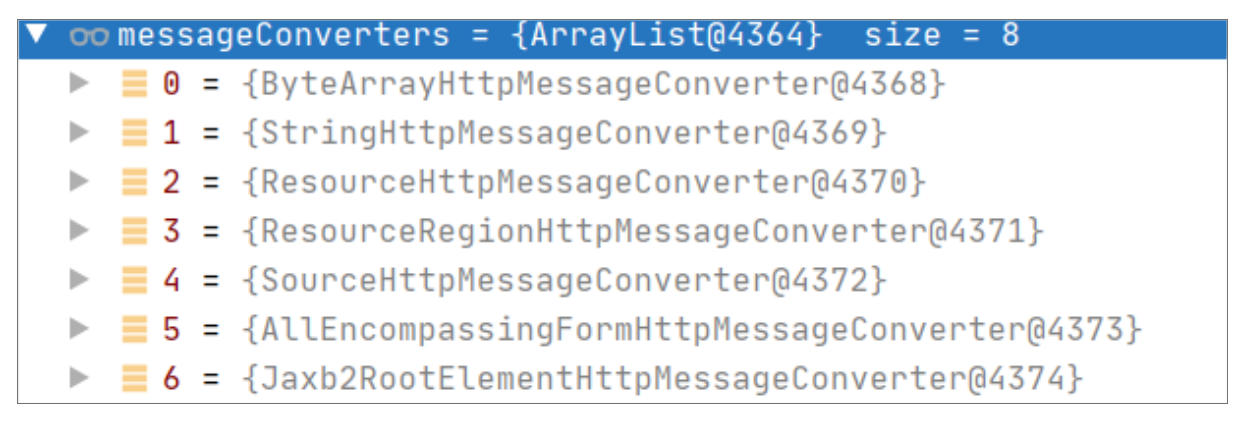
由此可见,并没有任何 JSON 相关的编解码器。而针对 Student 类型的返回对象,上面的这些编解码器又不符合要求,所以最终走入了下面的代码行:
if (body != null && producibleTypes.isEmpty()) {
throw new HttpMessageNotWritableException(
"No converter found for return value of type: " + valueType);
}
抛出了 “No converter found for return value of type” 这种错误,结果符合案例中的实际测试情况。
问题修正
针对这个案例,有了源码的剖析,可以看出,不是每种类型的编码器都会与生俱来,而是根据当前项目的依赖情况决定是否支持。要解析 JSON,我们就要依赖相关的包,所以这里我们可以以 Gson 为例修正下这个问题:
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.8.6</version>
</dependency>
我们添加了 Gson 的依赖到 pom.xml。重新运行程序和测试案例,你会发现不再报错了。
另外,这里我们还可以查看下 GsonHttpMessageConverter 这种编码器是如何支持上 Student 这个对象的解析的。
通过这个案例,我们可以知道,Spring 给我们提供了很多好用的功能,但是这些功能交织到一起后,我们就很可能入坑,只有深入了解它的运行方式,才能迅速定位问题并解决问题。
案例 2:变动地返回 Body
案例 1 让我们解决了解析问题,那随着不断实践,我们可能还会发现在代码并未改动的情况下,返回结果不再和之前相同了。例如我们看下这段代码:
@RestController
public class HelloController {
@PostMapping("/hi2")
public Student hi2(@RequestBody Student student) {
return student;
}
}
上述代码接受了一个 Student 对象,然后原样返回。我们使用下面的测试请求进行测试:
POST http://localhost:8080/springmvc3_war/app/hi2
Content-Type: application/json
{
“name”: “xiaoming”
}
经过测试,我们会得到以下结果:
{
“name”: “xiaoming”
}
但是随着项目的推进,在代码并未改变时,我们可能会返回以下结果:
{
“name”: “xiaoming”,
“age”: null
}
即当 age 取不到值,开始并没有序列化它作为响应 Body 的一部分,后来又序列化成 null 作为 Body 返回了。
在什么情况下会如此?如何规避这个问题,保证我们的返回始终如一。
案例解析
如果我们发现上述问题,那么很有可能是这样一种情况造成的。即在后续的代码开发中,我们直接依赖或者间接依赖了新的 JSON 解析器,例如下面这种方式就依赖了 Jackson:
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.9.6</version>
</dependency>
当存在多个 Jackson 解析器时,我们的 Spring MVC 会使用哪一种呢?这个决定可以参考
if (jackson2Present) {
Class<?> type = MappingJackson2HttpMessageConverter.class;
RootBeanDefinition jacksonConverterDef = createConverterDefinition(type, source);
GenericBeanDefinition jacksonFactoryDef = createObjectMapperFactoryDefinition(source);
jacksonConverterDef.getConstructorArgumentValues().addIndexedArgumentValue(0, jacksonFactoryDef);
messageConverters.add(jacksonConverterDef);
}
else if (gsonPresent) {
messageConverters.add(createConverterDefinition(GsonHttpMessageConverter.class, source));
}
从上述代码可以看出,Jackson 是优先于 Gson 的。所以我们的程序不知不觉已经从 Gson 编解码切换成了 Jackson。所以此时,行为就不见得和之前完全一致了。
针对本案例中序列化值为 null 的字段的行为而言,我们可以分别看下它们的行为是否一致。
- 对于 Gson 而言:
GsonHttpMessageConverter 默认使用 new Gson() 来构建 Gson,它的构造器中指明了相关配置:
public Gson() {
this(Excluder.DEFAULT, FieldNamingPolicy.IDENTITY,
Collections.<Type, InstanceCreator<?>>emptyMap(), DEFAULT_SERIALIZE_NULLS,
DEFAULT_COMPLEX_MAP_KEYS, DEFAULT_JSON_NON_EXECUTABLE, DEFAULT_ESCAPE_HTML,
DEFAULT_PRETTY_PRINT, DEFAULT_LENIENT, DEFAULT_SPECIALIZE_FLOAT_VALUES,
LongSerializationPolicy.DEFAULT, null, DateFormat.DEFAULT, DateFormat.DEFAULT,
Collections.<TypeAdapterFactory>emptyList(), Collections.<TypeAdapterFactory>emptyList(),
Collections.<TypeAdapterFactory>emptyList());
}
从 DEFAULT_SERIALIZE_NULLS 可以看出,它是默认不序列化 null 的。
- 对于 Jackson 而言:
MappingJackson2HttpMessageConverter 使用"Jackson2ObjectMapperBuilder.json().build()“来构建 ObjectMapper,它默认只显式指定了下面两个配置:
MapperFeature.DEFAULT_VIEW_INCLUSION
DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES
Jackson 默认对于 null 的处理是做序列化的,所以本案例中 age 为 null 时,仍然被序列化了。
通过上面两种 JSON 序列化的分析可以看出,返回的内容在依赖项改变的情况下确实可能发生变化。
问题修正
那么针对这个问题,如何修正呢?即保持在 Jackson 依赖项添加的情况下,让它和 Gson 的序列化行为一致吗?这里可以按照以下方式进行修改:
@Data
@NoArgsConstructor
@AllArgsConstructor
@JsonInclude(JsonInclude.Include.NON_NULL)
public class Student {
private String name;
//或直接加在 age 上:@JsonInclude(JsonInclude.Include.NON_NULL)
private Integer age;
}
我们可以直接使用 @JsonInclude 这个注解,让 Jackson 和 Gson 的默认行为对于 null 的处理变成一致。
上述修改方案虽然看起来简单,但是假设有很多对象如此,万一遗漏了怎么办呢?所以可以从全局角度来修改,修改的关键代码如下:
//ObjectMapper mapper = new ObjectMapper();mapper.
setSerializationInclusion(Include.NON_NULL);
但是如何修改 ObjectMapper 呢?这个对象是由 MappingJackson2HttpMessageConverter 构建的,看似无法插足去修改。实际上,我们在非 Spring Boot 程序中,可以按照下面这种方式来修改:
@RestController
public class HelloController {
public HelloController(RequestMappingHandlerAdapter requestMappingHandlerAdapter){
List<HttpMessageConverter<?>> messageConverters =
requestMappingHandlerAdapter.getMessageConverters();
for (HttpMessageConverter<?> messageConverter : messageConverters) {
if(messageConverter instanceof MappingJackson2HttpMessageConverter ){
(((MappingJackson2HttpMessageConverter)messageConverter).getObjectMapper()).setSerializationInclusion(JsonInclude.Include.NON_NULL);
}
}
}
//省略其他非关键代码
}
我们用自动注入的方式获取到 RequestMappingHandlerAdapter,然后找到 Jackson 解析器,进行配置即可。
通过上述两种修改方案,我们就能做到忽略 null 的 age 字段了。
案例 3:Required request body is missing
通过案例 1,我们已经能够解析 Body 了,但是有时候,我们会有一些很好的想法。例如为了查询问题方便,在请求过来时,自定义一个 Filter 来统一输出具体的请求内容,关键代码如下:
public class ReadBodyFilter implements Filter {
//省略其他非关键代码
@Override
public void doFilter(ServletRequest request,
ServletResponse response, FilterChain chain)
throws IOException, ServletException {
String requestBody = IOUtils.toString(request.getInputStream(), "utf-8");
System.out.println("print request body in filter:" + requestBody);
chain.doFilter(request, response);
}
}
然后,我们可以把这个 Filter 添加到 web.xml 并配置如下:
<filter>
<filter-name>myFilter</filter-name>
<filter-class>com.puzzles.ReadBodyFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>myFilter</filter-name>
<url-pattern>/app/*</url-pattern>
</filter-mapping>
再测试下 Controller 层中定义的接口:
@PostMapping("/hi3")
public Student hi3(@RequestBody Student student) {
return student;
}
运行测试,我们会发现下面的日志:
print request body in filter:{
“name”: “xiaoming”,
“age”: 10
}
25-Mar-2021 11:04:44.906 璀﹀憡 [http-nio-8080-exec-5] org.springframework.web.servlet.handler.AbstractHandlerExceptionResolver.logException Resolved
[org.springframework.http.converter.HttpMessageNotReadableException: Required request body is missing: public com.puzzles.Student com.puzzles.HelloController.hi3(com.puzzles.Student)]
可以看到,请求的 Body 确实在请求中输出了,但是后续的操作直接报错了,错误提示:Required request body is missing。
案例解析
要了解这个错误的根本原因,你得知道这个错误抛出的源头。查阅请求 Body 转化的相关代码,有这样一段关键逻辑(参考 RequestResponseBodyMethodProcessor#readWithMessageConverters):
protected <T> Object readWithMessageConverters(NativeWebRequest webRequest, MethodParameter parameter,
Type paramType) throws IOException, HttpMediaTypeNotSupportedException, HttpMessageNotReadableException {
HttpServletRequest servletRequest = webRequest.getNativeRequest(HttpServletRequest.class);
ServletServerHttpRequest inputMessage = new ServletServerHttpRequest(servletRequest);
//读取 Body 并进行转化
Object arg = readWithMessageConverters(inputMessage, parameter, paramType);
if (arg == null && checkRequired(parameter)) {
throw new HttpMessageNotReadableException("Required request body is missing: " +
parameter.getExecutable().toGenericString(), inputMessage);
}
return arg;
}
protected boolean checkRequired(MethodParameter parameter) {
RequestBody requestBody = parameter.getParameterAnnotation(RequestBody.class);
return (requestBody != null && requestBody.required() && !parameter.isOptional());
}
当使用了 @RequestBody 且是必须时,如果解析出的 Body 为 null,则报错提示 Required request body is missing。
所以我们要继续追踪代码,来查询什么情况下会返回 body 为 null。关键代码参考 AbstractMessageConverterMethodArgumentResolver#readWithMessageConverters:
protected <T> Object readWithMessageConverters(HttpInputMessage inputMessage, MethodParameter parameter,
Type targetType){
//省略非关键代码
Object body = NO_VALUE;
EmptyBodyCheckingHttpInputMessage message;
try {
message = new EmptyBodyCheckingHttpInputMessage(inputMessage);
for (HttpMessageConverter<?> converter : this.messageConverters) {
Class<HttpMessageConverter<?>> converterType = (Class<HttpMessageConverter<?>>) converter.getClass();
GenericHttpMessageConverter<?> genericConverter =
(converter instanceof GenericHttpMessageConverter ? (GenericHttpMessageConverter<?>) converter : null);
if (genericConverter != null ? genericConverter.canRead(targetType, contextClass, contentType) :
(targetClass != null && converter.canRead(targetClass, contentType))) {
if (message.hasBody()) {
//省略非关键代码:读取并转化 body
else {
//处理没有 body 情况,默认返回 null
body = getAdvice().handleEmptyBody(null, message, parameter, targetType, converterType);
}
break;
}
}
}
catch (IOException ex) {
throw new HttpMessageNotReadableException("I/O error while reading input message", ex, inputMessage);
}
//省略非关键代码
return body;
}
当 message 没有 body 时( message.hasBody() 为 false ),则将 body 认为是 null。继续查看 message 本身的定义,它是一种包装了请求 Header 和 Body 流的 EmptyBodyCheckingHttpInputMessage 类型。其代码实现如下:
public EmptyBodyCheckingHttpInputMessage(HttpInputMessage inputMessage) throws IOException {
this.headers = inputMessage.getHeaders();
InputStream inputStream = inputMessage.getBody();
if (inputStream.markSupported()) {
//省略其他非关键代码
}
else {
PushbackInputStream pushbackInputStream = new PushbackInputStream(inputStream);
int b = pushbackInputStream.read();
if (b == -1) {
this.body = null;
}
else {
this.body = pushbackInputStream;
pushbackInputStream.unread(b);
}
}
}
public InputStream getBody() {
return (this.body != null ? this.body : StreamUtils.emptyInput());
}
Body 为空的判断是由 pushbackInputStream.read() 其值为 -1 来判断出的,即没有数据可以读取。
看到这里,你可能会有疑问:假设有 Body,read() 的执行不就把数据读取走了一点么?确实如此,所以这里我使用了 pushbackInputStream.unread(b) 调用来把读取出来的数据归还回去,这样就完成了是否有 Body 的判断,又保证了 Body 的完整性。
分析到这里,再结合前面的案例,你应该能想到造成 Body 缺失的原因了吧?
- 本身就没有 Body;
- 有 Body,但是 Body 本身代表的流已经被前面读取过了。
很明显,我们的案例属于第 2 种情况,即在过滤器中,我们就已经将 Body 读取完了,关键代码如下:
//request 是 ServletRequestString
requestBody = IOUtils.toString(request.getInputStream(), “utf-8”);
在这种情况下,作为一个普通的流,已经没有数据可以供给后面的转化器来读取了。
问题修正
所以我们可以直接在过滤器中去掉 Body 读取的代码,这样后续操作就又能读到数据了。但是这样又不满足我们的需求,如果我们坚持如此怎么办呢?这里我先直接给出答案,即定义一个 RequestBodyAdviceAdapter 的 Bean:
@ControllerAdvice
public class PrintRequestBodyAdviceAdapter extends RequestBodyAdviceAdapter {
@Override
public boolean supports(MethodParameter methodParameter, Type type, Class<? extends HttpMessageConverter<?>> aClass) {
return true;
}
@Override
public Object afterBodyRead(Object body, HttpInputMessage inputMessage,MethodParameter parameter, Type targetType,
Class<? extends HttpMessageConverter<?>> converterType) {
System.out.println("print request body in advice:" + body);
return super.afterBodyRead(body, inputMessage, parameter, targetType, converterType);
}
}
我们可以看到方法 afterBodyRead 的命名,很明显,这里的 Body 已经是从数据流中转化过的。
那么它是如何工作起来的呢?我们可以查看下面的代码(参考 AbstractMessageConverterMethodArgumentResolver#readWithMessageConverters):
protected <T> Object readWithMessageConverters(HttpInputMessage inputMessage, MethodParameter parameter, Type targetType){
//省略其他非关键代码
if (message.hasBody()) {
HttpInputMessage msgToUse = getAdvice().beforeBodyRead(message, parameter, targetType, converterType);
body = (genericConverter != null ? genericConverter.read(targetType, contextClass, msgToUse) : ((HttpMessageConverter<T>)converter).read(targetClass, msgToUse));
body = getAdvice().afterBodyRead(body, msgToUse, parameter, targetType, converterType);
//省略其他非关键代码
}
//省略其他非关键代码
return body;
}
当一个 Body 被解析出来后,会调用 getAdvice() 来获取 RequestResponseBodyAdviceChain;然后在这个 Chain 中,寻找合适的 Advice 并执行。
正好我们前面定义了 PrintRequestBodyAdviceAdapter,所以它的相关方法就被执行了。从执行时机来看,此时 Body 已经解析完毕了,也就是说,传递给 PrintRequestBodyAdviceAdapter 的 Body 对象已经是一个解析过的对象,而不再是一个流了。
通过上面的 Advice 方案,我们满足了类似的需求,又保证了程序的正确执行。至于其他的一些方案,你可以来思考一下。