
Spring基础知识 #
Spring 最基础的知识就是那些 Spring 最本质的实现和思想。
one
在进行“传统的”Java 编程时,对象与对象之间的关系都是紧密耦合的,例如服务类 Service 使用组件 ComponentA,则可能写出这样的代码:
public class Service {
private ComponentA component = new ComponentA("first component");
}
在没有 Spring 之前,你应该会觉得这段代码并没有多大问题,毕竟大家都这么写,而且也没有什么更好的方式。就像只有一条大路可走时,大家都朝一个方向走,你大概率不会反思是不是有捷径。
而随着项目的开发推进,你会发现检验一个方式好不好的硬性标准之一,就是看它有没有拥抱变化的能力。假设有一天,我们的 ComponentA 类的构造器需要更多的参数了,你会发现,上述代码到处充斥着这行需要改进的代码:
private ComponentA component = new ComponentA("first component");
此时你可能会想了,那我用下面这种方式来构造 Service 就可以了吧?
public class Service {
private ComponentA component;
public Service(ComponentA component){
this.component = component;
}
}
当然不行,你忽略了一点,你在构建 Service 对象的时候,不还得使用 new 关键字来构建 Component?需要修改的调用处并不少!
two
很明显,这是一个噩梦。那么,除了这点,还有没有别的不好的地方呢?上面说的是非单例的情况,如果 ComponentA 本身是一个单例,会不会好些?毕竟我们可能找一个地方 new 一次 ComponentA 实例就足够了,但是你可能会发现另外一些问题。
下面是一段用“双重检验锁”实现的 CompoentA 类:
public class ComponentA{
private volatile static ComponentA INSTANCE;
private ComponentA() {}
public static ComponentA getInstance(){
if (INSTANCE== null) {
synchronized (ComponentA.class) {
if (INSTANCE== null) {
INSTANCE= new ComponentA();
}
}
}
return INSTANCE;
}
}
其实写了这么多代码,最终我们只是要一个单例而已。而且假设我们有 ComponentB、ComponentC、ComponentD 等,那上面的重复性代码不都得写一遍?也是烦的不行,不是么?
others
除了上述两个典型问题,还有不易于测试、不易扩展功能(例如支持 AOP)等缺点。说白了,所有问题的根源(之一)就是对象与对象之间耦合性太强了。
so
所以 Spring 的引入,解决了上面这些零零种种的问题。那么它是怎么解决的呢?
这里套用一个租房的场景。我们为什么喜欢通过中介来租房子呢?因为省事呀,只要花点小钱就不用与房东产生直接的“纠缠”了。
Spring 就是这个思路,它就像一个“中介”公司。当你需要一个依赖的对象(房子)时,你直接把你的需求告诉 Spring(中介)就好了,它会帮你搞定这些依赖对象,按需创建它们,而无需你的任何额外操作。
不过,在 Spring 中,房东和租房者都是对象实例,只不过换了一个名字叫 Bean 而已。
可以说,通过一套稳定的生产流程,作为“中介”的 Spring 完成了生产和预装(牵线搭桥)这些 Bean 的任务。此时,你可能想了解更多。例如,如果一个 Bean(租房者)需要用到另外一个 Bean(房子)时,具体是怎么操作呢?
本质上只能从 Spring“中介”里去找,有时候我们直接根据名称(小区名)去找,有时候则根据类型(户型),各种方式不尽相同。你就把 Spring 理解成一个 Map 型的公司即可,实现如下:
public class BeanFactory {
private Map<String, Bean> beanMap = new HashMap<>();
public Bean getBean(String key){
return beanMap.get(key) ;
}
}
如上述代码所示,Bean 所属公司提供了对于 Map 的操作来完成查找,找到 Bean 后装配给其它对象,这就是依赖查找、自动注入的过程。具体的bean的生命周期的可见 spring中bean的生命周期
那么回过头看,这些 Bean 又是怎么被创建的呢?
对于一个项目而言,不可避免会出现两种情况:一些对象是需要 Spring 来管理的,另外一些(例如项目中其它的类和依赖的 Jar 中的类)又不需要。所以我们得有一个办法去标识哪些是需要成为 Spring Bean,因此各式各样的注解才应运而生,例如 Component 注解等。
那有了这些注解后,谁又来做“发现”它们的工作呢?直接配置指定自然不成问题,但是很明显“自动发现”更让人省心。此时,我们往往需要一个扫描器,可以模拟写下这样一个扫描器:
public class AnnotationScan {
//通过扫描包名来找到Bean
void scan(String packages) {
//
}
}
有了扫描器,我们就知道哪些类是需要成为 Bean。
那怎么实例化为 Bean(也就是一个对象实例而已)呢?很明显,只能通过反射来做了。不过这里面的方式可能有多种:
java.lang.Class.newInsance()java.lang.reflect.Constructor.newInstance()ReflectionFactory.newConstructorForSerialization()
有了创建,有了装配,一个 Bean 才能成为自己想要的样子。
而需求总是源源不断的,我们有时候想记录一个方法调用的性能,有时候我们又想在方法调用时输出统一的调用日志。诸如此类,我们肯定不想频繁再来个散弹式的修改。所以我们有了 AOP,帮忙拦截方法调用,进行功能扩展。拦截谁呢?在 Spring 中自然就是 Bean 了。
其实 AOP 并不神奇,结合刚才的 Bean(中介)公司来讲,假设我们判断出一个 Bean 需要“增强”了,我们直接让它从公司返回的时候,就使用一个代理对象作为返回不就可以了么?示例如下:
public class BeanFactory {
private Map<String, Bean> beanMap = new HashMap<>();
public Bean getBean(String key){
//查找是否创建过
Bean bean = beanMap.get(key);
if(bean != null){
return bean;
}
//创建一个Bean
Bean bean = createBean();
//判断要不要AOP
boolean needAop = judgeIfNeedAop(bean);
try{
if(needAop)
//创建代理对象
bean = createProxyObject(bean);
return bean;
else:
return bean
}finally{
beanMap.put(key, bean);
}
}
}
那么怎么知道一个对象要不要 AOP?既然一个对象要 AOP,它肯定被标记了一些“规则”,例如拦截某个类的某某方法,示例如下:
@Aspect
@Service
public class AopConfig {
@Around("execution(* com.spring.puzzle.ComponentA.execute()) ")
public void recordPayPerformance(ProceedingJoinPoint joinPoint) throws Throwable {
//
}
}
这个时候,很明显了,假设你的 Bean 名字是 ComponentA,那么就应该返回 ComponentA 类型的代理对象了。至于这些规则是怎么建立起来的呢?你看到它上面使用的各种注解大概就能明白其中的规则了,无非就是扫描注解,根据注解创建规则。
01|Spring Bean 定义常见错误 #
Spring 的核心是围绕 Bean 进行的,不管是 Spring Boot 还是 Spring Cloud,只要名称中带有 Spring 关键字的技术都脱离不了 Bean,而要使用一个 Bean 少不了要先定义出来,所以定义一个 Bean 就变得格外重要了。
当然,对于这么重要的工作,Spring 自然给我们提供了很多简单易用的方式。然而,这种简单易用得益于 Spring 的“约定大于配置”,但我们往往不见得会对所有的约定都了然于胸,所以仍然会在 Bean 的定义上犯一些经典的错误。
接下来我们就来了解下那些经典错误以及它们背后的原理,你也可以对照着去看看自己是否也曾犯过,后来又是如何解决的。
案例 1:隐式扫描不到 Bean 的定义
在构建 Web 服务时,我们常使用 Spring Boot 来快速构建。例如,使用下面的包结构和相关代码来完成一个简易的 Web 版 HelloWorld:

其中,负责启动程序的 Application 类定义如下:
package com.spring.puzzle.class1.example1.application
//省略 import
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
提供接口的 HelloWorldController 代码如下:
package com.spring.puzzle.class1.example1.application
//省略 import
@RestController
public class HelloWorldController {
@RequestMapping(path = "hi", method = RequestMethod.GET)
public String hi(){
return "helloworld";
};
}
上述代码即可实现一个简单的功能:访问 http://localhost:8080/hi 返回 helloworld。两个关键类位于同一个包(即 application)中。其中 HelloWorldController 因为添加了 @RestController,最终被识别成一个 Controller 的 Bean。
但是,假设有一天,当我们需要添加多个类似的 Controller,同时又希望用更清晰的包层次和结构来管理时,我们可能会去单独建立一个独立于 application 包之外的 Controller 包,并调整类的位置。调整后结构示意如下:

实际上,我们没有改变任何代码,只是改变了包的结构,但是我们会发现这个 Web 应用失效了,即不能识别出 HelloWorldController 了。也就是说,我们找不到 HelloWorldController 这个 Bean 了。这是为何?
案例解析
要了解 HelloWorldController 为什么会失效,就需要先了解之前是如何生效的。对于 Spring Boot 而言,关键点在于 Application.java 中使用了 SpringBootApplication 注解。而这个注解继承了另外一些注解,具体定义如下:
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@SpringBootConfiguration
@EnableAutoConfiguration
@ComponentScan(excludeFilters = { @Filter(type = FilterType.CUSTOM, classes = TypeExcludeFilter.class),
@Filter(type = FilterType.CUSTOM, classes = AutoConfigurationExcludeFilter.class) })
public @interface SpringBootApplication {
//省略非关键代码
}
从定义可以看出,SpringBootApplication 开启了很多功能,其中一个关键功能就是 ComponentScan,参考其配置如下:
@ComponentScan(excludeFilters = { @Filter(type = FilterType.CUSTOM, classes = TypeExcludeFilter.class)
当 Spring Boot 启动时,ComponentScan 的启用意味着会去扫描出所有定义的 Bean,那么扫描什么位置呢?这是由 ComponentScan 注解的 basePackages 属性指定的,具体可参考如下定义:
public @interface ComponentScan {
/**
* Base packages to scan for annotated components.
* <p>{@link #value} is an alias for (and mutually exclusive with) this
* attribute.
* <p>Use {@link #basePackageClasses} for a type-safe alternative to
* String-based package names.
*/
@AliasFor("value")
String[] basePackages() default {};
//省略其他非关键代码
}
而在我们的案例中,我们直接使用的是 SpringBootApplication 注解定义的 ComponentScan,它的 basePackages 没有指定,所以默认为空(即{})。此时扫描的是什么包?这里不妨带着这个问题去调试下(调试位置参考 ComponentScanAnnotationParser#parse 方法),调试视图如下:
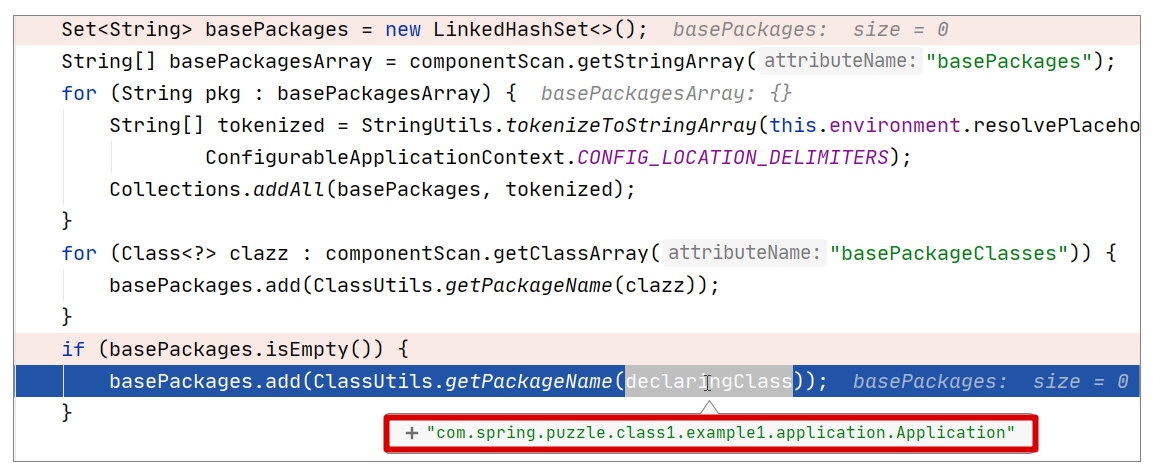
从上图可以看出,当 basePackages 为空时,扫描的包会是 declaringClass 所在的包,在本案例中,declaringClass 就是 Application.class,所以扫描的包其实就是它所在的包,即 com.spring.puzzle.class1.example1.application。
对比我们重组包结构前后,我们自然就找到了这个问题的根源:在调整前,HelloWorldController 在扫描范围内,而调整后,它已经远离了扫描范围(不和 Application.java 一个包了),虽然代码没有一丝丝改变,但是这个功能已经失效了。
所以,综合来看,这个问题是因为我们不够了解 Spring Boot 的默认扫描规则引起的。我们仅仅享受了它的便捷,但是并未了解它背后的故事,所以稍作变化,就可能玩不转了。
问题修正
针对这个案例,有了源码的剖析,我们可以快速找到解决方案了。当然了,我们所谓的解决方案肯定不是说把 HelloWorldController 移动回原来的位置,而是真正去满足需求。在这里,真正解决问题的方式是显式配置 @ComponentScan。具体修改方式如下:
@SpringBootApplication
@ComponentScan("com.spring.puzzle.class1.example1.controller")
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
通过上述修改,我们显式指定了扫描的范围为 com.spring.puzzle.class1.example1.controller。不过需要注意的是,显式指定后,默认的扫描范围(即 com.spring.puzzle.class1.example1.application)就不会被添加进去了。另外,我们也可以使用 @ComponentScans 来修复问题,使用方式如下:
@ComponentScans(value = { @ComponentScan(value = "com.spring.puzzle.class1.example1.controller"), @ComponentScan(value = "com.spring.puzzle.class1.example1.application") })
顾名思义,可以看出 ComponentScans 相比较 ComponentScan 多了一个 s,支持多个包的扫描范围指定。
此时,细心的你可能会发现:如果对源码缺乏了解,很容易会顾此失彼。以 ComponentScan 为例,原有的代码扫描了默认包而忽略了其它包;而一旦显式指定其它包,原来的默认扫描包就被忽略了。
案例 2:定义的 Bean 缺少隐式依赖
初学 Spring 时,我们往往不能快速转化思维。例如,在程序开发过程中,有时候,一方面我们把一个类定义成 Bean,同时又觉得这个 Bean 的定义除了加了一些 Spring 注解外,并没有什么不同。所以在后续使用时,有时候我们会不假思索地去随意定义它,例如我们会写出下面这样的代码:
@Service
public class ServiceImpl {
private String serviceName;
public ServiceImpl(String serviceName){
this.serviceName = serviceName;
}
}
ServiceImpl 因为标记为 @Service 而成为一个 Bean。另外我们 ServiceImpl 显式定义了一个构造器。但是,上面的代码不是永远都能正确运行的,有时候会报下面这种错误:
Parameter 0 of constructor in com.spring.puzzle.class1.example2.ServiceImpl required a bean of type 'java.lang.String' that could not be found.
那这种错误是怎么发生的呢?下面我们来分析一下。
案例解析
当创建一个 Bean 时,调用的方法是 AbstractAutowireCapableBeanFactory#createBeanInstance。它主要包含两大基本步骤:寻找构造器和通过反射调用构造器创建实例。对于这个案例,最核心的代码执行,你可以参考下面的代码片段:
// Candidate constructors for autowiring?
Constructor<?>[] ctors = determineConstructorsFromBeanPostProcessors(beanClass, beanName);
if (ctors != null || mbd.getResolvedAutowireMode() == AUTOWIRE_CONSTRUCTOR ||
mbd.hasConstructorArgumentValues() || !ObjectUtils.isEmpty(args)) {
return autowireConstructor(beanName, mbd, ctors, args);
}
Spring 会先执行 determineConstructorsFromBeanPostProcessors 方法来获取构造器,然后通过 autowireConstructor 方法带着构造器去创建实例。很明显,在本案例中只有一个构造器,所以非常容易跟踪这个问题。
autowireConstructor 方法要创建实例,不仅需要知道是哪个构造器,还需要知道构造器对应的参数,这点从最后创建实例的方法名也可以看出,参考如下(即 ConstructorResolver#instantiate):
private Object instantiate(
String beanName, RootBeanDefinition mbd, Constructor<?> constructorToUse, Object[] argsToUse)
那么上述方法中存储构造参数的 argsToUse 如何获取呢?换言之,当我们已经知道构造器 ServiceImpl(String serviceName),要创建出 ServiceImpl 实例,如何确定 serviceName 的值是多少?
很明显,这里是在使用 Spring,我们不能直接显式使用 new 关键字来创建实例。Spring 只能是去寻找依赖来作为构造器调用参数。
那么这个参数如何获取呢?可以参考下面的代码片段(即 ConstructorResolver#autowireConstructor):
argsHolder = createArgumentArray(beanName, mbd, resolvedValues, bw, paramTypes, paramNames,
getUserDeclaredConstructor(candidate), autowiring, candidates.length == 1);
我们可以调用 createArgumentArray 方法来构建调用构造器的参数数组,而这个方法的最终实现是从 BeanFactory 中获取 Bean,可以参考下述调用:
return this.beanFactory.resolveDependency(
new DependencyDescriptor(param, true), beanName, autowiredBeanNames, typeConverter);
如果用调试视图,我们则可以看到更多的信息:
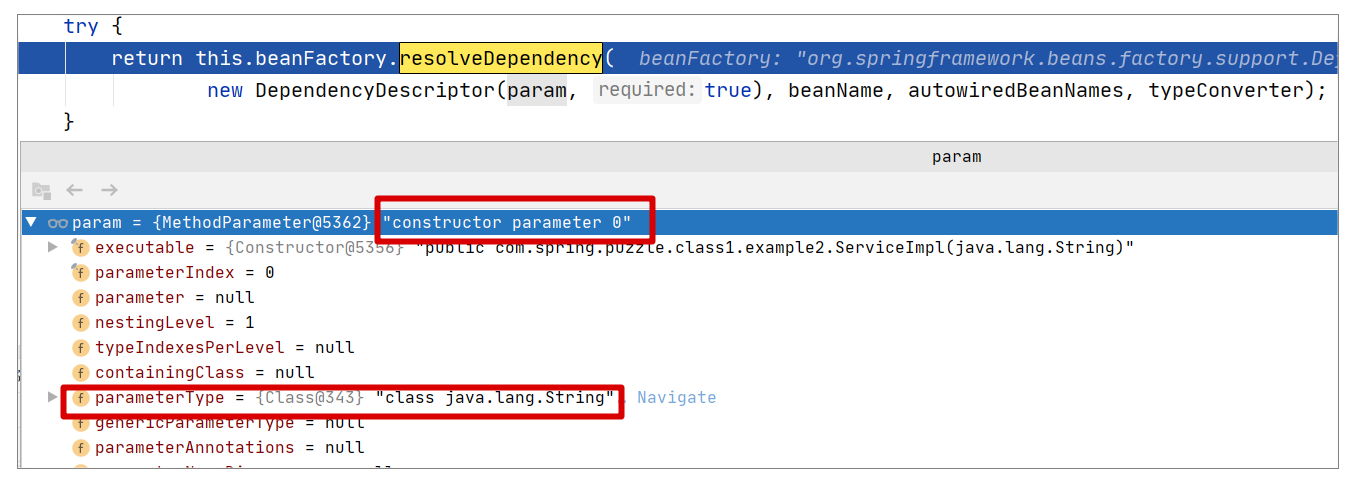
如图所示,上述的调用即是根据参数来寻找对应的 Bean,在本案例中,如果找不到对应的 Bean 就会抛出异常,提示装配失败。
问题修正
从源码级别了解了错误的原因后,现在反思为什么会出现这个错误。追根溯源,正如开头所述,因为不了解很多隐式的规则:我们定义一个类为 Bean,如果再显式定义了构造器,那么这个 Bean 在构建时,会自动根据构造器参数定义寻找对应的 Bean,然后反射创建出这个 Bean。
了解了这个隐式规则后,解决这个问题就简单多了。我们可以直接定义一个能让 Spring 装配给 ServiceImpl 构造器参数的 Bean,例如定义如下:
//这个bean装配给ServiceImpl的构造器参数“serviceName”
@Bean
public String serviceName(){
return "MyServiceName";
}
再次运行程序,发现一切正常了。
所以,我们在使用 Spring 时,不要总想着定义的 Bean 也可以在非 Spring 场合直接用 new 关键字显式使用,这种思路是不可取的。
另外,类似的,假设我们不了解 Spring 的隐式规则,在修正问题后,我们可能写出更多看似可以运行的程序,代码如下:
@Service
public class ServiceImpl {
private String serviceName;
public ServiceImpl(String serviceName){
this.serviceName = serviceName;
}
public ServiceImpl(String serviceName, String otherStringParameter){
this.serviceName = serviceName;
}
}
如果我们仍用非 Spring 的思维去审阅这段代码,可能不会觉得有什么问题,毕竟 String 类型可以自动装配了,无非就是增加了一个 String 类型的参数而已。
但是如果你了解 Spring 内部是用反射来构建 Bean 的话,就不难发现问题所在:存在两个构造器,都可以调用时,到底应该调用哪个呢?最终 Spring 无从选择,只能尝试去调用默认构造器,而这个默认构造器又不存在,所以测试这个程序它会出错。
Tips:
案例 3:原型 Bean 被固定
接下来,我们再来看另外一个关于 Bean 定义不生效的案例。在定义 Bean 时,有时候我们会使用原型 Bean,例如定义如下:
@Service
@Scope(ConfigurableBeanFactory.SCOPE_PROTOTYPE)
public class ServiceImpl {
}
然后我们按照下面的方式去使用它:
@RestController
public class HelloWorldController {
@Autowired
private ServiceImpl serviceImpl;
@RequestMapping(path = "hi", method = RequestMethod.GET)
public String hi(){
return "helloworld, service is : " + serviceImpl;
};
}
结果,我们会发现,不管我们访问多少次http://localhost:8080/hi,访问的结果都是不变的,如下:
helloworld, service is :
com.spring.puzzle.class1.example3.error.ServiceImpl@4908af
很明显,这很可能和我们定义 ServiceImpl 为原型 Bean 的初衷背道而驰,如何理解这个现象呢?
案例解析
当一个属性成员 serviceImpl 声明为 @Autowired 后,那么在创建 HelloWorldController 这个 Bean 时,会先使用构造器反射出实例,然后来装配各个标记为 @Autowired 的属性成员(装配方法参考 AbstractAutowireCapableBeanFactory#populateBean)。
具体到执行过程,它会使用很多 BeanPostProcessor 来做完成工作,其中一种是 AutowiredAnnotationBeanPostProcessor,它会通过 DefaultListableBeanFactory#findAutowireCandidates 寻找到 ServiceImpl 类型的 Bean,然后设置给对应的属性(即 serviceImpl 成员)。
关键执行步骤可参考 AutowiredAnnotationBeanPostProcessor.AutowiredFieldElement#inject:
protected void inject(Object bean, @Nullable String beanName, @Nullable PropertyValues pvs) throws Throwable {
Field field = (Field) this.member;
Object value;
//寻找“bean”
if (this.cached) {
value = resolvedCachedArgument(beanName, this.cachedFieldValue);
}
else {
//省略其他非关键代码
value = beanFactory.resolveDependency(desc, beanName, autowiredBeanNames, typeConverter);
}
if (value != null) {
//将bean设置给成员字段
ReflectionUtils.makeAccessible(field);
field.set(bean, value);
}
}
待我们寻找到要自动注入的 Bean 后,即可通过反射设置给对应的 field。这个 field 的执行只发生了一次,所以后续就固定起来了,它并不会因为 ServiceImpl 标记了 SCOPE_PROTOTYPE 而改变。
所以,当一个单例的 Bean,使用 autowired 注解标记其属性时,你一定要注意这个属性值会被固定下来,即通过autowire引入一定是个单例的。
问题修正
通过上述源码分析,我们可以知道要修正这个问题,肯定是不能将 ServiceImpl 的 Bean 固定到属性上的,而应该是每次使用时都会重新获取一次。所以这里我提供了两种修正方式:
1. 自动注入 Context
即自动注入 ApplicationContext,然后定义 getServiceImpl() 方法,在方法中获取一个新的 ServiceImpl 类型实例。修正代码如下:
@RestController
public class HelloWorldController {
@Autowired
private ApplicationContext applicationContext;
@RequestMapping(path = "hi", method = RequestMethod.GET)
public String hi(){
return "helloworld, service is : " + getServiceImpl();
};
public ServiceImpl getServiceImpl(){
return applicationContext.getBean(ServiceImpl.class);
}
}
2. 使用 Lookup 注解
类似修正方法 1,也添加一个 getServiceImpl 方法,不过这个方法是被 Lookup 标记的。修正代码如下:
@RestController
public class HelloWorldController {
@RequestMapping(path = "hi", method = RequestMethod.GET)
public String hi(){
return "helloworld, service is : " + getServiceImpl();
};
@Lookup
public ServiceImpl getServiceImpl(){
return null;
}
}
通过这两种修正方式,再次测试程序,我们会发现结果已经符合预期(每次访问这个接口,都会创建新的 Bean)。
这里我们不妨再拓展下,讨论下 Lookup 是如何生效的。毕竟在修正代码中,我们看到 getServiceImpl 方法的实现返回值是 null,这或许很难说服自己。
首先,我们可以通过调试方式看下方法的执行,参考下图:

从上图我们可以看出,我们最终的执行因为标记了 Lookup 而走入了 CglibSubclassingInstantiationStrategy.LookupOverrideMethodInterceptor,这个方法的关键实现参考 LookupOverrideMethodInterceptor#intercept:
private final BeanFactory owner;
public Object intercept(Object obj, Method method, Object[] args, MethodProxy mp) throws Throwable {
LookupOverride lo = (LookupOverride) getBeanDefinition().getMethodOverrides().getOverride(method);
Assert.state(lo != null, "LookupOverride not found");
Object[] argsToUse = (args.length > 0 ? args : null); // if no-arg, don't insist on args at all
if (StringUtils.hasText(lo.getBeanName())) {
return (argsToUse != null ? this.owner.getBean(lo.getBeanName(), argsToUse) :
this.owner.getBean(lo.getBeanName()));
}
else {
return (argsToUse != null ? this.owner.getBean(method.getReturnType(), argsToUse) :
this.owner.getBean(method.getReturnType()));
}
}
我们的方法调用最终并没有走入案例代码实现的 return null 语句,而是通过 BeanFactory 来获取 Bean。所以从这点也可以看出,其实在我们的 getServiceImpl 方法实现中,随便怎么写都行,这不太重要。
例如,我们可以使用下面的实现来测试下这个结论:
@Lookup
public ServiceImpl getServiceImpl(){
//下面的日志会输出么?
log.info("executing this method");
return null;
}
以上代码,添加了一行代码输出日志。测试后,我们会发现并没有日志输出。这也验证了,当使用 Lookup 注解一个方法时,这个方法的具体实现已并不重要。
再回溯下前面的分析,为什么我们走入了 CGLIB 搞出的类,这是因为我们有方法标记了 Lookup。我们可以从下面的这段代码得到验证,参考 SimpleInstantiationStrategy#instantiate:
@Override
public Object instantiate(RootBeanDefinition bd, @Nullable String beanName, BeanFactory owner) {
// Don't override the class with CGLIB if no overrides.
if (!bd.hasMethodOverrides()) {
//
return BeanUtils.instantiateClass(constructorToUse);
}
else {
// Must generate CGLIB subclass.
return instantiateWithMethodInjection(bd, beanName, owner);
}
}
在上述代码中,当 hasMethodOverrides 为 true 时,则使用 CGLIB。而在本案例中,这个条件的成立在于解析 HelloWorldController 这个 Bean 时,我们会发现有方法标记了 Lookup,此时就会添加相应方法到属性 methodOverrides 里面去(此过程由 AutowiredAnnotationBeanPostProcessor#determineCandidateConstructors 完成)。
添加后效果图如下:

02/03|Spring Bean 依赖注入常见错误 #
提及 Spring 的优势或特性,我们都会立马想起“控制反转、依赖注入”这八字真言。而 @Autowired 正是用来支持依赖注入的核心利器之一。表面上看,它仅仅是一个注解,在使用上不应该出错。但是,在实际使用中,我们仍然会出现各式各样的错误,而且都堪称经典。所以这节课我就带着你学习下这些经典错误及其背后的原因,以防患于未然。
案例 1:过多赠予,无所适从
在使用 @Autowired 时,不管你是菜鸟级还是专家级的 Spring 使用者,都应该制造或者遭遇过类似的错误:
required a single bean, but 2 were found
顾名思义,我们仅需要一个 Bean,但实际却提供了 2 个(这里的“2”在实际错误中可能是其它大于 1 的任何数字)。
为了重现这个错误,我们可以先写一个案例来模拟下。假设我们在开发一个学籍管理系统案例,需要提供一个 API 根据学生的学号(ID)来移除学生,学生的信息维护肯定需要一个数据库来支撑,所以大体上可以实现如下:
@RestController
@Slf4j
@Validated
public class StudentController {
@Autowired
DataService dataService;
@RequestMapping(path = "students/{id}", method = RequestMethod.DELETE)
public void deleteStudent(@PathVariable("id") @Range(min = 1,max = 100) int id){
dataService.deleteStudent(id);
};
}
其中 DataService 是一个接口,其实现依托于 Oracle,代码示意如下:
public interface DataService {
void deleteStudent(int id);
}
@Repository
@Slf4j
public class OracleDataService implements DataService{
@Override
public void deleteStudent(int id) {
log.info("delete student info maintained by oracle");
}
}
截止目前,运行并测试程序是毫无问题的。但是需求往往是源源不断的,某天我们可能接到节约成本的需求,希望把一些部分非核心的业务从 Oracle 迁移到社区版 Cassandra,所以我们自然会先添加上一个新的 DataService 实现,代码如下:
@Repository
@Slf4j
public class CassandraDataService implements DataService{
@Override
public void deleteStudent(int id) {
log.info("delete student info maintained by cassandra");
}
}
实际上,当我们完成支持多个数据库的准备工作时,程序就已经无法启动了,报错如下:
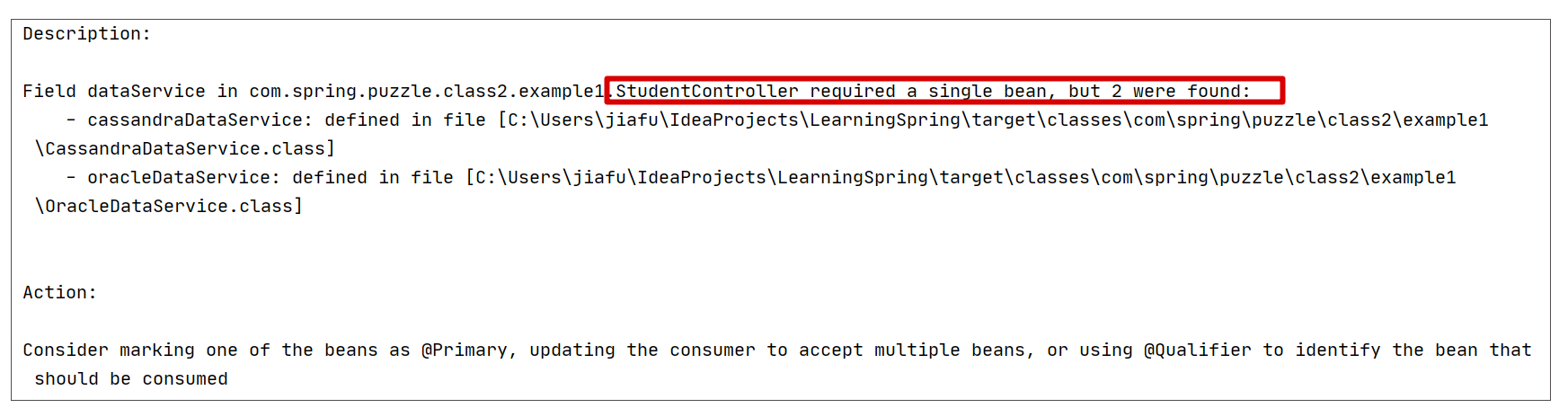
很显然,上述报错信息正是我们这一小节讨论的错误,那么这个错误到底是怎么产生的呢?接下来我们具体分析下。
案例解析
要找到这个问题的根源,我们就需要对 @Autowired 实现的依赖注入的原理有一定的了解。首先,我们先来了解下 @Autowired 发生的位置和核心过程。
当一个 Bean 被构建时,核心包括两个基本步骤:
- 执行 AbstractAutowireCapableBeanFactory#createBeanInstance 方法:通过构造器反射构造出这个 Bean,在此案例中相当于构建出 StudentController 的实例;
- 执行 AbstractAutowireCapableBeanFactory#populate 方法:填充(即设置)这个 Bean,在本案例中,相当于设置 StudentController 实例中被 @Autowired 标记的 dataService 属性成员。
在步骤 2 中,“填充”过程的关键就是执行各种 BeanPostProcessor 处理器,关键代码如下:
protected void populateBean(String beanName, RootBeanDefinition mbd, @Nullable BeanWrapper bw) {
//省略非关键代码
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof InstantiationAwareBeanPostProcessor) {
InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor) bp;
PropertyValues pvsToUse = ibp.postProcessProperties(pvs, bw.getWrappedInstance(), beanName);
//省略非关键代码
}
}
}
}
在上述代码执行过程中,因为 StudentController 含有标记为 Autowired 的成员属性 dataService,所以会使用到 AutowiredAnnotationBeanPostProcessor(BeanPostProcessor 中的一种)来完成“装配”过程:找出合适的 DataService 的 bean 并设置给 StudentController#dataService。如果深究这个装配过程,又可以细分为两个步骤:
- 寻找出所有需要依赖注入的字段和方法,参考 AutowiredAnnotationBeanPostProcessor#postProcessProperties 中的代码行:
InjectionMetadata metadata = findAutowiringMetadata(beanName, bean.getClass(), pvs);
- 根据依赖信息寻找出依赖并完成注入,以字段注入为例,参考 AutowiredFieldElement#inject 方法:
@Override
protected void inject(Object bean, @Nullable String beanName, @Nullable PropertyValues pvs) throws Throwable {
Field field = (Field) this.member;
Object value;
//省略非关键代码
try {
DependencyDescriptor desc = new DependencyDescriptor(field, this.required);
//寻找“依赖”,desc为"dataService"的DependencyDescriptor
value = beanFactory.resolveDependency(desc, beanName, autowiredBeanNames, typeConverter);
}
//省略非关键代码
if (value != null) {
ReflectionUtils.makeAccessible(field);
//装配“依赖”
field.set(bean, value);
}
}
说到这里,我们基本了解了 @Autowired 过程发生的位置和过程。而且很明显,我们案例中的错误就发生在上述“寻找依赖”的过程中(上述代码的第 9 行),那么到底是怎么发生的呢?我们可以继续刨根问底。
为了更清晰地展示错误发生的位置,我们可以采用调试的视角展示其位置(即 DefaultListableBeanFactory#doResolveDependency 中代码片段),参考下图:
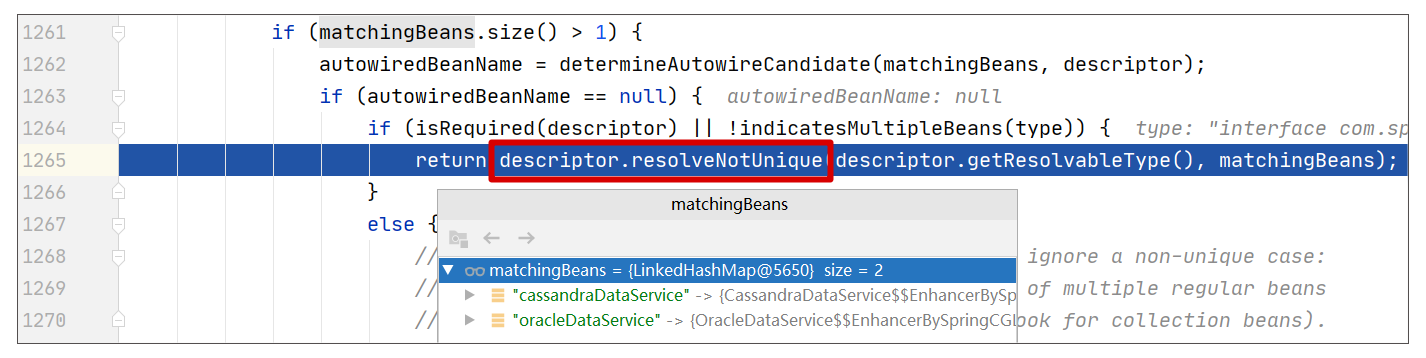
如上图所示,当我们根据 DataService 这个类型来找出依赖时,我们会找出 2 个依赖,分别为 CassandraDataService 和 OracleDataService。在这样的情况下,如果同时满足以下两个条件则会抛出本案例的错误:
- 调用 determineAutowireCandidate 方法来选出优先级最高的依赖,但是发现并没有优先级可依据。具体选择过程可参考 DefaultListableBeanFactory#determineAutowireCandidate:
protected String determineAutowireCandidate(Map<String, Object> candidates, DependencyDescriptor descriptor) {
Class<?> requiredType = descriptor.getDependencyType();
String primaryCandidate = determinePrimaryCandidate(candidates, requiredType);
if (primaryCandidate != null) {
return primaryCandidate;
}
String priorityCandidate = determineHighestPriorityCandidate(candidates, requiredType);
if (priorityCandidate != null) {
return priorityCandidate;
}
// Fallback
for (Map.Entry<String, Object> entry : candidates.entrySet()) {
String candidateName = entry.getKey();
Object beanInstance = entry.getValue();
if ((beanInstance != null && this.resolvableDependencies.containsValue(beanInstance)) ||
matchesBeanName(candidateName, descriptor.getDependencyName())) {
return candidateName;
}
}
return null;
}
如代码所示,优先级的决策是先根据 @Primary 来决策,其次是 @Priority 决策,最后是根据 Bean 名字的严格匹配来决策。如果这些帮助决策优先级的注解都没有被使用,名字也不精确匹配,则返回 null,告知无法决策出哪种最合适。
- @Autowired 要求是必须注入的(即 required 保持默认值为 true),或者注解的属性类型并不是可以接受多个 Bean 的类型,例如数组、Map、集合。这点可以参考 DefaultListableBeanFactory#indicatesMultipleBeans 的实现:
private boolean indicatesMultipleBeans(Class<?> type) {
return (type.isArray() || (type.isInterface() &&
(Collection.class.isAssignableFrom(type) || Map.class.isAssignableFrom(type))));
}
对比上述两个条件和我们的案例,很明显,案例程序能满足这些条件,所以报错并不奇怪。而如果我们把这些条件想得简单点,或许更容易帮助我们去理解这个设计。就像我们遭遇多个无法比较优劣的选择,却必须选择其一时,与其偷偷地随便选择一种,还不如直接报错,起码可以避免更严重的问题发生。
问题修正
针对这个案例,有了源码的剖析,我们可以很快找到解决问题的方法:打破上述两个条件中的任何一个即可,即让候选项具有优先级或压根可以不去选择。不过需要你注意的是,不是每一种条件的打破都满足实际需求,例如我们可以通过使用标记 @Primary 的方式来让被标记的候选者有更高优先级,从而避免报错,但是它并不一定符合业务需求,这就好比我们本身需要两种数据库都能使用,而不是顾此失彼。
@Repository
@Primary
@Slf4j
public class OracleDataService implements DataService{
//省略非关键代码
}
现在,请你仔细研读上述的两个条件,要同时支持多种 DataService,且能在不同业务情景下精确匹配到要选择到的 DataService,我们可以使用下面的方式去修改:
@Autowired
DataService oracleDataService;
如代码所示,修改方式的精髓在于将属性名和 Bean 名字精确匹配,这样就可以让注入选择不犯难:需要 Oracle 时指定属性名为 oracleDataService,需要 Cassandra 时则指定属性名为 cassandraDataService。
案例 2:显式引用 Bean 时首字母忽略大小写
针对案例 1 的问题修正,实际上还存在另外一种常用的解决办法,即采用 @Qualifier 来显式指定引用的是那种服务,例如采用下面的方式:
@Autowired()
@Qualifier("cassandraDataService")
DataService dataService;
这种方式之所以能解决问题,在于它能让寻找出的 Bean 只有一个(即精确匹配),所以压根不会出现后面的决策过程,可以参考 DefaultListableBeanFactory#doResolveDependency:
@Nullable
public Object doResolveDependency(DependencyDescriptor descriptor, @Nullable String beanName,
@Nullable Set<String> autowiredBeanNames, @Nullable TypeConverter typeConverter) throws BeansException {
//省略其他非关键代码
//寻找bean过程
Map<String, Object> matchingBeans = findAutowireCandidates(beanName, type, descriptor);
if (matchingBeans.isEmpty()) {
if (isRequired(descriptor)) {
raiseNoMatchingBeanFound(type, descriptor.getResolvableType(), descriptor);
}
return null;
}
//省略其他非关键代码
if (matchingBeans.size() > 1) {
//省略多个bean的决策过程,即案例1重点介绍内容
}
//省略其他非关键代码
}
我们会使用 @Qualifier 指定的名称去匹配,最终只找到了唯一一个。不过在使用 @Qualifier 时,我们有时候会犯另一个经典的小错误,就是我们可能会忽略 Bean 的名称首字母大小写。这里我们把校正后的案例稍稍变形如下:
@Autowired
@Qualifier("CassandraDataService")
DataService dataService;
运行程序,我们会报错如下:
Exception encountered during context initialization - cancelling refresh attempt: org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name ‘studentController’: Unsatisfied dependency expressed through field ‘dataService’; nested exception is org.springframework.beans.factory.NoSuchBeanDefinitionException: No qualifying bean of type ‘com.spring.puzzle.class2.example2.DataService’ available: expected at least 1 bean which qualifies as autowire candidate. Dependency annotations: {@org.springframework.beans.factory.annotation.Autowired(required=true), @org.springframework.beans.factory.annotation.Qualifier(value=CassandraDataService)}
这里我们很容易得出一个结论:对于 Bean 的名字,如果没有显式指明,就应该是类名,不过首字母应该小写。但是这个轻松得出的结论成立么?
不妨再测试下,假设我们需要支持 SQLite 这种数据库,我们定义了一个命名为 SQLiteDataService 的实现,然后借鉴之前的经验,我们很容易使用下面的代码来引用这个实现:
@Autowired
@Qualifier("sQLiteDataService")
DataService dataService;
满怀信心运行完上面的程序,依然会出现之前的错误,而如果改成 SQLiteDataService,则运行通过了。这和之前的结论又矛盾了。所以,显式引用 Bean 时,首字母到底是大写还是小写呢?
案例解析
对于这种错误的报错位置,其实我们正好在本案例的开头就贴出了(即第二段代码清单的第 9 行):
raiseNoMatchingBeanFound(type, descriptor.getResolvableType(), descriptor);
即当因为名称问题(例如引用 Bean 首字母搞错了)找不到 Bean 时,会直接抛出 NoSuchBeanDefinitionException。
在这里,我们真正需要关心的问题是:不显式设置名字的 Bean,其默认名称首字母到底是大写还是小写呢?
看案例的话,当我们启动基于 Spring Boot 的应用程序时,会自动扫描我们的 Package,以找出直接或间接标记了 @Component 的 Bean 的定义(即 BeanDefinition)。例如 CassandraDataService、SQLiteDataService 都被标记了 @Repository,而 Repository 本身被 @Component 标记,所以它们都是间接标记了 @Component。
一旦找出这些 Bean 的信息,就可以生成这些 Bean 的名字,然后组合成一个个 BeanDefinitionHolder 返回给上层。这个过程关键步骤可以查看下图的代码片段(ClassPathBeanDefinitionScanner#doScan):
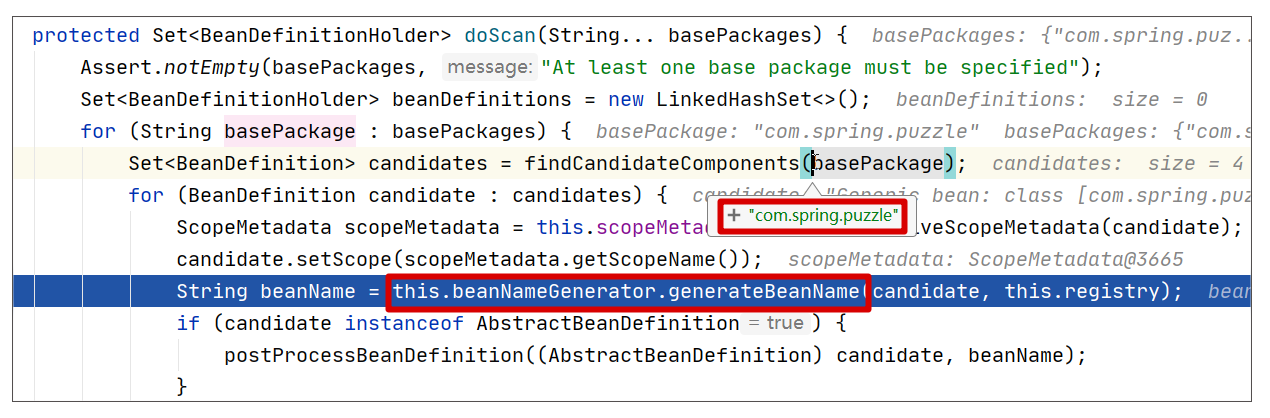
基本匹配我们前面描述的过程,其中方法调用 BeanNameGenerator#generateBeanName 即用来产生 Bean 的名字,它有两种实现方式。因为 DataService 的实现都是使用注解标记的,所以 Bean 名称的生成逻辑最终调用的其实是 AnnotationBeanNameGenerator#generateBeanName 这种实现方式,我们可以看下它的具体实现,代码如下:
@Override
public String generateBeanName(BeanDefinition definition, BeanDefinitionRegistry registry) {
if (definition instanceof AnnotatedBeanDefinition) {
String beanName = determineBeanNameFromAnnotation((AnnotatedBeanDefinition) definition);
if (StringUtils.hasText(beanName)) {
// Explicit bean name found.
return beanName;
}
}
// Fallback: generate a unique default bean name.
return buildDefaultBeanName(definition, registry);
}
大体流程只有两步:看 Bean 有没有显式指明名称,如果有则用显式名称,如果没有则产生一个默认名称。很明显,在我们的案例中,是没有给 Bean 指定名字的,所以产生的 Bean 的名称就是生成的默认名称,查看默认名的产生方法 buildDefaultBeanName,其实现如下:
protected String buildDefaultBeanName(BeanDefinition definition) {
String beanClassName = definition.getBeanClassName();
Assert.state(beanClassName != null, "No bean class name set");
String shortClassName = ClassUtils.getShortName(beanClassName);
return Introspector.decapitalize(shortClassName);
}
首先,获取一个简短的 ClassName,然后调用 Introspector#decapitalize 方法,设置首字母大写或小写,具体参考下面的代码实现:
public static String decapitalize(String name) {
if (name == null || name.length() == 0) {
return name;
}
if (name.length() > 1 && Character.isUpperCase(name.charAt(1)) &&
Character.isUpperCase(name.charAt(0))){
return name;
}
char chars[] = name.toCharArray();
chars[0] = Character.toLowerCase(chars[0]);
return new String(chars);
}
到这,我们很轻松地明白了前面两个问题出现的原因:如果一个类名是以两个大写字母开头的,则首字母不变,其它情况下默认首字母变成小写。结合我们之前的案例,SQLiteDataService 的 Bean,其名称应该就是类名本身,而 CassandraDataService 的 Bean 名称则变成了首字母小写(cassandraDataService)。
问题修正
现在我们已经从源码级别了解了 Bean 名字产生的规则,就可以很轻松地修正案例中的两个错误了。以引用 CassandraDataService 类型的 Bean 的错误修正为例,可以采用下面这两种修改方式:
- 引用处纠正首字母大小写问题:
@Autowired
@Qualifier("cassandraDataService")
DataService dataService;
- 定义处显式指定 Bean 名字,我们可以保持引用代码不变,而通过显式指明 CassandraDataService 的 Bean 名称为 CassandraDataService 来纠正这个问题。
@Repository("CassandraDataService")
@Slf4j
public class CassandraDataService implements DataService {
//省略实现
}
现在,我们的程序就可以精确匹配到要找的 Bean 了。比较一下这两种修改方法的话,如果你不太了解源码,不想纠结于首字母到底是大写还是小写,建议你用第二种方法去避免困扰。
案例 3:引用内部类的 Bean 遗忘类名
解决完案例 2,是不是就意味着我们能搞定所有 Bean 的显式引用,不再犯错了呢?天真了。我们可以沿用上面的案例,稍微再添加点别的需求,例如我们需要定义一个内部类来实现一种新的 DataService,代码如下:
public class StudentController {
@Repository
public static class InnerClassDataService implements DataService{
@Override
public void deleteStudent(int id) {
//空实现
}
}
//省略其他非关键代码
}
遇到这种情况,我们一般都会很自然地用下面的方式直接去显式引用这个 Bean:
@Autowired
@Qualifier("innerClassDataService")
DataService innerClassDataService;
很明显,有了案例 2 的经验,我们上来就直接采用了首字母小写以避免案例 2 中的错误,但这样的代码是不是就没问题了呢?实际上,仍然会报错“找不到 Bean”,这是为什么?
案例解析
实际上,我们遭遇的情况是“如何引用内部类的 Bean”。解析案例 2 的时候,我曾经贴出了如何产生默认 Bean 名的方法(即 AnnotationBeanNameGenerator#buildDefaultBeanName),当时我们只关注了首字母是否小写的代码片段,而在最后变换首字母之前,有一行语句是对 class 名字的处理,代码如下:
String shortClassName = ClassUtils.getShortName(beanClassName);
我们可以看下它的实现,参考 ClassUtils#getShortName 方法:
public static String getShortName(String className) {
Assert.hasLength(className, "Class name must not be empty");
int lastDotIndex = className.lastIndexOf(PACKAGE_SEPARATOR);
int nameEndIndex = className.indexOf(CGLIB_CLASS_SEPARATOR);
if (nameEndIndex == -1) {
nameEndIndex = className.length();
}
String shortName = className.substring(lastDotIndex + 1, nameEndIndex);
shortName = shortName.replace(INNER_CLASS_SEPARATOR, PACKAGE_SEPARATOR);
return shortName;
}
很明显,假设我们是一个内部类,例如下面的类名:
com.spring.puzzle.class2.example3.StudentController.InnerClassDataService
在经过这个方法的处理后,我们得到的其实是下面这个名称:
StudentController.InnerClassDataService
最后经过 Introspector.decapitalize 的首字母变换,最终获取的 Bean 名称如下:
studentController.InnerClassDataService
所以我们在案例程序中,直接使用 innerClassDataService 自然找不到想要的 Bean。
问题修正
通过案例解析,我们很快就找到了这个内部类,Bean 的引用问题顺手就修正了,如下:
@Autowired
@Qualifier("studentController.InnerClassDataService")
DataService innerClassDataService;
这个引用看起来有些许奇怪,但实际上是可以工作的,反而直接使用 innerClassDataService 来引用倒是真的不可行。
通过这个案例我们可以看出,对源码的学习是否全面决定了我们以后犯错的可能性大小。如果我们在学习案例 2 时,就对 class 名称的变化部分的源码进行了学习,那么这种错误是不容易犯的。不过有时候我们确实很难一上来就把学习开展的全面而深入,总是需要时间和错误去锤炼的。
上面介绍了 3 个 Spring 编程中关于依赖注入的错误案例,这些错误都是比较常见的。如果你仔细分析的话,你会发现它们大多都是围绕着 @Autowired、@Qualifier 的使用而发生,而且自动注入的类型也都是普通对象类型。
那在实际应用中,我们也会使用 @Value 等不太常见的注解来完成自动注入,同时也存在注入到集合、数组等复杂类型的场景。这些情况下,我们也会遇到一些问题。所以这一讲我们不妨来梳理下。
案例 1:@Value 没有注入预期的值
在装配对象成员属性时,我们常常会使用 @Autowired 来装配。但是,有时候我们也使用 @Value 进行装配。不过这两种注解使用风格不同,使用 @Autowired 一般都不会设置属性值,而 @Value 必须指定一个字符串值,因为其定义做了要求,定义代码如下:
public @interface Value {
/**
* The actual value expression — for example, <code>#{systemProperties.myProp}</code>.
*/
String value();
}
另外在比较这两者的区别时,我们一般都会因为 @Value 常用于 String 类型的装配而误以为 @Value 不能用于非内置对象的装配,实际上这是一个常见的误区。例如,我们可以使用下面这种方式来 Autowired 一个属性成员:
@Value("#{student}")
private Student student;
其中 student 这个 Bean 定义如下:
@Bean
public Student student(){
Student student = createStudent(1, "xie");
return student;
}
当然,正如前面提及,我们使用 @Value 更多是用来装配 String,而且它支持多种强大的装配方式,典型的方式参考下面的示例:
//注册正常字符串
@Value("我是字符串")
private String text;
//注入系统参数、环境变量或者配置文件中的值
@Value("${ip}")
private String ip
//注入其他Bean属性,其中student为bean的ID,name为其属性
@Value("#{student.name}")
private String name;
上面我给你简单介绍了 @Value 的强大功能,以及它和 @Autowired 的区别。那么在使用 @Value 时可能会遇到那些错误呢?这里分享一个最为典型的错误,即使用 @Value 可能会注入一个不是预期的值。
我们可以模拟一个场景,我们在配置文件 application.properties 配置了这样一个属性:
username=admin
password=pass
然后我们在一个 Bean 中,分别定义两个属性来引用它们:
@RestController
@Slf4j
public class ValueTestController {
@Value("${username}")
private String username;
@Value("${password}")
private String password;
@RequestMapping(path = "user", method = RequestMethod.GET)
public String getUser(){
return username + ":" + password;
};
}
当我们去打印上述代码中的 username 和 password 时,我们会发现 password 正确返回了,但是 username 返回的并不是配置文件中指明的 admin,而是运行这段程序的计算机用户名。很明显,使用 @Value 装配的值没有完全符合我们的预期。
案例解析
通过分析运行结果,我们可以知道 @Value 的使用方式应该是没有错的,毕竟 password 这个字段装配上了,但是为什么 username 没有生效成正确的值?接下来我们就来具体解析下。
我们首先了解下对于 @Value,Spring 是如何根据 @Value 来查询“值”的。我们可以先通过方法 DefaultListableBeanFactory#doResolveDependency 来了解 @Value 的核心工作流程,代码如下:
@Nullable
public Object doResolveDependency(DependencyDescriptor descriptor, @Nullable String beanName,
@Nullable Set<String> autowiredBeanNames, @Nullable TypeConverter typeConverter) throws BeansException {
//省略其他非关键代码
Class<?> type = descriptor.getDependencyType();
//寻找@Value
Object value = getAutowireCandidateResolver().getSuggestedValue(descriptor);
if (value != null) {
if (value instanceof String) {
//解析Value值
String strVal = resolveEmbeddedValue((String) value);
BeanDefinition bd = (beanName != null && containsBean(beanName) ?
getMergedBeanDefinition(beanName) : null);
value = evaluateBeanDefinitionString(strVal, bd);
}
//转化Value解析的结果到装配的类型
TypeConverter converter = (typeConverter != null ? typeConverter : getTypeConverter());
try {
return converter.convertIfNecessary(value, type, descriptor.getTypeDescriptor());
}
catch (UnsupportedOperationException ex) {
//异常处理
}
}
//省略其他非关键代码
}
可以看到,@Value 的工作大体分为以下三个核心步骤。
- 寻找 @Value
在这步中,主要是判断这个属性字段是否标记为 @Value,依据的方法参考 QualifierAnnotationAutowireCandidateResolver#findValue:
@Nullable
protected Object findValue(Annotation[] annotationsToSearch) {
if (annotationsToSearch.length > 0) {
AnnotationAttributes attr = AnnotatedElementUtils.getMergedAnnotationAttributes(
AnnotatedElementUtils.forAnnotations(annotationsToSearch), this.valueAnnotationType);
//valueAnnotationType即为@Value
if (attr != null) {
return extractValue(attr);
}
}
return null;
}
- 解析 @Value 的字符串值
如果一个字段标记了 @Value,则可以拿到对应的字符串值,然后就可以根据字符串值去做解析,最终解析的结果可能是一个字符串,也可能是一个对象,这取决于字符串怎么写。
- 将解析结果转化为要装配的对象的类型
当拿到第二步生成的结果后,我们会发现可能和我们要装配的类型不匹配。假设我们定义的是 UUID,而我们获取的结果是一个字符串,那么这个时候就会根据目标类型来寻找转化器执行转化,字符串到 UUID 的转化实际上发生在 UUIDEditor 中:
public class UUIDEditor extends PropertyEditorSupport {
@Override
public void setAsText(String text) throws IllegalArgumentException {
if (StringUtils.hasText(text)) {
//转化操作
setValue(UUID.fromString(text.trim()));
}
else {
setValue(null);
}
}
//省略其他非关代码
}
通过对上面几个关键步骤的解析,我们大体了解了 @Value 的工作流程。结合我们的案例,很明显问题应该发生在第二步,即解析 Value 指定字符串过程,执行过程参考下面的关键代码行:
String strVal = resolveEmbeddedValue((String) value);
这里其实是在解析嵌入的值,实际上就是“替换占位符”工作。具体而言,它采用的是 PropertySourcesPlaceholderConfigurer 根据 PropertySources 来替换。不过当使用 ${username} 来获取替换值时,其最终执行的查找并不是局限在 application.property 文件中的。通过调试,我们可以看到下面的这些“源”都是替换依据:

[ConfigurationPropertySourcesPropertySource {name='configurationProperties'}, StubPropertySource {name='servletConfigInitParams'}, ServletContextPropertySource {name='servletContextInitParams'}, PropertiesPropertySource {name='systemProperties'}, OriginAwareSystemEnvironmentPropertySource {name='systemEnvironment'}, RandomValuePropertySource {name='random'},OriginTrackedMapPropertySource {name='applicationConfig: classpath:/application.properties]'},MapPropertySource {name='devtools'}]
而具体的查找执行,我们可以通过下面的代码(PropertySourcesPropertyResolver#getProperty)来获取它的执行方式:
@Nullable
protected <T> T getProperty(String key, Class<T> targetValueType, boolean resolveNestedPlaceholders) {
if (this.propertySources != null) {
for (PropertySource<?> propertySource : this.propertySources) {
Object value = propertySource.getProperty(key);
if (value != null) {
//查到value即退出
return convertValueIfNecessary(value, targetValueType);
}
}
}
return null;
}
从这可以看出,在解析 Value 字符串时,其实是有顺序的(查找的源是存在 CopyOnWriteArrayList 中,在启动时就被有序固定下来),一个一个“源”执行查找,在其中一个源找到后,就可以直接返回了。
如果我们查看 systemEnvironment 这个源,会发现刚好有一个 username 和我们是重合的,且值不是 pass。
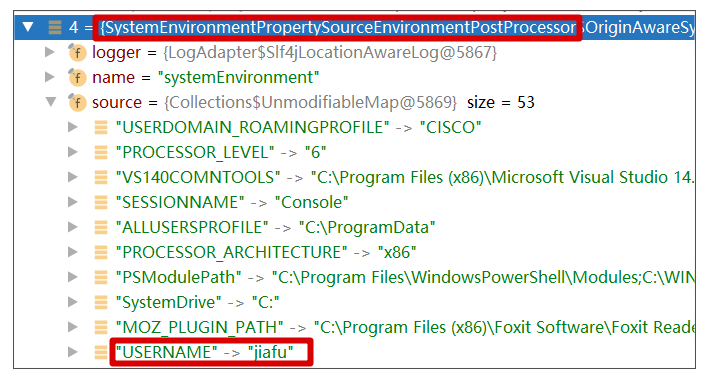
所以,讲到这里,你应该知道问题所在了吧?这是一个误打误撞的例子,刚好系统环境变量(systemEnvironment)中含有同名的配置。实际上,对于系统参数(systemProperties)也是一样的,这些参数或者变量都有很多,如果我们没有意识到它的存在,起了一个同名的字符串作为 @Value 的值,则很容易引发这类问题。
问题修正
针对这个案例,有了源码的剖析,我们就可以很快地找到解决方案了。例如我们可以避免使用同一个名称,具体修改如下:
user.name=admin
user.password=pass
但是如果我们这么改的话,其实还是不行的。实际上,通过之前的调试方法,我们可以找到类似的原因,在 systemProperties 这个 PropertiesPropertySource 源中刚好存在 user.name,真是无巧不成书。所以命名时,我们一定要注意不仅要避免和环境变量冲突,也要注意避免和系统变量等其他变量冲突,这样才能从根本上解决这个问题。
通过这个案例,我们可以知道:Spring 给我们提供了很多好用的功能,但是这些功能交织到一起后,就有可能让我们误入一些坑,只有了解它的运行方式,我们才能迅速定位问题、解决问题。
案例 2:错乱的注入集合
前面我们介绍了很多自动注入的错误案例,但是这些案例都局限在单个类型的注入,对于集合类型的注入并无提及。实际上,集合类型的自动注入是 Spring 提供的另外一个强大功能。
假设我们存在这样一个需求:存在多个学生 Bean,我们需要找出来,并存储到一个 List 里面去。多个学生 Bean 的定义如下:
@Bean
public Student student1(){
return createStudent(1, "xie");
}
@Bean
public Student student2(){
return createStudent(2, "fang");
}
private Student createStudent(int id, String name) {
Student student = new Student();
student.setId(id);
student.setName(name);
return student;
}
有了集合类型的自动注入后,我们就可以把零散的学生 Bean 收集起来了,代码示例如下:
@RestController
@Slf4j
public class StudentController {
private List<Student> students;
public StudentController(List<Student> students){
this.students = students;
}
@RequestMapping(path = "students", method = RequestMethod.GET)
public String listStudents(){
return students.toString();
};
}
通过上述代码,我们就可以完成集合类型的注入工作,输出结果如下:
[Student(id=1, name=xie), Student(id=2, name=fang)]
然而,业务总是复杂的,需求也是一直变动的。当我们持续增加一些 student 时,可能就不喜欢用这种方式来注入集合类型了,而是倾向于用下面的方式去完成注入工作:
@Bean
public List<Student> students(){
Student student3 = createStudent(3, "liu");
Student student4 = createStudent(4, "fu");
return Arrays.asList(student3, student4);
}
为了好记,这里我们不妨将上面这种方式命名为“直接装配方式”,而将之前的那种命名为“收集方式”。
实际上,如果这两种方式是非此即彼的存在,自然没有任何问题,都能玩转。但是如果我们不小心让这 2 种方式同时存在了,结果会怎样?
这时候很多人都会觉得 Spring 很强大,肯定会合并上面的结果,或者认为肯定是以直接装配结果为准。然而,当我们运行起程序,就会发现后面的注入方式根本没有生效。即依然返回的是前面定义的 2 个学生。为什么会出现这样的错误呢?
案例解析
要了解这个错误的根本原因,你就得先清楚这两种注入风格在 Spring 中是如何实现的。对于收集装配风格,Spring 使用的是 DefaultListableBeanFactory#resolveMultipleBeans 来完成装配工作,针对本案例关键的核心代码如下:
private Object resolveMultipleBeans(DependencyDescriptor descriptor, @Nullable String beanName,
@Nullable Set<String> autowiredBeanNames, @Nullable TypeConverter typeConverter) {
final Class<?> type = descriptor.getDependencyType();
if (descriptor instanceof StreamDependencyDescriptor) {
//装配stream
return stream;
}
else if (type.isArray()) {
//装配数组
return result;
}
else if (Collection.class.isAssignableFrom(type) && type.isInterface()) {
//装配集合
//获取集合的元素类型
Class<?> elementType = descriptor.getResolvableType().asCollection().resolveGeneric();
if (elementType == null) {
return null;
}
//根据元素类型查找所有的bean
Map<String, Object> matchingBeans = findAutowireCandidates(beanName, elementType,
new MultiElementDescriptor(descriptor));
if (matchingBeans.isEmpty()) {
return null;
}
if (autowiredBeanNames != null) {
autowiredBeanNames.addAll(matchingBeans.keySet());
}
//转化查到的所有bean放置到集合并返回
TypeConverter converter = (typeConverter != null ? typeConverter : getTypeConverter());
Object result = converter.convertIfNecessary(matchingBeans.values(), type);
//省略非关键代码
return result;
}
else if (Map.class == type) {
//解析map
return matchingBeans;
}
else {
return null;
}
}
到这,我们就不难概括出这种收集式集合装配方式的大体过程了。
- 获取集合类型的元素类型
针对本案例,目标类型定义为 List students,所以元素类型为 Student,获取的具体方法参考代码行:
Class elementType = descriptor.getResolvableType().asCollection().resolveGeneric();
- 根据元素类型,找出所有的 Bean
有了上面的元素类型,即可根据元素类型来找出所有的 Bean,关键代码行如下:
Map matchingBeans = findAutowireCandidates(beanName, elementType, new MultiElementDescriptor(descriptor));
- 将匹配的所有的 Bean 按目标类型进行转化
经过步骤 2,我们获取的所有的 Bean 都是以 java.util.LinkedHashMap.LinkedValues 形式存储的,和我们的目标类型大概率不同,所以最后一步需要做的是按需转化。在本案例中,我们就需要把它转化为 List,转化的关键代码如下:
Object result = converter.convertIfNecessary(matchingBeans.values(), type);
如果我们继续深究执行细节,就可以知道最终是转化器 CollectionToCollectionConverter 来完成这个转化过程。
学习完收集方式的装配原理,我们再来看下直接装配方式的执行过程,实际上这步在前面的课程中我们就提到过(即 DefaultListableBeanFactory#findAutowireCandidates 方法执行),具体的执行过程这里就不多说了。
知道了执行过程,接下来无非就是根据目标类型直接寻找匹配的 Bean。在本案例中,就是将 Bean 名称为 students 的 List 装配给 StudentController#students 属性。
了解了这两种方式,我们再来思考这两种方式的关系:当同时满足这两种装配方式时,Spring 是如何处理的?这里我们可以参考方法 DefaultListableBeanFactory#doResolveDependency 的几行关键代码,代码如下:
Object multipleBeans = resolveMultipleBeans(descriptor, beanName, autowiredBeanNames, typeConverter);
if (multipleBeans != null) {
return multipleBeans;
}
Map<String, Object> matchingBeans = findAutowireCandidates(beanName, type, descriptor);
很明显,这两种装配集合的方式是不能同存的,结合本案例,当使用收集装配方式来装配时,能找到任何一个对应的 Bean,则返回,如果一个都没有找到,才会采用直接装配的方式。说到这里,你大概能理解为什么后期以 List 方式直接添加的 Student Bean 都不生效了吧。
问题修正
现在如何纠正这个问题就变得简单多了,就是你一定要下意识地避免这 2 种方式共存去装配集合,只用一个这个问题就迎刃而解了。例如,在这里,我们可以使用直接装配的方式去修正问题,代码如下:
@Bean
public List<Student> students(){
Student student1 = createStudent(1, "xie");
Student student2 = createStudent(2, "fang");
Student student3 = createStudent(3, "liu");
Student student4 = createStudent(4, "fu");
return Arrays.asList(student1,student2,student3, student4);
}
也可以使用收集方式来修正问题时,代码如下:
@Bean
public Student student1(){
return createStudent(1, "xie");
}
@Bean
public Student student2(){
return createStudent(2, "fang");
}
@Bean
public Student student3(){
return createStudent(3, "liu");
}
@Bean
public Student student4(){
return createStudent(4, "fu");
}
总之,都是可以的。还有一点要注意:在对于同一个集合对象的注入上,混合多种注入方式是不可取的,这样除了错乱,别无所得。
04|Spring Bean 生命周期常见错误 #
虽然说 Spring 容器上手简单,可以仅仅通过学习一些有限的注解,即可达到快速使用的目的。但在工程实践中,我们依然会从中发现一些常见的错误。尤其当你对 Spring 的生命周期还没有深入了解时,类初始化及销毁过程中潜在的约定就不会很清楚。
这会导致这样一些状况发生:有些错误,我们可以在 Spring 的异常提示下快速解决,但却不理解背后的原理;而另一些错误,并不容易在开发环境下被发现,从而在产线上造成较为严重的后果。
接下来我们就具体解析下这些常见案例及其背后的原理。
案例 1:构造器内抛空指针异常
先看个例子。在构建宿舍管理系统时,有 LightMgrService 来管理 LightService,从而控制宿舍灯的开启和关闭。我们希望在 LightMgrService 初始化时能够自动调用 LightService 的 check 方法来检查所有宿舍灯的电路是否正常,代码如下:
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
@Component
public class LightMgrService {
@Autowired
private LightService lightService;
public LightMgrService() {
lightService.check();
}
}
我们在 LightMgrService 的默认构造器中调用了通过 @Autoware 注入的成员变量 LightService 的 check 方法:
@Service
public class LightService {
public void start() {
System.out.println("turn on all lights");
}
public void shutdown() {
System.out.println("turn off all lights");
}
public void check() {
System.out.println("check all lights");
}
}
以上代码定义了 LightService 对象的原始类。
从整个案例代码实现来看,我们的期待是在 LightMgrService 初始化过程中,LightService 因为标记为 @Autowired,所以能被自动装配好;然后在 LightMgrService 的构造器执行中,LightService 的 check 方法能被自动调用;最终打印出 check all lights。
然而事与愿违,我们得到的只会是 NullPointerException,错误示例如下:

这是为什么呢?
案例解析
显然这是新手最常犯的错误,但是问题的根源,是我们对 Spring 类初始化过程没有足够的了解。下面这张时序图描述了 Spring 启动时的一些关键结点:
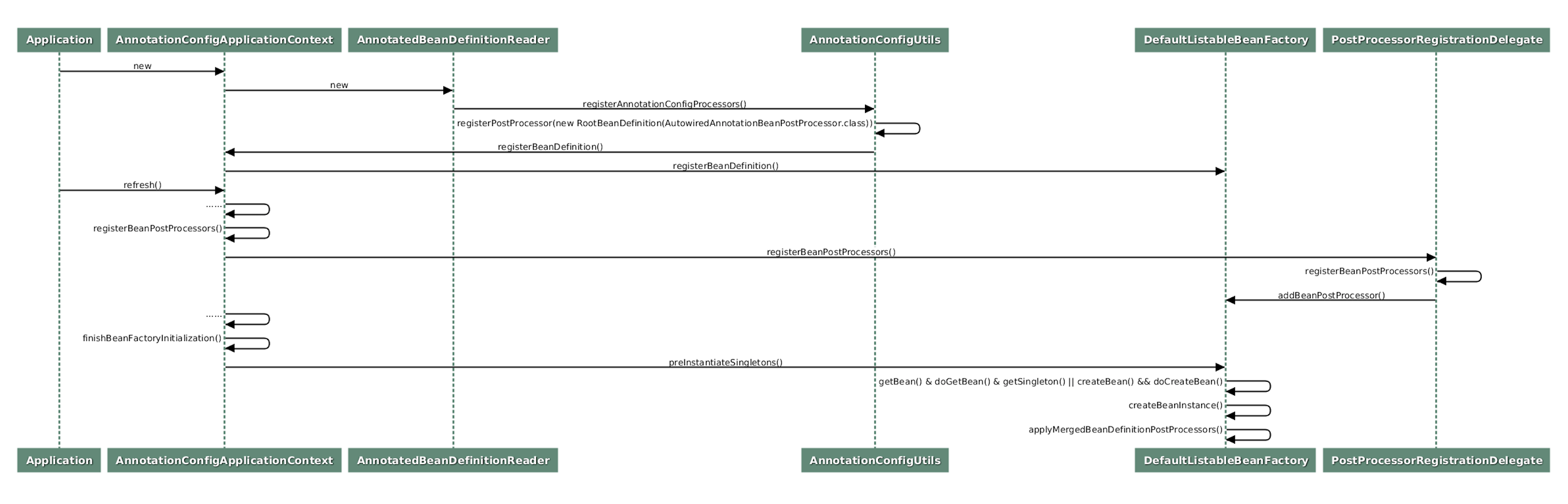
这个图初看起来复杂,我们不妨将其分为三部分:
- 第一部分,将一些必要的系统类,比如 Bean 的后置处理器类,注册到 Spring 容器,其中就包括接下来要讲到的 CommonAnnotationBeanPostProcessor 类;
- 第二部分,将这些后置处理器实例化,并注册到 Spring 的容器中;
- 第三部分,实例化所有用户定制类,调用后置处理器进行辅助装配、类初始化等等。
第一部分和第二部分并非是我们今天要讨论的重点,这里仅仅是为了让你知道 CommonAnnotationBeanPostProcessor 这个后置处理类是何时被 Spring 加载和实例化的。
请先学习 Spring中Bean的生命周期
这里我顺便给你拓展两个知识点:
- 很多必要的系统类,尤其是 Bean 后置处理器(比如 CommonAnnotationBeanPostProcessor、AutowiredAnnotationBeanPostProcessor 等),都是被 Spring 统一加载和管理的,并在 Spring 中扮演了非常重要的角色;
- 通过 Bean 后置处理器,Spring 能够非常灵活地在不同的场景调用不同的后置处理器,比如接下来我会讲到示例问题如何修正,修正方案中提到的 PostConstruct 注解,它的处理逻辑就需要用到 CommonAnnotationBeanPostProcessor(继承自 InitDestroyAnnotationBeanPostProcessor)这个后置处理器。
现在我们重点看下第三部分,即 Spring 初始化单例类的一般过程,基本都是 getBean()->doGetBean()->getSingleton(),如果发现 Bean 不存在,则调用 createBean()->doCreateBean() 进行实例化。
查看 doCreateBean() 的源代码如下:
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final @Nullable Object[] args)
throws BeanCreationException {
//省略非关键代码
if (instanceWrapper == null) {
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
final Object bean = instanceWrapper.getWrappedInstance();
//省略非关键代码
Object exposedObject = bean;
try {
populateBean(beanName, mbd, instanceWrapper);
exposedObject = initializeBean(beanName, exposedObject, mbd);
}
catch (Throwable ex) {
//省略非关键代码
}
上述代码完整地展示了 Bean 初始化的三个关键步骤,按执行顺序分别是第 5 行的 createBeanInstance,第 12 行的 populateBean,以及第 13 行的 initializeBean,分别对应实例化 Bean,注入 Bean 依赖,以及初始化 Bean (例如执行 @PostConstruct 标记的方法 )这三个功能,这也和上述时序图的流程相符。
而用来实例化 Bean 的 createBeanInstance 方法通过依次调用 DefaultListableBeanFactory.instantiateBean() >SimpleInstantiationStrategy.instantiate(),最终执行到 BeanUtils.instantiateClass(),其代码如下:
public static <T> T instantiateClass(Constructor<T> ctor, Object... args) throws BeanInstantiationException {
Assert.notNull(ctor, "Constructor must not be null");
try {
ReflectionUtils.makeAccessible(ctor);
return (KotlinDetector.isKotlinReflectPresent() && KotlinDetector.isKotlinType(ctor.getDeclaringClass()) ?
KotlinDelegate.instantiateClass(ctor, args) : ctor.newInstance(args));
}
catch (InstantiationException ex) {
throw new BeanInstantiationException(ctor, "Is it an abstract class?", ex);
}
//省略非关键代码
}
这里因为当前的语言并非 Kotlin,所以最终将调用 ctor.newInstance() 方法实例化用户定制类 LightMgrService,而默认构造器显然是在类实例化的时候被自动调用的,Spring 也无法控制。而此时负责自动装配的 populateBean 方法还没有被执行,LightMgrService 的属性 LightService 还是 null,因而得到空指针异常也在情理之中。
问题修正
通过源码分析,现在我们知道了问题的根源,就是在于使用 @Autowired 直接标记在成员属性上而引发的装配行为是发生在构造器执行之后的。所以这里我们可以通过下面这种修订方法来纠正这个问题:
@Component
public class LightMgrService {
private LightService lightService;
public LightMgrService(LightService lightService) {
this.lightService = lightService;
lightService.check();
}
}
当使用上面的代码时,构造器参数 LightService 会被自动注入 LightService 的 Bean,从而在构造器执行时,不会出现空指针。可以说,使用构造器参数来隐式注入是一种 Spring 最佳实践,因为它成功地规避了案例 1 中的问题。
另外,除了这种纠正方式,有没有别的方式?
实际上,Spring 在类属性完成注入之后,会回调用户定制的初始化方法。即在 populateBean 方法之后,会调用 initializeBean 方法,我们来看一下它的关键代码:
protected Object initializeBean(final String beanName, final Object bean, @Nullable RootBeanDefinition mbd) {
//省略非关键代码
if (mbd == null || !mbd.isSynthetic()) {
wrappedBean = applyBeanPostProcessorsBeforeInitialization(wrappedBean, beanName);
}
try {
invokeInitMethods(beanName, wrappedBean, mbd);
}
//省略非关键代码
}
这里你可以看到 applyBeanPostProcessorsBeforeInitialization 和 invokeInitMethods 这两个关键方法的执行,它们分别处理了 @PostConstruct 注解和 InitializingBean 接口这两种不同的初始化方案的逻辑。这里我再详细地给你讲讲。
- applyBeanPostProcessorsBeforeInitialization 与 @PostConstruct
applyBeanPostProcessorsBeforeInitialization 方法最终执行到后置处理器 InitDestroyAnnotationBeanPostProcessor 的 buildLifecycleMetadata 方法(CommonAnnotationBeanPostProcessor 的父类):
private LifecycleMetadata buildLifecycleMetadata(final Class<?> clazz) {
//省略非关键代码
do {
//省略非关键代码
final List<LifecycleElement> currDestroyMethods = new ArrayList<>();
ReflectionUtils.doWithLocalMethods(targetClass, method -> {
//此处的 this.initAnnotationType 值,即为 PostConstruct.class
if (this.initAnnotationType != null && method.isAnnotationPresent(this.initAnnotationType)) {
LifecycleElement element = new LifecycleElement(method);
currInitMethods.add(element);
//非关键代码
}
在这个方法里,Spring 将遍历查找被 PostConstruct.class 注解过的方法,返回到上层,并最终调用此方法。
- invokeInitMethods 与 InitializingBean 接口
invokeInitMethods 方法会判断当前 Bean 是否实现了 InitializingBean 接口,只有在实现了该接口的情况下,Spring 才会调用该 Bean 的接口实现方法 afterPropertiesSet()。
protected void invokeInitMethods(String beanName, final Object bean, @Nullable RootBeanDefinition mbd)
throws Throwable {
boolean isInitializingBean = (bean instanceof InitializingBean);
if (isInitializingBean && (mbd == null || !mbd.isExternallyManagedInitMethod("afterPropertiesSet"))) {
// 省略非关键代码
else {
((InitializingBean) bean).afterPropertiesSet();
}
}
// 省略非关键代码
}
学到此处,答案也就呼之欲出了。我们还有两种方式可以解决此问题。
- 添加 init 方法,并且使用 PostConstruct 注解进行修饰:
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
@Component
public class LightMgrService {
@Autowired
private LightService lightService;
@PostConstruct
public void init() {
lightService.check();
}
}
- 实现 InitializingBean 接口,在其 afterPropertiesSet() 方法中执行初始化代码:
import org.springframework.beans.factory.InitializingBean;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
@Component
public class LightMgrService implements InitializingBean {
@Autowired
private LightService lightService;
@Override
public void afterPropertiesSet() throws Exception {
lightService.check();
}
}
案例 2:意外触发 shutdown 方法
上述实例我给你讲解了类初始化时最容易遇到的问题,同样,在类销毁时,也会有一些相对隐蔽的约定,导致一些难以察觉的错误。
接下来,我们再来看一个案例,还是沿用之前的场景。这里我们可以简单复习一下 LightService 的实现,它包含了 shutdown 方法,负责关闭所有的灯,关键代码如下:
import org.springframework.stereotype.Service;
@Service
public class LightService {
//省略其他非关键代码
public void shutdown(){
System.out.println("shutting down all lights");
}
//省略其他非关键代码
}
在之前的案例中,如果我们的宿舍管理系统在重启时,灯是不会被关闭的。但是随着业务的需求变化,我们可能会去掉 @Service 注解,而是使用另外一种产生 Bean 的方式:创建一个配置类 BeanConfiguration(标记 @Configuration)来创建一堆 Bean,其中就包含了创建 LightService 类型的 Bean,并将其注册到 Spring 容器:
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class BeanConfiguration {
@Bean
public LightService getTransmission(){
return new LightService();
}
}
复用案例 1 的启动程序,稍作修改,让 Spring 启动完成后立马关闭当前 Spring 上下文。这样等同于模拟宿舍管理系统的启停:
@SpringBootApplication
public class Application {
public static void main(String[] args) {
ConfigurableApplicationContext context = SpringApplication.run(Application.class, args);
context.close();
}
}
以上代码没有其他任何方法的调用,仅仅是将所有符合约定的类初始化并加载到 Spring 容器,完成后再关闭当前的 Spring 容器。按照预期,这段代码运行后不会有任何的 log 输出,毕竟我们只是改变了 Bean 的产生方式。
但实际运行这段代码后,我们可以看到控制台上打印了 shutting down all lights。显然 shutdown 方法未按照预期被执行了,这导致一个很有意思的 bug:在使用新的 Bean 生成方式之前,每一次宿舍管理服务被重启时,宿舍里所有的灯都不会被关闭。但是修改后,只有服务重启,灯都被意外关闭了。如何理解这个 bug?
案例解析
通过调试,我们发现只有通过使用 Bean 注解注册到 Spring 容器的对象,才会在 Spring 容器被关闭的时候自动调用 shutdown 方法,而使用 @Component(Service 也是一种 Component)将当前类自动注入到 Spring 容器时,shutdown 方法则不会被自动执行。
我们可以尝试到 Bean 注解类的代码中去寻找一些线索,可以看到属性 destroyMethod 有非常大段的注释,基本上解答了我们对于这个问题的大部分疑惑。
使用 Bean 注解的方法所注册的 Bean 对象,如果用户不设置 destroyMethod 属性,则其属性值为 AbstractBeanDefinition.INFER_METHOD。此时 Spring 会检查当前 Bean 对象的原始类中是否有名为 shutdown 或者 close 的方法,如果有,此方法会被 Spring 记录下来,并在容器被销毁时自动执行;当然如若没有,那么自然什么都不会发生。
下面我们继续查看 Spring 的源代码来进一步分析此问题。
首先我们可以查找 INFER_METHOD 枚举值的引用,很容易就找到了使用该枚举值的方法 DisposableBeanAdapter#inferDestroyMethodIfNecessary:
private String inferDestroyMethodIfNecessary(Object bean, RootBeanDefinition beanDefinition) {
String destroyMethodName = beanDefinition.getDestroyMethodName();
if (AbstractBeanDefinition.INFER_METHOD.equals(destroyMethodName) ||(destroyMethodName == null && bean instanceof AutoCloseable)) {
if (!(bean instanceof DisposableBean)) {
try {
//尝试查找 close 方法
return bean.getClass().getMethod(CLOSE_METHOD_NAME).getName();
}
catch (NoSuchMethodException ex) {
try {
//尝试查找 shutdown 方法
return bean.getClass().getMethod(SHUTDOWN_METHOD_NAME).getName();
}
catch (NoSuchMethodException ex2) {
// no candidate destroy method found
}
}
}
return null;
}
return (StringUtils.hasLength(destroyMethodName) ? destroyMethodName : null);
}
我们可以看到,代码逻辑和 Bean 注解类中对于 destroyMethod 属性的注释完全一致 destroyMethodName 如果等于 INFER_METHOD,且当前类没有实现 DisposableBean 接口,那么首先查找类的 close 方法,如果找不到,就在抛出异常后继续查找 shutdown 方法;如果找到了,则返回其方法名(close 或者 shutdown)。
接着,继续逐级查找引用,最终得到的调用链从上到下为 doCreateBean->registerDisposableBeanIfNecessary->registerDisposableBean(new DisposableBeanAdapter)->inferDestroyMethodIfNecessary。
然后,我们追溯到了顶层的 doCreateBean 方法,代码如下:
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final @Nullable Object[] args)
throws BeanCreationException {
//省略非关键代码
if (instanceWrapper == null) {
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
//省略非关键代码
// Initialize the bean instance.
Object exposedObject = bean;
try {
populateBean(beanName, mbd, instanceWrapper);
exposedObject = initializeBean(beanName, exposedObject, mbd);
}
//省略非关键代码
// Register bean as disposable.
try {
registerDisposableBeanIfNecessary(beanName, bean, mbd);
}
catch (BeanDefinitionValidationException ex) {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Invalid destruction signature", ex);
}
return exposedObject;
}
到这,我们就可以对 doCreateBean 方法做一个小小的总结了。可以说 doCreateBean 管理了 Bean 的整个生命周期中几乎所有的关键节点,直接负责了 Bean 对象的生老病死,其主要功能包括:
- Bean 实例的创建;
- Bean 对象依赖的注入;
- 定制类初始化方法的回调;
- Disposable 方法的注册。
接着,继续查看 registerDisposableBean 方法:
public void registerDisposableBean(String beanName, DisposableBean bean) {
//省略其他非关键代码
synchronized (this.disposableBeans) {
this.disposableBeans.put(beanName, bean);
}
//省略其他非关键代码
}
在 registerDisposableBean 方法内,DisposableBeanAdapter 类(其属性 destroyMethodName 记录了使用哪种 destory 方法)被实例化并添加到 DefaultSingletonBeanRegistry#disposableBeans 属性内,disposableBeans 将暂存这些 DisposableBeanAdapter 实例,直到 AnnotationConfigApplicationContext 的 close 方法被调用。
而当 AnnotationConfigApplicationContext 的 close 方法被调用时,即当 Spring 容器被销毁时,最终会调用到 DefaultSingletonBeanRegistry#destroySingleton。此方法将遍历 disposableBeans 属性逐一获取 DisposableBean,依次调用其中的 close 或者 shutdown 方法:
public void destroySingleton(String beanName) {
// Remove a registered singleton of the given name, if any.
removeSingleton(beanName);
// Destroy the corresponding DisposableBean instance.
DisposableBean disposableBean;
synchronized (this.disposableBeans) {
disposableBean = (DisposableBean) this.disposableBeans.remove(beanName);
}
destroyBean(beanName, disposableBean);
}
很明显,最终我们的案例调用了 LightService#shutdown 方法,将所有的灯关闭了。
问题修正
现在,我们已经知道了问题的根源,解决起来就非常简单了。
我们可以通过避免在 Java 类中定义一些带有特殊意义动词的方法来解决,当然如果一定要定义名为 close 或者 shutdown 方法,也可以通过将 Bean 注解内 destroyMethod 属性设置为空的方式来解决这个问题。
第一种修改方式比较简单,所以这里只展示第二种修改方式,代码如下:
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class BeanConfiguration {
@Bean(destroyMethod="")
public LightService getTransmission(){
return new LightService();
}
}
另外,针对这个问题我想再多提示一点。如果我们能养成良好的编码习惯,在使用某个不熟悉的注解之前,认真研读一下该注解的注释,也可以大概率规避这个问题。
不过说到这里,你也可能还是会疑惑,为什么 @Service 注入的 LightService,其 shutdown 方法不能被执行?这里我想补充说明下。
想要执行,则必须要添加 DisposableBeanAdapter,而它的添加是有条件的:
protected void registerDisposableBeanIfNecessary(String beanName, Object bean, RootBeanDefinition mbd) {
AccessControlContext acc = (System.getSecurityManager() != null ? getAccessControlContext() : null);
if (!mbd.isPrototype() && requiresDestruction(bean, mbd)) {
if (mbd.isSingleton()) {
// Register a DisposableBean implementation that performs all destruction
// work for the given bean: DestructionAwareBeanPostProcessors,
// DisposableBean interface, custom destroy method.
registerDisposableBean(beanName,
new DisposableBeanAdapter(bean, beanName, mbd, getBeanPostProcessors(), acc));
}
else {
//省略非关键代码
}
}
}
参考上述代码,关键的语句在于:
!mbd.isPrototype() && requiresDestruction(bean, mbd)
很明显,在案例代码修改前后,我们都是单例,所以区别仅在于是否满足 requiresDestruction 条件。翻阅它的代码,最终的关键调用参考 DisposableBeanAdapter#hasDestroyMethod:
public static boolean hasDestroyMethod(Object bean, RootBeanDefinition beanDefinition) {
if (bean instanceof DisposableBean || bean instanceof AutoCloseable) {
return true;
}
String destroyMethodName = beanDefinition.getDestroyMethodName();
if (AbstractBeanDefinition.INFER_METHOD.equals(destroyMethodName)) {
return (ClassUtils.hasMethod(bean.getClass(), CLOSE_METHOD_NAME) ||
ClassUtils.hasMethod(bean.getClass(), SHUTDOWN_METHOD_NAME));
}
return StringUtils.hasLength(destroyMethodName);
}
如果我们是使用 @Service 来产生 Bean 的,那么在上述代码中我们获取的 destroyMethodName 其实是 null;而使用 @Bean 的方式,默认值为 AbstractBeanDefinition.INFER_METHOD,参考 Bean 的定义:
public @interface Bean {
//省略其他非关键代码
String destroyMethod() default AbstractBeanDefinition.INFER_METHOD;
}
继续对照代码,你就会发现 @Service 标记的 LightService 也没有实现 AutoCloseable、DisposableBean,最终没有添加一个 DisposableBeanAdapter。所以最终我们定义的 shutdown 方法没有被调用。
05/06|Spring AOP 常见错误 #
Spring AOP 是 Spring 中除了依赖注入外(DI)最为核心的功能,顾名思义,AOP 即 Aspect Oriented Programming,翻译为面向切面编程。
而 Spring AOP 则利用 CGlib 和 JDK 动态代理等方式来实现运行期动态方法增强,其目的是将与业务无关的代码单独抽离出来,使其逻辑不再与业务代码耦合,从而降低系统的耦合性,提高程序的可重用性和开发效率。因而 AOP 便成为了日志记录、监控管理、性能统计、异常处理、权限管理、统一认证等各个方面被广泛使用的技术。
追根溯源,我们之所以能无感知地在容器对象方法前后任意添加代码片段,那是由于 Spring 在运行期帮我们把切面中的代码逻辑动态“织入”到了容器对象方法内,所以说 AOP 本质上就是一个代理模式。然而在使用这种代理模式时,我们常常会用不好,那么这节课我们就来解析下有哪些常见的问题,以及背后的原理是什么。
案例 1:this 调用的当前类方法无法被拦截
假设我们正在开发一个宿舍管理系统,这个模块包含一个负责电费充值的类 ElectricService,它含有一个充电方法 charge():
@Service
public class ElectricService {
public void charge() throws Exception {
System.out.println("Electric charging ...");
this.pay();
}
public void pay() throws Exception {
System.out.println("Pay with alipay ...");
Thread.sleep(1000);
}
}
在这个电费充值方法 charge() 中,我们会使用支付宝进行充值。因此在这个方法中,我加入了 pay() 方法。为了模拟 pay() 方法调用耗时,代码执行了休眠 1 秒,并在 charge() 方法里使用 this.pay() 的方式调用这种支付方法。
但是因为支付宝支付是第三方接口,我们需要记录下接口调用时间。这时候我们就引入了一个 @Around 的增强 ,分别记录在 pay() 方法执行前后的时间,并计算出执行 pay() 方法的耗时。
@Aspect
@Service
@Slf4j
public class AopConfig {
@Around("execution(* com.spring.puzzle.class5.example1.ElectricService.pay()) ")
public void recordPayPerformance(ProceedingJoinPoint joinPoint) throws Throwable {
long start = System.currentTimeMillis();
joinPoint.proceed();
long end = System.currentTimeMillis();
System.out.println("Pay method time cost(ms): " + (end - start));
}
}
最后我们再通过定义一个 Controller 来提供电费充值接口,定义如下:
@RestController
public class HelloWorldController {
@Autowired
ElectricService electricService;
@RequestMapping(path = "charge", method = RequestMethod.GET)
public void charge() throws Exception{
electricService.charge();
};
}
完成代码后,我们访问上述接口,会发现这段计算时间的切面并没有执行到,输出日志如下:
Electric charging ...
Pay with alipay ...
回溯之前的代码可知,在 @Around 的切面类中,我们很清晰地定义了切面对应的方法,但是却没有被执行到。这说明了在类的内部,通过 this 方式调用的方法,是没有被 Spring AOP 增强的。这是为什么呢?我们来分析一下。
案例解析
我们可以从源码中找到真相。首先来设置个断点,调试看看 this 对应的对象是什么样的:
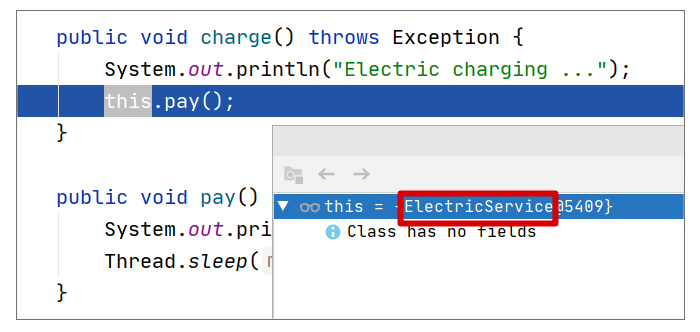
可以看到,this 对应的就是一个普通的 ElectricService 对象,并没有什么特别的地方。再看看在 Controller 层中自动装配的 ElectricService 对象是什么样:
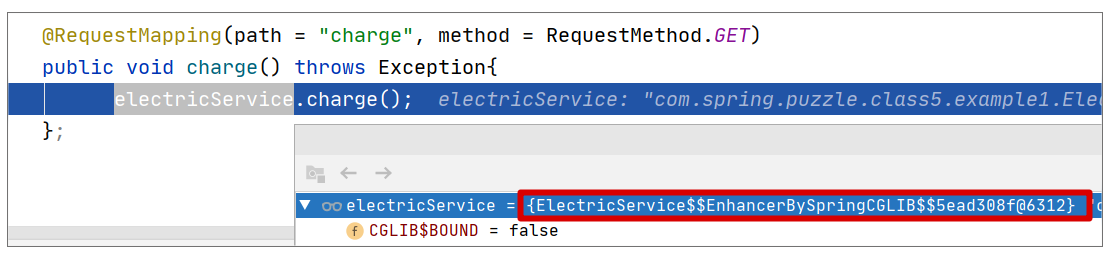
可以看到,这是一个被 Spring 增强过的 Bean,所以执行 charge() 方法时,会执行记录接口调用时间的增强操作。而 this 对应的对象只是一个普通的对象,并没有做任何额外的增强。
为什么 this 引用的对象只是一个普通对象呢?这还要从 Spring AOP 增强对象的过程来看。但在此之前,有些基础我需要在这里强调下。
- Spring AOP 的实现
Spring AOP 的底层是动态代理。而创建代理的方式有两种,JDK 的方式和 CGLIB 的方式。JDK 动态代理只能对实现了接口的类生成代理,而不能针对普通类。而 CGLIB 是可以针对类实现代理,主要是对指定的类生成一个子类,覆盖其中的方法,来实现代理对象。具体区别可参考下图:
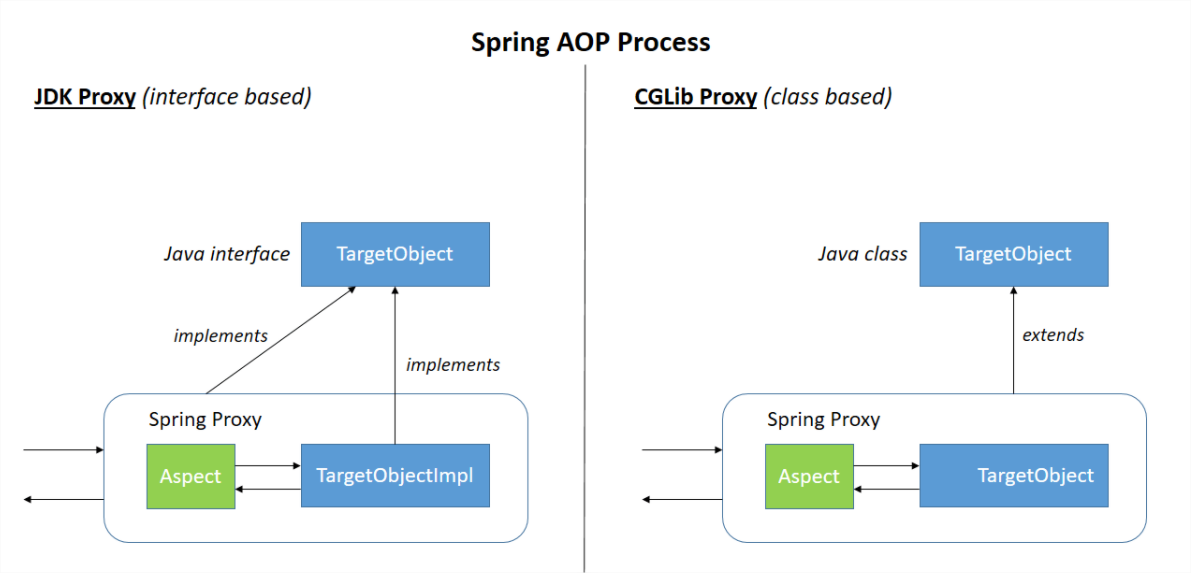
- 如何使用 Spring AOP
在 Spring Boot 中,我们一般只要添加以下依赖就可以直接使用 AOP 功能:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
而对于非 Spring Boot 程序,除了添加相关 AOP 依赖项外,我们还常常会使用 @EnableAspectJAutoProxy 来开启 AOP 功能。这个注解类引入(Import)AspectJAutoProxyRegistrar,它通过实现 ImportBeanDefinitionRegistrar 的接口方法来完成 AOP 相关 Bean 的准备工作。
补充完最基本的 Spring 底层知识和使用知识后,我们具体看下创建代理对象的过程。先来看下调用栈:

创建代理对象的时机就是创建一个 Bean 的时候,而创建的的关键工作其实是由 AnnotationAwareAspectJAutoProxyCreator 完成的。它本质上是一种 BeanPostProcessor。所以它的执行是在完成原始 Bean 构建后的初始化 Bean(initializeBean)过程中。而它到底完成了什么工作呢?我们可以看下它的 postProcessAfterInitialization 方法:
public Object postProcessAfterInitialization(@Nullable Object bean, String beanName) {
if (bean != null) {
Object cacheKey = getCacheKey(bean.getClass(), beanName);
if (this.earlyProxyReferences.remove(cacheKey) != bean) {
return wrapIfNecessary(bean, beanName, cacheKey);
}
}
return bean;
}
上述代码中的关键方法是 wrapIfNecessary,顾名思义,在需要使用 AOP 时,它会把创建的原始的 Bean 对象 wrap 成代理对象作为 Bean 返回。具体到这个 wrap 过程,可参考下面的关键代码行:
protected Object wrapIfNecessary(Object bean, String beanName, Object cacheKey) {
// 省略非关键代码
Object[] specificInterceptors = getAdvicesAndAdvisorsForBean(bean.getClass(), beanName, null);
if (specificInterceptors != DO_NOT_PROXY) {
this.advisedBeans.put(cacheKey, Boolean.TRUE);
Object proxy = createProxy(
bean.getClass(), beanName, specificInterceptors, new SingletonTargetSource(bean));
this.proxyTypes.put(cacheKey, proxy.getClass());
return proxy;
}
// 省略非关键代码
}
上述代码中,第 6 行的 createProxy 调用是创建代理对象的关键。具体到执行过程,它首先会创建一个代理工厂,然后将通知器(advisors)、被代理对象等信息加入到代理工厂,最后通过这个代理工厂来获取代理对象。一些关键过程参考下面的方法:
protected Object createProxy(Class<?> beanClass, @Nullable String beanName,
@Nullable Object[] specificInterceptors, TargetSource targetSource) {
// 省略非关键代码
ProxyFactory proxyFactory = new ProxyFactory();
if (!proxyFactory.isProxyTargetClass()) {
if (shouldProxyTargetClass(beanClass, beanName)) {
proxyFactory.setProxyTargetClass(true);
}
else {
evaluateProxyInterfaces(beanClass, proxyFactory);
}
}
Advisor[] advisors = buildAdvisors(beanName, specificInterceptors);
proxyFactory.addAdvisors(advisors);
proxyFactory.setTargetSource(targetSource);
customizeProxyFactory(proxyFactory);
// 省略非关键代码
return proxyFactory.getProxy(getProxyClassLoader());
}
经过这样一个过程,一个代理对象就被创建出来了。我们从 Spring 中获取到的对象都是这个代理对象,所以具有 AOP 功能。而之前直接使用 this 引用到的只是一个普通对象,自然也就没办法实现 AOP 的功能了。
问题修正
从上述案例解析中,我们知道,只有引用的是被动态代理创建出来的对象,才会被 Spring 增强,具备 AOP 该有的功能。那什么样的对象具备这样的条件呢?
有两种。一种是被 @Autowired 注解的,于是我们的代码可以改成这样,即通过 @Autowired 的方式,在类的内部,自己引用自己:
@Service
public class ElectricService {
@Autowired
ElectricService electricService;
public void charge() throws Exception {
System.out.println("Electric charging ...");
//this.pay();
electricService.pay();
}
public void pay() throws Exception {
System.out.println("Pay with alipay ...");
Thread.sleep(1000);
}
}
另一种方法就是直接从 AopContext 获取当前的 Proxy。那你可能会问了,AopContext 是什么?简单说,它的核心就是通过一个 ThreadLocal 来将 Proxy 和线程绑定起来,这样就可以随时拿出当前线程绑定的 Proxy。
不过使用这种方法有个小前提,就是需要在 @EnableAspectJAutoProxy 里加一个配置项 exposeProxy = true,表示将代理对象放入到 ThreadLocal,这样才可以直接通过 AopContext.currentProxy() 的方式获取到,否则会报错如下:
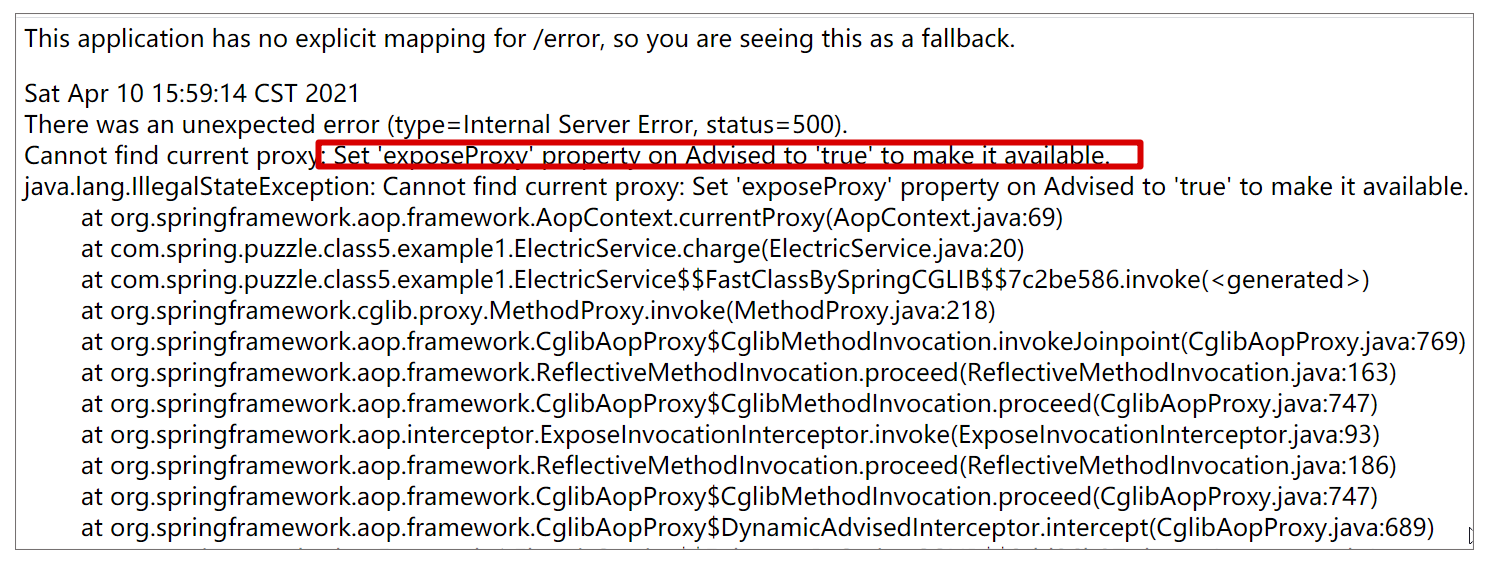
按这个思路,我们修改下相关代码:
import org.springframework.aop.framework.AopContext;
import org.springframework.stereotype.Service;
@Service
public class ElectricService {
public void charge() throws Exception {
System.out.println("Electric charging ...");
ElectricService electric = ((ElectricService) AopContext.currentProxy());
electric.pay();
}
public void pay() throws Exception {
System.out.println("Pay with alipay ...");
Thread.sleep(1000);
}
}
同时,不要忘记修改 EnableAspectJAutoProxy 注解的 exposeProxy 属性,示例如下:
@SpringBootApplication
@EnableAspectJAutoProxy(exposeProxy = true)
public class Application {
// 省略非关键代码
}
这两种方法的效果其实是一样的,最终我们打印出了期待的日志,到这,问题顺利解决了。
Electric charging ...
Pay with alipay ...
Pay method time cost(ms): 1005
案例 2:直接访问被拦截类的属性抛空指针异常
接上一个案例,在宿舍管理系统中,我们使用了 charge() 方法进行支付。在统一结算的时候我们会用到一个管理员用户付款编号,这时候就用到了几个新的类。
User 类,包含用户的付款编号信息:
public class User {
private String payNum;
public User(String payNum) {
this.payNum = payNum;
}
public String getPayNum() {
return payNum;
}
public void setPayNum(String payNum) {
this.payNum = payNum;
}
}
AdminUserService 类,包含一个管理员用户(User),其付款编号为 202101166;另外,这个服务类有一个 login() 方法,用来登录系统。
@Service
public class AdminUserService {
public final User adminUser = new User("202101166");
public void login() {
System.out.println("admin user login...");
}
}
我们需要修改 ElectricService 类实现这个需求:在电费充值时,需要管理员登录并使用其编号进行结算。完整代码如下:
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class ElectricService {
@Autowired
private AdminUserService adminUserService;
public void charge() throws Exception {
System.out.println("Electric charging ...");
this.pay();
}
public void pay() throws Exception {
adminUserService.login();
String payNum = adminUserService.adminUser.getPayNum();
System.out.println("User pay num : " + payNum);
System.out.println("Pay with alipay ...");
Thread.sleep(1000);
}
}
代码完成后,执行 charge() 操作,一切正常:
Electric charging ...
admin user login...
User pay num : 202101166
Pay with alipay ...
这时候,由于安全需要,就需要管理员在登录时,记录一行日志以便于以后审计管理员操作。所以我们添加一个 AOP 相关配置类,具体如下:
@Aspect
@Service
@Slf4j
public class AopConfig {
@Before("execution(* com.spring.puzzle.class5.example2.AdminUserService.login(..)) ")
public void logAdminLogin(JoinPoint pjp) throws Throwable {
System.out.println("! admin login ...");
}
}
添加这段代码后,我们执行 charge() 操作,发现不仅没有相关日志,而且在执行下面这一行代码的时候直接抛出了 NullPointerException:
String payNum = dminUserService.user.getPayNum();
本来一切正常的代码,因为引入了一个 AOP 切面,抛出了 NullPointerException。这会是什么原因呢?我们先 debug 一下,来看看加入 AOP 后调用的对象是什么样子。
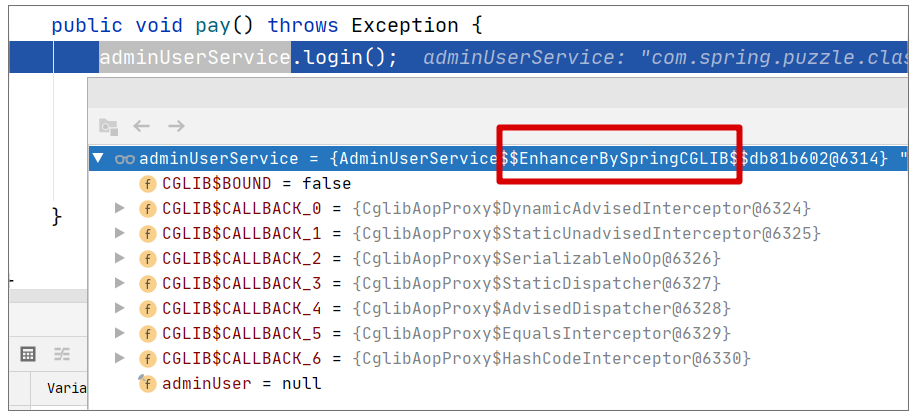
可以看出,加入 AOP 后,我们的对象已经是一个代理对象了,如果你眼尖的话,就会发现在上图中,属性 adminUser 确实为 null。为什么会这样?为了解答这个诡异的问题,我们需要进一步理解 Spring 使用 CGLIB 生成 Proxy 的原理。
案例解析
我们在上一个案例中解析了创建 Spring Proxy 的大体过程,在这里,我们需要进一步研究一下通过 Proxy 创建出来的是一个什么样的对象。正常情况下,AdminUserService 只是一个普通的对象,而 AOP 增强过的则是一个 AdminUserService $$EnhancerBySpringCGLIB$$xxxx。
这个类实际上是 AdminUserService 的一个子类。它会 overwrite 所有 public 和 protected 方法,并在内部将调用委托给原始的 AdminUserService 实例。
从具体实现角度看,CGLIB 中 AOP 的实现是基于 org.springframework.cglib.proxy 包中 Enhancer 和 MethodInterceptor 两个接口来实现的。
整个过程,我们可以概括为三个步骤:
- 定义自定义的 MethodInterceptor 负责委托方法执行;
- 创建 Enhance 并设置 Callback 为上述 MethodInterceptor;
- enhancer.create() 创建代理。
接下来,我们来具体分析一下 Spring 的相关实现源码。
在上个案例分析里,我们简要提及了 Spring 的动态代理对象的初始化机制。在得到 Advisors 之后,会通过 ProxyFactory.getProxy 获取代理对象:
public Object getProxy(ClassLoader classLoader) {
return createAopProxy().getProxy(classLoader);
}
在这里,我们以 CGLIB 的 Proxy 的实现类 CglibAopProxy 为例,来看看具体的流程:
public Object getProxy(@Nullable ClassLoader classLoader) {
// 省略非关键代码
// 创建及配置 Enhancer
Enhancer enhancer = createEnhancer();
// 省略非关键代码
// 获取Callback:包含DynamicAdvisedInterceptor,亦是MethodInterceptor
Callback[] callbacks = getCallbacks(rootClass);
// 省略非关键代码
// 生成代理对象并创建代理(设置 enhancer 的 callback 值)
return createProxyClassAndInstance(enhancer, callbacks);
// 省略非关键代码
}
上述代码中的几个关键步骤大体符合之前提及的三个步骤,其中最后一步一般都会执行到 CglibAopProxy 子类 ObjenesisCglibAopProxy 的 createProxyClassAndInstance() 方法:
protected Object createProxyClassAndInstance(Enhancer enhancer, Callback[] callbacks) {
//创建代理类Class
Class<?> proxyClass = enhancer.createClass();
Object proxyInstance = null;
//spring.objenesis.ignore默认为false
//所以objenesis.isWorthTrying()一般为true
if (objenesis.isWorthTrying()) {
try {
// 创建实例
proxyInstance = objenesis.newInstance(proxyClass, enhancer.getUseCache());
}
catch (Throwable ex) {
// 省略非关键代码
}
}
if (proxyInstance == null) {
// 尝试普通反射方式创建实例
try {
Constructor<?> ctor = (this.constructorArgs != null ?
proxyClass.getDeclaredConstructor(this.constructorArgTypes) :
proxyClass.getDeclaredConstructor());
ReflectionUtils.makeAccessible(ctor);
proxyInstance = (this.constructorArgs != null ?
ctor.newInstance(this.constructorArgs) : ctor.newInstance());
//省略非关键代码
}
}
// 省略非关键代码
((Factory) proxyInstance).setCallbacks(callbacks);
return proxyInstance;
}
这里我们可以了解到,Spring 会默认尝试使用 objenesis 方式实例化对象,如果失败则再次尝试使用常规方式实例化对象。现在,我们可以进一步查看 objenesis 方式实例化对象的流程。
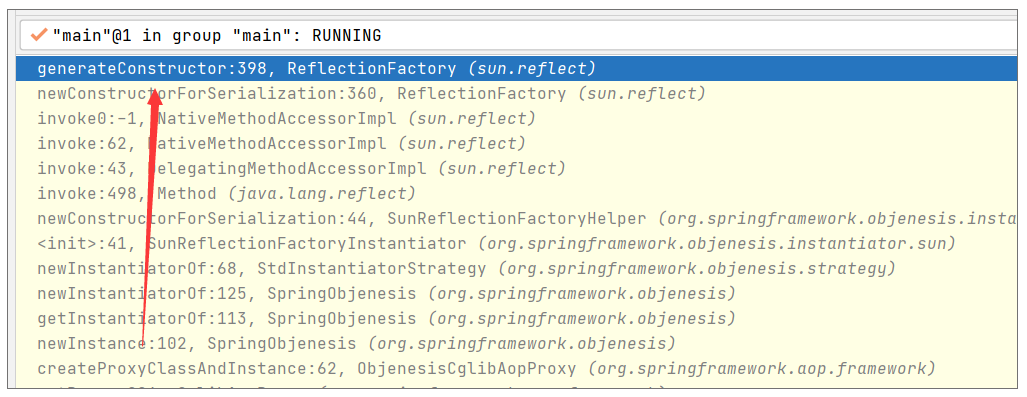
参照上述截图所示调用栈,objenesis 方式最后使用了 JDK 的 ReflectionFactory.newConstructorForSerialization() 完成了代理对象的实例化。而如果你稍微研究下这个方法,你会惊讶地发现,这种方式创建出来的对象是不会初始化类成员变量的。
所以说到这里,聪明的你可能已经觉察到真相已经暴露了,我们这个案例的核心是代理类实例的默认构建方式很特别。在这里,我们可以总结和对比下通过反射来实例化对象的方式,包括:
- java.lang.Class.newInsance()
- java.lang.reflect.Constructor.newInstance()
- sun.reflect.ReflectionFactory.newConstructorForSerialization().newInstance()
前两种初始化方式都会同时初始化类成员变量,但是最后一种通过 ReflectionFactory.newConstructorForSerialization().newInstance() 实例化类则不会初始化类成员变量,这就是当前问题的最终答案了。
问题修正
了解了问题的根本原因后,修正起来也就不困难了。既然是无法直接访问被拦截类的成员变量,那我们就换个方式,在 UserService 里写个 getUser() 方法,从内部访问获取变量。
我们在 AdminUserService 里加了个 getUser() 方法:
public User getUser() {
return user;
}
在 ElectricService 里通过 getUser() 获取 User 对象:
// 原来出错的方式:
//String payNum = = adminUserService.adminUser.getPayNum();
// 修改后的方式:
String payNum = adminUserService.getAdminUser().getPayNum();
运行下来,一切正常,可以看到管理员登录日志了:
Electric charging ...
! admin login ...
admin user login...
User pay num : 202101166
Pay with alipay ...
但你有没有产生另一个困惑呢?既然代理类的类属性不会被初始化,那为什么可以通过在 AdminUserService 里写个 getUser() 方法来获取代理类实例的属性呢?
我们再次回顾 createProxyClassAndInstance 的代码逻辑,创建代理类后,我们会调用 setCallbacks 来设置拦截后需要注入的代码:
protected Object createProxyClassAndInstance(Enhancer enhancer, Callback[] callbacks) {
Class<?> proxyClass = enhancer.createClass();
Object proxyInstance = null;
if (objenesis.isWorthTrying()) {
try {
proxyInstance = objenesis.newInstance(proxyClass, enhancer.getUseCache());
}
// 省略非关键代码
((Factory) proxyInstance).setCallbacks(callbacks);
return proxyInstance;
}
通过代码调试和分析,我们可以得知上述的 callbacks 中会存在一种服务于 AOP 的 DynamicAdvisedInterceptor,它的接口是 MethodInterceptor(callback 的子接口),实现了拦截方法 intercept()。我们可以看下它是如何实现这个方法的:
public Object intercept(Object proxy, Method method, Object[] args, MethodProxy methodProxy) throws Throwable {
// 省略非关键代码
TargetSource targetSource = this.advised.getTargetSource();
// 省略非关键代码
if (chain.isEmpty() && Modifier.isPublic(method.getModifiers())) {
Object[] argsToUse = AopProxyUtils.adaptArgumentsIfNecessary(method, args);
retVal = methodProxy.invoke(target, argsToUse);
}
else {
// We need to create a method invocation...
retVal = new CglibMethodInvocation(proxy, target, method, args, targetClass, chain, methodProxy).proceed();
}
retVal = processReturnType(proxy, target, method, retVal);
return retVal;
}
//省略非关键代码
}
当代理类方法被调用,会被 Spring 拦截,从而进入此 intercept(),并在此方法中获取被代理的原始对象。而在原始对象中,类属性是被实例化过且存在的。因此代理类是可以通过方法拦截获取被代理对象实例的属性。
说到这里,我们已经解决了问题。但如果你看得仔细,就会发现,其实你改变一个属性,也可以让产生的代理对象的属性值不为 null。例如修改启动参数 spring.objenesis.ignore 如下:

此时再调试程序,你会发现 adminUser 已经不为 null 了:
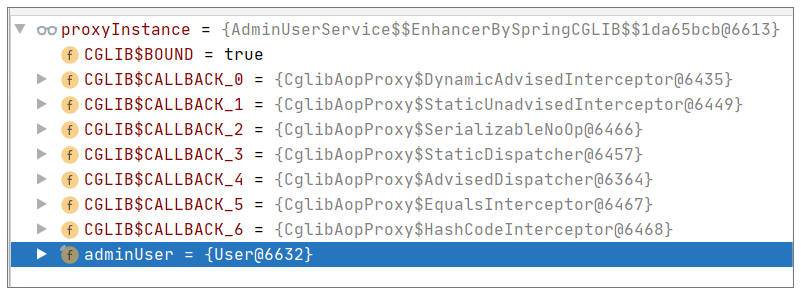
所以这也是解决这个问题的一种方法。
当一个系统采用的切面越来越多时,因为执行顺序而导致的问题便会逐步暴露出来,下面我们就重点看一下。
案例 1:错乱混合不同类型的增强
还是沿用上节课的宿舍管理系统开发场景。
这里我们先回顾下,你就不用去翻代码了。这个宿舍管理系统保护了一个电费充值模块,它包含了一个负责电费充值的类 ElectricService,还有一个充电方法 charge():
@Service
public class ElectricService {
public void charge() throws Exception {
System.out.println("Electric charging ...");
}
}
为了在执行 charge() 之前,鉴定下调用者的权限,我们增加了针对于 Electric 的切面类 AopConfig,其中包含一个 @Before 增强。这里的增强没有做任何事情,仅仅是打印了一行日志,然后模拟执行权限校验功能(占用 1 秒钟)。
//省略 imports
@Aspect
@Service
@Slf4j
public class AspectService {
@Before("execution(* com.spring.puzzle.class6.example1.ElectricService.charge()) ")
public void checkAuthority(JoinPoint pjp) throws Throwable {
System.out.println("validating user authority");
Thread.sleep(1000);
}
}
执行后,我们得到以下 log,接着一切按照预期继续执行:
validating user authority
Electric charging ...
一段时间后,由于业务发展,ElectricService 中的 charge() 逻辑变得更加复杂了,我们需要仅仅针对 ElectricService 的 charge() 做性能统计。为了不影响原有的业务逻辑,我们在 AopConfig 中添加了另一个增强,代码更改后如下:
//省略 imports
@Aspect
@Service
public class AopConfig {
@Before("execution(* com.spring.puzzle.class6.example1.ElectricService.charge()) ")
public void checkAuthority(JoinPoint pjp) throws Throwable {
System.out.println("validating user authority");
Thread.sleep(1000);
}
@Around("execution(* com.spring.puzzle.class6.example1.ElectricService.charge()) ")
public void recordPerformance(ProceedingJoinPoint pjp) throws Throwable {
long start = System.currentTimeMillis();
pjp.proceed();
long end = System.currentTimeMillis();
System.out.println("charge method time cost: " + (end - start));
}
}
执行后得到日志如下:
validating user authority
Electric charging …
charge method time cost 1022 (ms)
通过性能统计打印出的日志,我们可以得知 charge() 执行时间超过了 1 秒钟。然而,该方法仅打印了一行日志,它的执行不可能需要这么长时间。
因此我们很容易看出问题所在:当前 ElectricService 中 charge() 的执行时间,包含了权限验证的时间,即包含了通过 @Around 增强的 checkAuthority() 执行的所有时间。这并不符合我们的初衷,我们需要统计的仅仅是 ElectricService.charge() 的性能统计,它并不包含鉴权过程。
当然,这些都是从日志直接观察出的现象。实际上,这个问题出现的根本原因和 AOP 的执行顺序有关。针对这个案例而言,当同一个切面(Aspect)中同时包含多个不同类型的增强时(Around、Before、After、AfterReturning、AfterThrowing 等),它们的执行是有顺序的。那么顺序如何?我们不妨来解析下。
案例解析
其实一切都可以从源码中得到真相!Spring 初始化单例类的一般过程,基本都是 getBean()->doGetBean()->getSingleton(),如果发现 Bean 不存在,则调用 createBean()->doCreateBean() 进行实例化。
而如果我们的代码里使用了 Spring AOP,doCreateBean() 最终会返回一个代理对象。至于代理对象如何创建,大体流程我们在上一讲已经概述过了。如果你记忆力比较好的话,应该记得在代理对象的创建过程中,我们贴出过这样一段代码(参考 AbstractAutoProxyCreator#createProxy):
protected Object createProxy(Class<?> beanClass, @Nullable String beanName,
@Nullable Object[] specificInterceptors, TargetSource targetSource) {
//省略非关键代码
Advisor[] advisors = buildAdvisors(beanName, specificInterceptors);
proxyFactory.addAdvisors(advisors);
proxyFactory.setTargetSource(targetSource);
//省略非关键代码
return proxyFactory.getProxy(getProxyClassLoader());
}
其中 advisors 就是增强方法对象,它的顺序决定了面临多个增强时,到底先执行谁。而这个集合对象本身是由 specificInterceptors 构建出来的,而 specificInterceptors 又是由 AbstractAdvisorAutoProxyCreator#getAdvicesAndAdvisorsForBean 方法构建:
@Override
@Nullable
protected Object[] getAdvicesAndAdvisorsForBean(
Class<?> beanClass, String beanName, @Nullable TargetSource targetSource) {
List<Advisor> advisors = findEligibleAdvisors(beanClass, beanName);
if (advisors.isEmpty()) {
return DO_NOT_PROXY;
}
return advisors.toArray();
}
简单说,其实就是根据当前的 beanClass、beanName 等信息,结合所有候选的 advisors,最终找出匹配(Eligible)的 Advisor,为什么如此?毕竟 AOP 拦截点可能会配置多个,而我们执行的方法不见得会被所有的拦截配置拦截。寻找匹配 Advisor 的逻辑参考 AbstractAdvisorAutoProxyCreator#findEligibleAdvisors:
protected List<Advisor> findEligibleAdvisors(Class<?> beanClass, String beanName) {
//寻找候选的 Advisor
List<Advisor> candidateAdvisors = findCandidateAdvisors();
//根据候选的 Advisor 和当前 bean 算出匹配的 Advisor
List<Advisor> eligibleAdvisors = findAdvisorsThatCanApply(candidateAdvisors, beanClass, beanName);
extendAdvisors(eligibleAdvisors);
if (!eligibleAdvisors.isEmpty()) {
//排序
eligibleAdvisors = sortAdvisors(eligibleAdvisors);
}
return eligibleAdvisors;
}
通过研读代码,最终 Advisors 的顺序是由两点决定:
- candidateAdvisors 的顺序;
- sortAdvisors 进行的排序。
这里我们可以重点看下对本案例起关键作用的 candidateAdvisors 排序。实际上,它的顺序是在 @Aspect 标记的 AopConfig Bean 构建时就决定了。具体而言,就是在初始化过程中会排序自己配置的 Advisors,并把排序结果存入了缓存(BeanFactoryAspectJAdvisorsBuilder#advisorsCache)。
后续 Bean 创建代理时,直接拿出这个排序好的候选 Advisors。候选 Advisors 排序发生在 Bean 构建这个结论时,我们也可以通过 AopConfig Bean 构建中的堆栈信息验证:

可以看到,排序是在 Bean 的构建中进行的,而最后排序执行的关键代码位于下面的方法中(参考 ReflectiveAspectJAdvisorFactory#getAdvisorMethods):
private List<Method> getAdvisorMethods(Class<?> aspectClass) {
final List<Method> methods = new ArrayList<>();
ReflectionUtils.doWithMethods(aspectClass, method -> {
// Exclude pointcuts
if (AnnotationUtils.getAnnotation(method, Pointcut.class) == null) {
methods.add(method);
}
}, ReflectionUtils.USER_DECLARED_METHODS);
// 排序
methods.sort(METHOD_COMPARATOR);
return methods;
}
上述代码的重点是第九行 methods.sort(METHOD_COMPARATOR) 方法。
我们来查看 METHOD_COMPARATOR 的代码,会发现它是定义在 ReflectiveAspectJAdvisorFactory 类中的静态方法块,代码如下:
static {
Comparator<Method> adviceKindComparator = new ConvertingComparator<>(
new InstanceComparator<>(
Around.class, Before.class, After.class, AfterReturning.class, AfterThrowing.class),
(Converter<Method, Annotation>) method -> {
AspectJAnnotation<?> annotation =
AbstractAspectJAdvisorFactory.findAspectJAnnotationOnMethod(method);
return (annotation != null ? annotation.getAnnotation() : null);
});
Comparator<Method> methodNameComparator = new ConvertingComparator<>(Method::getName);
//合并上面两者比较器
METHOD_COMPARATOR = adviceKindComparator.thenComparing(methodNameComparator);
}
METHOD_COMPARATOR 本质上是一个连续比较器,由 adviceKindComparator 和 methodNameComparator 这两个比较器通过 thenComparing() 连接而成。
通过这个案例,我们重点了解 adviceKindComparator 这个比较器,此对象通过实例化 ConvertingComparator 类而来,而 ConvertingComparator 类是 Spring 中较为经典的一个实现。顾名思义,先转化再比较,它构造参数接受以下这两个参数:
- 第一个参数是基准比较器,即在 adviceKindComparator 中最终要调用的比较器,在构造函数中赋值于 this.comparator;
- 第二个参数是一个 lambda 回调函数,用来将传递的参数转化为基准比较器需要的参数类型,在构造函数中赋值于 this.converter。
查看 ConvertingComparator 比较器核心方法 compare 如下:
public int compare(S o1, S o2) {
T c1 = this.converter.convert(o1);
T c2 = this.converter.convert(o2);
return this.comparator.compare(c1, c2);
}
可知,这里是先调用从构造函数中获取到的 lambda 回调函数 this.converter,将需要比较的参数进行转化。我们可以从之前的代码中找出这个转化工作:
(Converter<Method, Annotation>) method -> {
AspectJAnnotation<?> annotation =
AbstractAspectJAdvisorFactory.findAspectJAnnotationOnMethod(method);
return (annotation != null ? annotation.getAnnotation() : null);
});
转化功能的代码逻辑较为简单,就是返回传入方法(method)上标记的增强注解(Pointcut,Around,Before,After,AfterReturning 以及 AfterThrowing):
private static final Class<?>[] ASPECTJ_ANNOTATION_CLASSES = new Class<?>[] {
Pointcut.class, Around.class, Before.class, After.class, AfterReturning.class, AfterThrowing.class};
protected static AspectJAnnotation<?> findAspectJAnnotationOnMethod(Method method) {
for (Class<?> clazz : ASPECTJ_ANNOTATION_CLASSES) {
AspectJAnnotation<?> foundAnnotation = findAnnotation(method, (Class<Annotation>) clazz);
if (foundAnnotation != null) {
return foundAnnotation;
}
}
return null;
}
经过转化后,我们获取到的待比较的数据其实就是注解了。而它们的排序依赖于 ConvertingComparator 的第一个参数,即最终会调用的基准比较器,以下是它的关键实现代码:
new InstanceComparator<>(
Around.class, Before.class, After.class, AfterReturning.class, AfterThrowing.class)
构造方法也是较为简单的,只是将传递进来的 instanceOrder 赋予了类成员变量,继续查看 InstanceComparator 比较器核心方法 compare 如下,也就是最终要调用的比较方法:
public int compare(T o1, T o2) {
int i1 = getOrder(o1);
int i2 = getOrder(o2);
return (i1 < i2 ? -1 : (i1 == i2 ? 0 : 1));
}
一个典型的 Comparator,代码逻辑按照 i1、i2 的升序排列,即 getOrder() 返回的值越小,排序越靠前。
查看 getOrder() 的逻辑如下:
private int getOrder(@Nullable T object) {
if (object != null) {
for (int i = 0; i < this.instanceOrder.length; i++) {
//instance 在 instanceOrder 中的“排号”
if (this.instanceOrder[i].isInstance(object)) {
return i;
}
}
}
return this.instanceOrder.length;
}
返回当前传递的增强注解在 this.instanceOrder 中的序列值,序列值越小,则越靠前。而结合之前构造参数传递的顺序,我们很快就能判断出:最终的排序结果依次是 Around.class, Before.class, After.class, AfterReturning.class, AfterThrowing.class。
到此为止,答案也呼之欲出:this.instanceOrder 的排序,即为不同类型增强的优先级,排序越靠前,优先级越高。
结合之前的讨论,我们可以得出一个结论:同一个切面中,不同类型的增强方法被调用的顺序依次为 Around.class, Before.class, After.class, AfterReturning.class, AfterThrowing.class。
问题修正
从上述案例解析中,我们知道 Around 类型的增强被调用的优先级高于 Before 类型的增强,所以上述案例中性能统计所花费的时间,包含权限验证的时间,也在情理之中。
知道了原理,修正起来也就简单了。假设不允许我们去拆分类,我们可以按照下面的思路来修改:
- 将 ElectricService.charge() 的业务逻辑全部移动到 doCharge(),在 charge() 中调用 doCharge();
- 性能统计只需要拦截 doCharge();
- 权限统计增强保持不变,依然拦截 charge()。
ElectricService 类代码更改如下:
@Service
public class ElectricService {
@Autowired
ElectricService electricService;
public void charge() {
electricService.doCharge();
}
public void doCharge() {
System.out.println("Electric charging ...");
}
}
切面代码更改如下:
//省略 imports
@Aspect
@Service
public class AopConfig {
@Before("execution(* com.spring.puzzle.class6.example1.ElectricService.charge()) ")
public void checkAuthority(JoinPoint pjp) throws Throwable {
System.out.println("validating user authority");
Thread.sleep(1000);
}
@Around("execution(* com.spring.puzzle.class6.example1.ElectricService.doCharge()) ")
public void recordPerformance(ProceedingJoinPoint pjp) throws Throwable {
long start = System.currentTimeMillis();
pjp.proceed();
long end = System.currentTimeMillis();
System.out.println("charge method time cost: " + (end - start));
}
}
案例 2:错乱混合同类型增强
如果同一个切面里的多个增强方法其增强都一样,那调用顺序又如何呢?我们继续看下一个案例。
这里业务逻辑类 ElectricService 没有任何变化,仅包含一个 charge():
import org.springframework.stereotype.Service;
@Service
public class ElectricService {
public void charge() {
System.out.println("Electric charging ...");
}
}
切面类 AspectService 包含两个方法,都是 Before 类型增强。
第一个方法 logBeforeMethod(),目的是在 run() 执行之前希望能输入日志,表示当前方法被调用一次,方便后期统计。另一个方法 validateAuthority(),目的是做权限验证,其作用是在调用此方法之前做权限验证,如果不符合权限限制要求,则直接抛出异常。这里为了方便演示,此方法将直接抛出异常:
//省略 imports
@Aspect
@Service
public class AopConfig {
@Before("execution(* com.spring.puzzle.class5.example2.ElectricService.charge())")
public void logBeforeMethod(JoinPoint pjp) throws Throwable {
System.out.println("step into ->"+pjp.getSignature());
}
@Before("execution(* com.spring.puzzle.class5.example2.ElectricService.charge()) ")
public void validateAuthority(JoinPoint pjp) throws Throwable {
throw new RuntimeException("authority check failed");
}
}
我们对代码的执行预期为:当鉴权失败时,由于 ElectricService.charge() 没有被调用,那么 run() 的调用日志也不应该被输出,即 logBeforeMethod() 不应该被调用,但事实总是出乎意料,执行结果如下:
step into ->void com.spring.puzzle.class6.example2.Electric.charge()
Exception in thread “main” java.lang.RuntimeException: authority check failed
虽然鉴权失败,抛出了异常且 ElectricService.charge() 没有被调用,但是 logBeforeMethod() 的调用日志却被输出了,这将导致后期针对于 ElectricService.charge() 的调用数据统计严重失真。
这里我们就需要搞清楚一个问题:当同一个切面包含多个同一种类型的多个增强,且修饰的都是同一个方法时,这多个增强的执行顺序是怎样的?
案例解析
你应该还记得上述代码中,定义 METHOD_COMPARATOR 的静态代码块吧。
METHOD_COMPARATOR 本质是一个连续比较器,而上个案例中我们仅仅只看了第一个比较器,细心的你肯定发现了这里还有第二个比较器 methodNameComparator,任意两个比较器都可以通过其内置的 thenComparing() 连接形成一个连续比较器,从而可以让我们按照比较器的连接顺序依次比较:
static {
//第一个比较器,用来按照增强类型排序
Comparator<Method> adviceKindComparator = new ConvertingComparator<>(
new InstanceComparator<>(
Around.class, Before.class, After.class, AfterReturning.class, AfterThrowing.class),
(Converter<Method, Annotation>) method -> {
AspectJAnnotation<?> annotation =
AbstractAspectJAdvisorFactory.findAspectJAnnotationOnMethod(method);
return (annotation != null ? annotation.getAnnotation() : null);
})
//第二个比较器,用来按照方法名排序
Comparator<Method> methodNameComparator = new ConvertingComparator<>(Method::getName);
METHOD_COMPARATOR = adviceKindComparator.thenComparing(methodNameComparator);
}
我们可以看到,在第 12 行代码中,第 2 个比较器 methodNameComparator 依然使用的是 ConvertingComparator,传递了方法名作为参数。我们基本可以猜测出该比较器是按照方法名进行排序的,这里可以进一步查看构造器方法及构造器调用的内部 comparable():
public ConvertingComparator(Converter<S, T> converter) {
this(Comparators.comparable(), converter);
}
// 省略非关键代码
public static <T> Comparator<T> comparable() {
return ComparableComparator.INSTANCE;
}
上述代码中的 ComparableComparator 实例其实极其简单,代码如下:
public class ComparableComparator<T extends Comparable<T>> implements Comparator<T> {
public static final ComparableComparator INSTANCE = new ComparableComparator();
@Override
public int compare(T o1, T o2) {
return o1.compareTo(o2);
}
}
答案和我们的猜测完全一致,methodNameComparator 最终调用了 String 类自身的 compareTo(),代码如下:
public int compareTo(String anotherString) {
int len1 = value.length;
int len2 = anotherString.value.length;
int lim = Math.min(len1, len2);
char v1[] = value;
char v2[] = anotherString.value;
int k = 0;
while (k < lim) {
char c1 = v1[k];
char c2 = v2[k];
if (c1 != c2) {
return c1 - c2;
}
k++;
}
return len1 - len2;
}
到这,答案揭晓:如果两个方法名长度相同,则依次比较每一个字母的 ASCII 码,ASCII 码越小,排序越靠前;若长度不同,且短的方法名字符串是长的子集时,短的排序靠前。
问题修正
从上述分析我们得知,在同一个切面配置类中,针对同一个方法存在多个同类型增强时,其执行顺序仅和当前增强方法的名称有关,而不是由谁代码在先、谁代码在后来决定。了解了这点,我们就可以直接通过调整方法名的方式来修正程序:
//省略 imports
@Aspect
@Service
public class AopConfig {
@Before("execution(* com.spring.puzzle.class6.example2.ElectricService.charge())")
public void logBeforeMethod(JoinPoint pjp) throws Throwable {
System.out.println("step into ->"+pjp.getSignature());
}
@Before("execution(* com.spring.puzzle.class6.example2.ElectricService.charge()) ")
public void checkAuthority(JoinPoint pjp) throws Throwable {
throw new RuntimeException("authority check failed");
}
}
我们可以将原来的 validateAuthority() 改为 checkAuthority(),这种情况下,对增强(Advisor)的排序,其实最后就是在比较字符 l 和 字符 c。显然易见,checkAuthority() 的排序会靠前,从而被优先执行,最终问题得以解决。
07|Spring事件常见错误 #
之前介绍了 Spring 依赖注入、AOP 等核心功能点上的常见错误。而作为 Spring 的关键功能支撑,Spring 事件是一个相对独立的点。或许你从没有在自己的项目中使用过 Spring 事件,但是你一定见过它的相关日志。而且在未来的编程实践中,你会发现,一旦你用上了 Spring 事件,往往完成的都是一些有趣的、强大的功能,例如动态配置。那么接下来我就来讲讲 Spring 事件上都有哪些常见的错误。
案例 1:试图处理并不会抛出的事件
Spring 事件的设计比较简单。说白了,就是监听器设计模式在 Spring 中的一种实现,参考下图:
从图中我们可以看出,Spring 事件包含以下三大组件。
- 事件(Event):用来区分和定义不同的事件,在 Spring 中,常见的如 ApplicationEvent 和 AutoConfigurationImportEvent,它们都继承于 java.util.EventObject。
- 事件广播器(Multicaster):负责发布上述定义的事件。例如,负责发布 ApplicationEvent 的 ApplicationEventMulticaster 就是 Spring 中一种常见的广播器。
- 事件监听器(Listener):负责监听和处理广播器发出的事件,例如 ApplicationListener 就是用来处理 ApplicationEventMulticaster 发布的 ApplicationEvent,它继承于 JDK 的 EventListener,我们可以看下它的定义来验证这个结论:
public interface ApplicationListener extends EventListener {
void onApplicationEvent(E event);
}
当然,虽然在上述组件中,任何一个都是缺一不可的,但是功能模块命名不见得完全贴合上述提及的关键字,例如发布 AutoConfigurationImportEvent 的广播器就不含有 Multicaster 字样。它的发布是由 AutoConfigurationImportSelector 来完成的。
对这些基本概念和实现有了一定的了解后,我们就可以开始解析那些常见的错误。闲话少说,我们先来看下面这段基于 Spring Boot 技术栈的代码:
@Slf4j
@Component
public class MyContextStartedEventListener implements ApplicationListener<ContextStartedEvent> {
public void onApplicationEvent(final ContextStartedEvent event) {
log.info("{} received: {}", this.toString(), event);
}
}
很明显,这段代码定义了一个监听器 MyContextStartedEventListener,试图拦截 ContextStartedEvent。因为在很多 Spring 初级开发者眼中,Spring 运转的核心就是一个 Context 的维护,那么启动 Spring 自然会启动 Context,于是他们是很期待出现类似下面的日志的:
2021-03-07 07:08:21.197 INFO 2624 — [nio-8080-exec-1] c.s.p.l.e.MyContextStartedEventListener : com.spring.puzzle.class7.example1.MyContextStartedEventListener@d33d5a received: org.springframework.context.event.ContextStartedEvent[source=org.springframework.boot.web.servlet.context.AnnotationConfigServletWebServerApplicationContext@19b56c0, started on Sun Mar 07 07:07:57 CST 2021]
但是当我们启动 Spring Boot 后,会发现并不会拦截到这个事件,如何理解这个错误呢?
案例解析
在 Spring 事件运用上,这是一个常见的错误,就是不假思索地认为一个框架只要定义了一个事件,那么一定会抛出来。例如,在本案例中,ContextStartedEvent 就是 Spring 内置定义的事件,而 Spring Boot 本身会创建和运维 Context,表面看起来这个事件的抛出是必然的,但是这个事件一定会在 Spring Boot 启动时抛出来么?
答案明显是否定的,我们首先看下要抛出这个事件需要调用的方法是什么?在 Spring Boot 中,这个事件的抛出只发生在一处,即位于方法 AbstractApplicationContext#start 中。
@Override
public void start() {
getLifecycleProcessor().start();
publishEvent(new ContextStartedEvent(this));
}
也就是说,只有上述方法被调用,才会抛出 ContextStartedEvent,但是这个方法在 Spring Boot 启动时会被调用么?我们可以查看 Spring 启动方法中围绕 Context 的关键方法调用,代码如下:
public ConfigurableApplicationContext run(String... args) {
//省略非关键代码
context = createApplicationContext();
//省略非关键代码
prepareContext(context, environment, listeners, applicationArguments, printedBanner);
refreshContext(context);
//省略非关键代码
return context;
}
我们发现围绕 Context、Spring Boot 的启动只做了两个关键工作:创建 Context 和 Refresh Context。其中 Refresh 的关键代码如下:
protected void refresh(ApplicationContext applicationContext) {
Assert.isInstanceOf(AbstractApplicationContext.class, applicationContext);
((AbstractApplicationContext) applicationContext).refresh();
}
很明显,Spring 启动最终调用的是 AbstractApplicationContext#refresh,并不是 AbstractApplicationContext#start。在这样的残酷现实下,ContextStartedEvent 自然不会被抛出,不抛出,自然也不可能被捕获。所以这样的错误也就自然发生了。
问题修正
针对这个案例,有了源码的剖析,我们可以很快找到问题发生的原因,但是修正这个问题还要去追溯我们到底想要的是什么?我们可以分两种情况来考虑。
- 假设我们是误读了 ContextStartedEvent
针对这种情况,往往是因为我们确实想在 Spring Boot 启动时拦截一个启动事件,但是我们粗略扫视相关事件后,误以为 ContextStartedEvent 就是我们想要的。针对这种情况,我们只需要把监听事件的类型修改成真正发生的事件即可,例如在本案例中,我们可以修正如下:
@Component
public class MyContextRefreshedEventListener implements ApplicationListener<ContextRefreshedEvent> {
public void onApplicationEvent(final ContextRefreshedEvent event) {
log.info("{} received: {}", this.toString(), event);
}
}
我们监听 ContextRefreshedEvent 而非 ContextStartedEvent。ContextRefreshedEvent 的抛出可以参考方法 AbstractApplicationContext#finishRefresh,它本身正好是 Refresh 操作中的一步。
protected void finishRefresh() {
//省略非关键代码
initLifecycleProcessor();
// Propagate refresh to lifecycle processor first.
getLifecycleProcessor().onRefresh();
// Publish the final event.
publishEvent(new ContextRefreshedEvent(this));
//省略非关键代码
}
- 假设我们就是想要处理 ContextStartedEvent。
这种情况下,我们真的需要去调用 AbstractApplicationContext#start 方法。例如,我们可以使用下面的代码来让这个事件抛出:
@RestController
public class HelloWorldController {
@Autowired
private AbstractApplicationContext applicationContext;
@RequestMapping(path = "publishEvent", method = RequestMethod.GET)
public String notifyEvent(){
applicationContext.start();
return "ok";
};
}
我们随便找一处来 Autowired 一个 AbstractApplicationContext,然后直接调用其 start() 就能让事件抛出来。
很明显,这种抛出并不难,但是作为题外话,我们可以思考下为什么要去调用 start() 呢?start() 本身在 Spring Boot 中有何作用?
如果我们去翻阅这个方法,我们会发现 start() 是 org.springframework.context.Lifecycle 定义的方法,而它在 Spring Boot 的默认实现中是去执行所有 Lifecycle Bean 的启动方法,这点可以参考 DefaultLifecycleProcessor#startBeans 方法来验证:
private void startBeans(boolean autoStartupOnly) {
Map<String, Lifecycle> lifecycleBeans = getLifecycleBeans();
Map<Integer, LifecycleGroup> phases = new HashMap<>();
lifecycleBeans.forEach((beanName, bean) -> {
if (!autoStartupOnly || (bean instanceof SmartLifecycle && ((SmartLifecycle) bean).isAutoStartup())) {
int phase = getPhase(bean);
LifecycleGroup group = phases.get(phase);
if (group == null) {
group = new LifecycleGroup(phase, this.timeoutPerShutdownPhase, lifecycleBeans, autoStartupOnly);
phases.put(phase, group);
}
group.add(beanName, bean);
}
});
if (!phases.isEmpty()) {
List<Integer> keys = new ArrayList<>(phases.keySet());
Collections.sort(keys);
for (Integer key : keys) {
phases.get(key).start();
}
}
}
说起来比较抽象,我们可以去写一个 Lifecycle Bean,代码如下:
@Component
@Slf4j
public class MyLifeCycle implements Lifecycle {
private volatile boolean running = false;
@Override
public void start() {
log.info("lifecycle start");
running = true;
}
@Override
public void stop() {
log.info("lifecycle stop");
running = false;
}
@Override
public boolean isRunning() {
return running;
}
}
当我们再次运行 Spring Boot 时,只要执行了 AbstractApplicationContext 的 start(),就会输出上述代码定义的行为:输出 LifeCycle start 日志。
通过这个 Lifecycle Bean 的使用,AbstractApplicationContext 的 start 要做的事,我们就清楚多了。它和 Refresh() 不同,Refresh() 是初始化和加载所有需要管理的 Bean,而 start 只有在有 Lifecycle Bean 时才有被调用的价值。那么我们自定义 Lifecycle Bean 一般是用来做什么呢?例如,可以用它来实现运行中的启停。这里不再拓展,你可以自己做更深入的探索。
通过这个案例,我们搞定了第一类错误。而从这个错误中,我们也得出了一个启示:当一个事件拦截不了时,我们第一个要查的是拦截的事件类型对不对,执行的代码能不能抛出它。把握好这点,也就事半功倍了。
案例 2:监听事件的体系不对
通过案例 1 的学习,我们可以保证事件的抛出,但是抛出的事件就一定能被我们监听到么?我们再来看这样一个案例,首先上代码:
@Slf4j
@Component
public class MyApplicationEnvironmentPreparedEventListener implements ApplicationListener<ApplicationEnvironmentPreparedEvent > {
public void onApplicationEvent(final ApplicationEnvironmentPreparedEvent event) {
log.info("{} received: {}", this.toString(), event);
}
}
这里我们试图处理 ApplicationEnvironmentPreparedEvent。期待出现拦截事件的日志如下:
2021-03-07 09:12:08.886 INFO 27064 — [ restartedMain] licationEnvironmentPreparedEventListener : com.spring.puzzle.class7.example2.MyApplicationEnvironmentPreparedEventListener@2b093d received: org.springframework.boot.context.event.ApplicationEnvironmentPreparedEvent[source=org.springframework.boot.SpringApplication@122b9e6]
有了案例 1 的经验,首先我们就可以查看下这个事件的抛出会不会存在问题。这个事件在 Spring 中是由 EventPublishingRunListener#environmentPrepared 方法抛出,代码如下:
@Override
public void environmentPrepared(ConfigurableEnvironment environment) {
this.initialMulticaster
.multicastEvent(new ApplicationEnvironmentPreparedEvent(this.application, this.args, environment));
}
现在我们调试下代码,你会发现这个方法在 Spring 启动时一定经由 SpringApplication#prepareEnvironment 方法调用,调试截图如下:
表面上看,既然代码会被调用,事件就会抛出,那么我们在最开始定义的监听器就能处理,但是我们真正去运行程序时会发现,效果和案例 1 是一样的,都是监听器的处理并不执行,即拦截不了。这又是为何?
案例解析
实际上,这是在 Spring 事件处理上非常容易犯的一个错误,即监听的体系不一致。通俗点说,就是“驴头不对马嘴”。我们首先来看下关于 ApplicationEnvironmentPreparedEvent 的处理,它相关的两大组件是什么?
- 广播器:这个事件的广播器是 EventPublishingRunListener 的 initialMulticaster,代码参考如下:
public class EventPublishingRunListener implements SpringApplicationRunListener, Ordered {
//省略非关键代码
private final SimpleApplicationEventMulticaster initialMulticaster;
public EventPublishingRunListener(SpringApplication application, String[] args) {
//省略非关键代码
this.initialMulticaster = new SimpleApplicationEventMulticaster();
for (ApplicationListener<?> listener : application.getListeners()) {
this.initialMulticaster.addApplicationListener(listener);
}
}
}
- 监听器:这个事件的监听器同样位于 EventPublishingRunListener 中,获取方式参考关键代码行:
this.initialMulticaster.addApplicationListener(listener);
如果继续查看代码,我们会发现这个事件的监听器就存储在 SpringApplication#Listeners 中,调试下就可以找出所有的监听器,截图如下:
从中我们可以发现并不存在我们定义的 MyApplicationEnvironmentPreparedEventListener,这是为何?
还是查看代码,当 Spring Boot 被构建时,会使用下面的方法去寻找上述监听器:
setListeners((Collection) getSpringFactoriesInstances(ApplicationListener.class));
而上述代码最终寻找 Listeners 的候选者,参考代码 SpringFactoriesLoader#loadSpringFactories 中的关键行:
// 下面的 FACTORIES_RESOURCE_LOCATION 定义为 "META-INF/spring.factories"classLoader.getResources(FACTORIES_RESOURCE_LOCATION) :
我们可以寻找下这样的文件(spring.factories),确实可以发现类似的定义:
org.springframework.context.ApplicationListener=\
org.springframework.boot.ClearCachesApplicationListener,\
org.springframework.boot.builder.ParentContextCloserApplicationListener,\
org.springframework.boot.cloud.CloudFoundryVcapEnvironmentPostProcessor,\
//省略其他监听器
说到这里,相信你已经意识到本案例的问题所在。我们定义的监听器并没有被放置在 META-INF/spring.factories 中,实际上,我们的监听器监听的体系是另外一套,其关键组件如下:
- 广播器:即 AbstractApplicationContext#applicationEventMulticaster;
- 监听器:由上述提及的 META-INF/spring.factories 中加载的监听器以及扫描到的 ApplicationListener 类型的 Bean 共同组成。
这样比较后,我们可以得出一个结论:我们定义的监听器并不能监听到 initialMulticaster 广播出的 ApplicationEnvironmentPreparedEvent。
问题修正
现在就到了解决问题的时候了,我们可以把自定义监听器注册到 initialMulticaster 广播体系中,这里提供两种方法修正问题。
- 在构建 Spring Boot 时,添加 MyApplicationEnvironmentPreparedEventListener:
@SpringBootApplication
public class Application {
public static void main(String[] args) {
MyApplicationEnvironmentPreparedEventListener myApplicationEnvironmentPreparedEventListener = new MyApplicationEnvironmentPreparedEventListener();
SpringApplication springApplication = new SpringApplicationBuilder(Application.class).listeners(myApplicationEnvironmentPreparedEventListener).build();
springApplication.run(args);
}
}
- 使用 META-INF/spring.factories,即在 /src/main/resources 下面新建目录 META-INF,然后新建一个对应的 spring.factories 文件:
org.springframework.context.ApplicationListener=\
com.spring.puzzle.listener.example2.MyApplicationEnvironmentPreparedEventListener
通过上述两种修改方式,即可完成事件的监听,很明显第二种方式要优于第一种,至少完全用原生的方式去解决,而不是手工实例化一个 MyApplicationEnvironmentPreparedEventListener。这点还是挺重要的。
反思这个案例的错误,结论就是对于事件一定要注意“驴头”(监听器)对上“马嘴”(广播)。
案例 3:部分事件监听器失效
通过前面案例的解析,我们可以确保事件在合适的时机被合适的监听器所捕获。但是理想总是与现实有差距,有些时候,我们可能还会发现部分事件监听器一直失效或偶尔失效。这里我们可以写一段代码来模拟偶尔失效的场景,首先我们完成一个自定义事件和两个监听器,代码如下:
public class MyEvent extends ApplicationEvent {
public MyEvent(Object source) {
super(source);
}
}
@Component
@Order(1)
public class MyFirstEventListener implements ApplicationListener<MyEvent> {
Random random = new Random();
@Override
public void onApplicationEvent(MyEvent event) {
log.info("{} received: {}", this.toString(), event);
//模拟部分失效
if(random.nextInt(10) % 2 == 1)
throw new RuntimeException("exception happen on first listener");
}
}
@Component
@Order(2)
public class MySecondEventListener implements ApplicationListener<MyEvent> {
@Override
public void onApplicationEvent(MyEvent event) {
log.info("{} received: {}", this.toString(), event);
}
}
这里监听器 MyFirstEventListener 的优先级稍高,且执行过程中会有 50% 的概率抛出异常。然后我们再写一个 Controller 来触发事件的发送:
@RestController
@Slf4j
public class HelloWorldController {
@Autowired
private AbstractApplicationContext applicationContext;
@RequestMapping(path = "publishEvent", method = RequestMethod.GET)
public String notifyEvent(){
log.info("start to publish event");
applicationContext.publishEvent(new MyEvent(UUID.randomUUID()));
return "ok";
};
}
完成这些代码后,我们就可以使用http://localhost:8080/publishEvent 来测试监听器的接收和执行了。观察测试结果,我们会发现监听器 MySecondEventListener 有一半的概率并没有接收到任何事件。可以说,我们使用了最简化的代码模拟出了部分事件监听器偶尔失效的情况。当然在实际项目中,抛出异常这个根本原因肯定不会如此明显,但还是可以借机举一反三的。那么如何理解这个问题呢?
案例解析
这个案例非常简易,如果你稍微有些开发经验的话,大概也能推断出原因:处理器的执行是顺序执行的,在执行过程中,如果一个监听器执行抛出了异常,则后续监听器就得不到被执行的机会了。这里我们可以通过 Spring 源码看下事件是如何被执行的?
具体而言,当广播一个事件,执行的方法参考 SimpleApplicationEventMulticaster#multicastEvent(ApplicationEvent):
@Override
public void multicastEvent(final ApplicationEvent event, @Nullable ResolvableType eventType) {
ResolvableType type = (eventType != null ? eventType : resolveDefaultEventType(event));
Executor executor = getTaskExecutor();
for (ApplicationListener<?> listener : getApplicationListeners(event, type)) {
if (executor != null) {
executor.execute(() -> invokeListener(listener, event));
}
else {
invokeListener(listener, event);
}
}
}
上述方法通过 Event 类型等信息调用 getApplicationListeners 获取了具有执行资格的所有监听器(在本案例中,即为 MyFirstEventListener 和 MySecondEventListener),然后按顺序去执行。最终每个监听器的执行是通过 invokeListener() 来触发的,调用的是接口方法 ApplicationListener#onApplicationEvent。执行逻辑可参考如下代码:
protected void invokeListener(ApplicationListener<?> listener, ApplicationEvent event) {
ErrorHandler errorHandler = getErrorHandler();
if (errorHandler != null) {
try {
doInvokeListener(listener, event);
}
catch (Throwable err) {
errorHandler.handleError(err);
}
}
else {
doInvokeListener(listener, event);
}
}
private void doInvokeListener(ApplicationListener listener, ApplicationEvent event) {
try {
listener.onApplicationEvent(event);
}
catch (ClassCastException ex) {
//省略非关键代码
}
else {
throw ex;
}
}
}
这里我们并没有去设置什么 org.springframework.util.ErrorHandler,也没有绑定什么 Executor 来执行任务,所以针对本案例的情况,我们可以看出:最终事件的执行是由同一个线程按顺序来完成的,任何一个报错,都会导致后续的监听器执行不了。
问题修正
怎么解决呢?好办,我提供两种方案给你。
- 确保监听器的执行不会抛出异常。
既然我们使用多个监听器,我们肯定是希望它们都能执行的,所以我们一定要保证每个监听器的执行不会被其他监听器影响。基于这个思路,我们修改案例代码如下:
@Component
@Order(1)
public class MyFirstEventListener implements ApplicationListener<MyEvent> {
@Override
public void onApplicationEvent(MyEvent event) {
try {
// 省略事件处理相关代码
}catch(Throwable throwable){
//write error/metric to alert
}
}
}
- 使用 org.springframework.util.ErrorHandler
通过上面的案例解析,我们发现,假设我们设置了一个 ErrorHandler,那么就可以用这个 ErrorHandler 去处理掉异常,从而保证后续事件监听器处理不受影响。我们可以使用下面的代码来修正问题:
SimpleApplicationEventMulticaster simpleApplicationEventMulticaster = applicationContext.getBean(APPLICATION_EVENT_MULTICASTER_BEAN_NAME, SimpleApplicationEventMulticaster.class);
simpleApplicationEventMulticaster.setErrorHandler(TaskUtils.LOG_AND_SUPPRESS_ERROR_HANDLER);
其中 LOG_AND_SUPPRESS_ERROR_HANDLER 的实现如下:
public static final ErrorHandler LOG_AND_SUPPRESS_ERROR_HANDLER = new LoggingErrorHandler();
private static class LoggingErrorHandler implements ErrorHandler {
private final Log logger = LogFactory.getLog(LoggingErrorHandler.class);
@Override
public void handleError(Throwable t) {
logger.error("Unexpected error occurred in scheduled task", t);
}
}
对比下方案 1,使用 ErrorHandler 有一个很大的优势,就是我们不需要在某个监听器中都重复类似下面的代码了:
try {
//省略事件处理过程
}catch(Throwable throwable){
//write error/metric to alert
}
这么看的话,其实 Spring 的设计还是很全面的,它考虑了各种各样的情况。但是 Spring 使用者往往都不会去了解其内部实现,这样就会遇到各种各样的问题。相反,如果你对其实现有所了解的话,也对常见错误有一个感知,则大概率是可以快速避坑的,项目也可以运行得更加平稳顺畅。