
- 对于普通的Java对象,当new的时候创建对象,当它没有任何引用的时候被垃圾回收机制回收。
- 而由Spring IoC容器托管的对象,它们的生命周期完全由容器控制。
概括Spring中Bean的生命周期 #
Spring中每个Bean的生命周期如下:
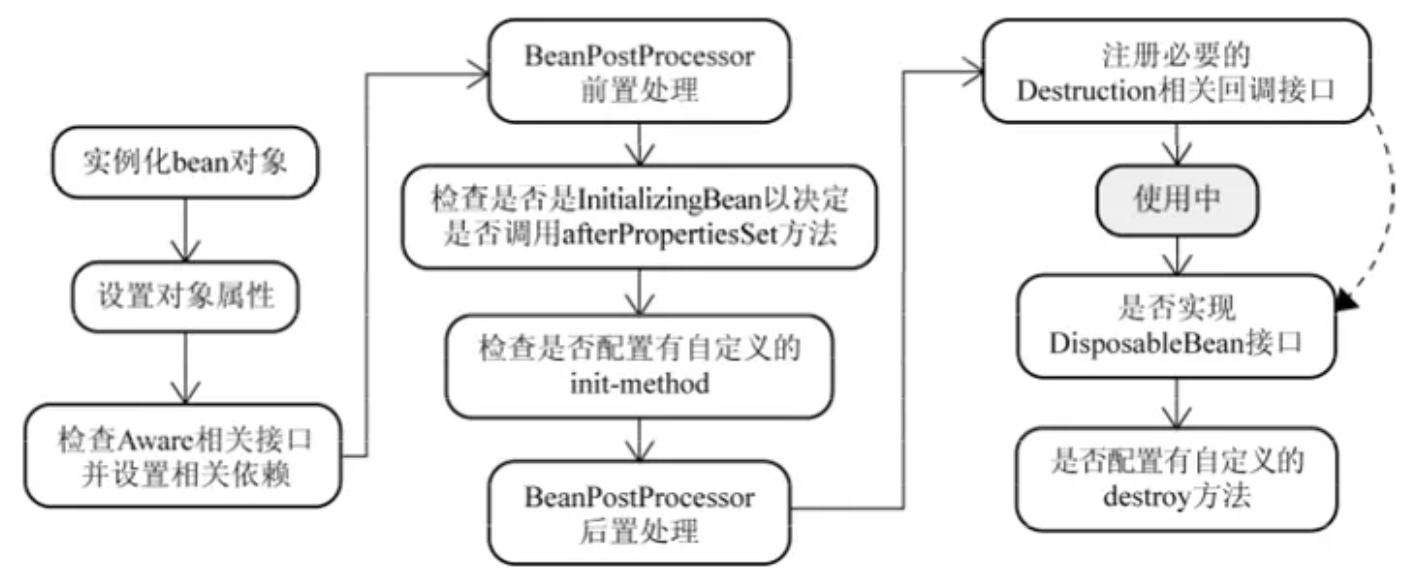
实例化Bean #
BeanFactory和ApplicationContext是Spring框架中两个核心接口,它们都用于管理Bean的生命周期和依赖关系。ApplicationContext继承自BeanFactory接口,ApplicationContext提供了BeanFactory的所有功能,并且添加了更多企业级的特性。
但是,BeanFactory和ApplicationContext在实例化Bean的时机和方式有一定区别。
BeanFactory #
public interface BeanFactory {
Object getBean(String name) throws BeansException;
}
- 惰性初始化:
BeanFactory容器在默认情况下会延迟初始化Bean,即只有在第一次通过getBean()方法请求获取Bean时,或初始化bean的时候需要注入另一个尚未初始化的依赖时,BeanFactory容器才会调用createBean进行实例化和初始化。这种行为称为惰性初始化或按需初始化。 - 手动配置:对于某些需要提前初始化的Bean,可以通过配置Bean的
lazy-init属性为false来实现非惰性初始化,但这需要手动配置。
// BeanFactory 创建 Bean 实例的伪代码
public Object createBean(String beanName) {
BeanDefinition beanDefinition = getBeanDefinition(beanName);
Object bean = instantiateBean(beanDefinition);
BeanWrapper beanWrapper = new BeanWrapperImpl(bean);
return beanWrapper.getWrappedInstance();
}
ApplicationContext #
ApplicationContext容器,当容器启动结束后,便实例化所有的bean。容器通过获取BeanDefinition对象中的信息进行实例化。并且这一步仅仅是简单的实例化,并未进行依赖注入。实例化对象被包装在BeanWrapper对象中,BeanWrapper提供了设置对象属性的接口,从而避免了使用反射机制设置属性。
public interface ApplicationContext extends EnvironmentCapable, ListableBeanFactory, HierarchicalBeanFactory,
MessageSource, ApplicationEventPublisher, ResourcePatternResolver {
}
- 预先实例化:与
BeanFactory不同,ApplicationContext会在容器启动的过程中预先实例化和初始化所有的单例Bean(singleton scope)。这意味着,一旦ApplicationContext容器被创建并启动完成,所有的单例Bean就已经被创建并准备好了,无需等待getBean()方法的调用。 - 自动配置:
ApplicationContext提供了更多的企业级特性,例如国际化支持、事件发布/订阅机制、注解支持等。这些特性往往需要容器在启动时预先加载和初始化相关的Bean,从而为这些高级特性提供支持。
设置对象属性(依赖注入) #
实例化后的对象被封装在BeanWrapper对象中。此时,对象仍然是一个原生的状态,Spring会根据BeanDefinition中的信息进行依赖注入。
public void populateBean(String beanName, BeanDefinition beanDefinition, BeanWrapper beanWrapper) {
PropertyValues pvs = beanDefinition.getPropertyValues();
applyPropertyValues(beanName, beanWrapper, pvs);
}
注入Aware接口 #
Spring会检测Bean是否实现了某些Aware接口(如ApplicationContextAware, BeanNameAware等),并将相应的实例注入给Bean。
if (bean instanceof ApplicationContextAware) {
((ApplicationContextAware)bean).setApplicationContext(this.applicationContext);
}
在Spring框架中,Aware接口允许Bean获得对Spring容器或容器内特定资源的访问权。当一个Bean实现了某个Aware接口后,Spring容器在创建该Bean的过程中将会自动调用相应的Aware接口方法,注入相应的对象或信息。这种机制允许Bean与Spring容器进行交互,获取容器自身的一些信息。
下面是一些常见的Aware接口及其作用:
ApplicationContextAware- 用途:允许Bean获取到
ApplicationContext的引用,即Spring容器本身。 - 方法:
void setApplicationContext(ApplicationContext applicationContext)
- 用途:允许Bean获取到
BeanNameAware- 用途:允许Bean获取到自己在Spring容器中的名字。
- 方法:
void setBeanName(String name)
BeanFactoryAware- 用途:允许Bean获取
BeanFactory的引用,即Bean的工厂。 - 方法:
void setBeanFactory(BeanFactory beanFactory)
- 用途:允许Bean获取
EnvironmentAware- 用途:允许Bean获取到环境相关的信息,比如配置文件中的属性值。
- 方法:
void setEnvironment(Environment environment)
ResourceLoaderAware- 用途:允许Bean获取到资源加载器,可以用来加载外部资源。
- 方法:
void setResourceLoader(ResourceLoader resourceLoader)
import org.springframework.context.ApplicationContext;
import org.springframework.context.ApplicationContextAware;
public class MyBean implements ApplicationContextAware {
private ApplicationContext applicationContext;
@Override
public void setApplicationContext(ApplicationContext applicationContext) {
this.applicationContext = applicationContext;
}
public void doSomething() {
// 使用applicationContext进行某些操作
}
}
在上面的例子中,MyBean 实现了ApplicationContextAware接口。Spring容器在创建MyBean的实例时,会自动调用setApplicationContext方法,并传入当前的ApplicationContext实例。这样,MyBean就能够使用ApplicationContext来执行一些操作,比如获取其他Bean的实例、访问资源文件等。
BeanPostProcessor #
BeanPostProcessor允许对Bean的实例进行额外的处理。这一步发生在Bean的初始化之前和之后。
// BeanPostProcessor 的前置处理
public Object applyBeanPostProcessorsBeforeInitialization(Object existingBean, String beanName) {
Object result = existingBean;
for (BeanPostProcessor processor : this.beanPostProcessors) {
result = processor.postProcessBeforeInitialization(result, beanName);
if (result == null) return existingBean;
}
return result;
}
// BeanPostProcessor 的后置处理
public Object applyBeanPostProcessorsAfterInitialization(Object existingBean, String beanName) {
Object result = existingBean;
for (BeanPostProcessor processor : this.beanPostProcessors) {
result = processor.postProcessAfterInitialization(result, beanName);
if (result == null) return existingBean;
}
return result;
}
InitializingBean与init-method #
当BeanPostProcessor的前置处理完成后,如果Bean实现了InitializingBean接口,Spring将调用afterPropertiesSet方法。同时,如果在Bean定义中指定了init-method,Spring也会在这一阶段调用该方法。
if (bean instanceof InitializingBean) {
((InitializingBean)bean).afterPropertiesSet();
}
// 调用 init-method 指定的初始化方法
invokeInitMethods(String beanName, final Object bean, @Nullable BeanDefinition mbd);
DisposableBean和destroy-method #
当Spring容器关闭时,如果Bean实现了DisposableBean接口,Spring将调用destroy方法。同时,如果在Bean定义中指定了destroy-method,Spring也会在这一阶段调用该方法。
if (bean instanceof DisposableBean) {
((DisposableBean)bean).destroy();
}
// 调用 destroy-method 指定的销毁方法
invokeCustomDestroyMethod(String beanName, final Object bean, String destroyMethodName);
示例 #
考虑一个简单的Bean,它实现了InitializingBean和DisposableBean接口,同时在Bean定义中指定了init-method和destroy-method。
public class MyBean implements InitializingBean, DisposableBean {
private String property;
public void setProperty(String property) {
this.property = property;
}
@Override
public void afterPropertiesSet() throws Exception {
// 初始化逻辑
}
@Override
public void destroy() throws Exception {
// 销毁逻辑
}
public void customInit() {
// 自定义初始化方法
}
public void customDestroy() {
// 自定义销毁方法
}
}
在applicationContext.xml中配置Bean:
<bean id="myBean" class="com.example.MyBean" init-method="customInit" destroy-method="customDestroy">
<property name="property" value="Some value"/>
</bean>
模拟面试 #
面试官:今天要不来聊聊Spring对Bean的生命周期管理?
候选者:嗯,没问题的。很早之前我就看过源码,但Spring源码的实现类都太长了。我也记不得很清楚某些实现类的名字,要不我大概来说下流程?
面试官:没事,你开始吧
候选者:首先要知道的是普通Java对象和Spring所管理的Bean实例化的过程是有些区别的
- 在普通Java环境下创建对象简要的步骤可以分为:
- java源码被编译为为class文件
- 等到类需要被初始化时(比如说new、反射等)
- class文件被虚拟机通过类加载器加载到JVM
- 初始化对象供我们使用
简单来说,可以理解为它是用Class对象作为「模板」进而创建出具体的实例

而Spring所管理的Bean不同的是,除了Class对象之外,还会使用BeanDefinition的实例来描述对象的信息。比如说,我们可以在Spring所管理的Bean有一系列的描述:@Scope、@Lazy、@DependsOn等等,可以理解为Class只描述了类的信息,而BeanDefinition描述了对象的信息
面试官:嗯,这我大致了解你的意思了。你就是想告诉我,Spring有BeanDefinition来存储着我们日常给Spring Bean定义的元数据(@Scope、@Lazy、@DependsOn等等),对吧?
候选者:不愧是你
面试官:赶紧的,继续吧

候选者:Spring在启动的时候需要「扫描」在XML/注解/JavaConfig 中需要被Spring管理的Bean信息。随后,会将这些信息封装成BeanDefinition,最后会把这些信息放到一个beanDefinitionMap中。我记得这个Map的key应该是beanName,value则是BeanDefinition对象,到这里其实就是把定义的元数据加载起来,目前真实对象还没实例化。

候选者:接着会遍历这个beanDefinitionMap,执行BeanFactoryPostProcessor这个Bean工厂后置处理器的逻辑。比如说,我们平时定义的占位符信息,就是通过BeanFactoryPostProcessor的子类PropertyPlaceholderConfigurer进行注入进去。
占位符通常以${…}的形式出现。例如,你可能在Spring的配置文件中有如下的定义:
<bean id="myBean" class="com.example.MyBean"> <property name="someProperty" value="${my.config.value}" /> </bean>这里,
${my.config.value}就是一个占位符,它的值将从Spring的配置源(如properties文件、环境变量等)中获取。
PropertyPlaceholderConfigurer是BeanFactoryPostProcessor的一个子类,用于解析配置文件中的占位符,并用实际的配置值替换这些占位符。BeanFactoryPostProcessor是一个更广泛的接口,它允许对bean的定义(BeanDefinition)进行读取和修改,在容器实例化任何bean之前执行。从Spring 3.1开始,
PropertyPlaceholderConfigurer已经被PropertySourcesPlaceholderConfigurer所取代,后者支持基于新的Environment和PropertySource抽象来解析占位符。使用PropertySourcesPlaceholderConfigurer可以更灵活地处理配置信息。在基于Java的配置中,你可以这样配置
PropertySourcesPlaceholderConfigurer:@Configuration public class AppConfig { @Bean public static PropertySourcesPlaceholderConfigurer placeholderConfigurer() { PropertySourcesPlaceholderConfigurer configurer = new PropertySourcesPlaceholderConfigurer(); configurer.setLocation(new ClassPathResource("application.properties")); return configurer; } }这段配置代码定义了一个
PropertySourcesPlaceholderConfigurerbean,它会加载application.properties文件,并解析文件中定义的占位符。
候选者:当然了,这里我们也可以自定义BeanFactoryPostProcessor来对我们定义好的Bean元数据进行获取或者修改。只是一般我们不会这样干,实际上也很有少的使用场景。

面试官:嗯…
候选者:BeanFactoryPostProcessor后置处理器执行完了以后,就到了实例化对象啦。在Spring里边是通过反射来实现的,一般情况下会通过反射选择合适的构造器来把对象实
例化。但这里把对象实例化,只是把对象给创建出来,而对象具体的属性是还没注入的。比如,我的对象是UserService,而UserService对象依赖着SendService对象,这时候的SendService还是null的
候选者:所以,下一步就是把对象的相关属性给注入。

候选者:相关属性注入完之后,往下接着就是初始化的工作了。首先判断该Bean是否实现了Aware相关的接口,如果存在则填充相关的资源。比如我这边在项目用到的:我希望通过代码程序的方式去获取指定的Spring Bean。我们这边会抽取成一个工具类,去实现ApplicationContextAware接口,来获取ApplicationContext对象进而获取Spring Bean。

候选者:Aware相关的接口处理完之后,就会到BeanPostProcessor后置处理器啦。BeanPostProcessor后置处理器有两个方法,一个是before,一个是after(那肯定是
before先执行、after后执行)

候选者:这个BeanPostProcessor后置处理器是AOP实现的关键(关键子类AnnotationAwareAspectJAutoProxyCreator)。所以,执行完Aware相关的接口就会执行BeanPostProcessor相关子类的before方法。BeanPostProcessor相关子类的before方法执行完,则执行init相关的方法,比如说@PostConstruct、实现了InitializingBean接口、定义的init-method方法。当时我还去官网去看他们的被调用,「执行顺序」分别是:@PostConstruct、实现了InitializingBean接口以及init-method方法。这些都是Spring给我们的「扩展」,像@PostConstruct我就经常用到。

候选者:比如,对象实例化后,我要做些初始化的相关工作或者就启个线程去Kafka拉取数据,等到init方法 执行完之后,就会执行BeanPostProcessor的after方法。
- 使用
InitializingBean接口:通过实现InitializingBean接口的afterPropertiesSet方法,可以在所有必需的属性被设置后添加自定义的初始化逻辑。import org.springframework.beans.factory.InitializingBean; public class MyBean implements InitializingBean { @Override public void afterPropertiesSet() throws Exception { // 初始化逻辑,例如启动线程去Kafka拉取数据 } }
- 使用
@PostConstruct注解:@PostConstruct注解用于在依赖注入完成后执行初始化逻辑。import javax.annotation.PostConstruct; public class MyBean { @PostConstruct public void init() { // 初始化逻辑 } }
- 定义init-method:在Spring的XML配置文件或者使用@Bean注解定义Bean时,可以指定init-method属性,Spring将在Bean的属性设置完成后调用这个方法。
public class MyBean { public void myInitMethod() { // 初始化逻辑 } }<bean id="myBean" class="com.example.MyBean" init-method="myInitMethod"/>或者使用Java配置:
@Bean(initMethod = "myInitMethod") public MyBean myBean() { return new MyBean(); }
BeanPostProcessor的使用;在Bean的初始化方法执行完之后,BeanPostProcessor的postProcessAfterInitialization方法会被调用。这可以用来执行一些在Bean完全初始化后才能执行的后处理逻辑。import org.springframework.beans.factory.config.BeanPostProcessor; public class MyBeanPostProcessor implements BeanPostProcessor { @Override public Object postProcessBeforeInitialization(Object bean, String beanName) { // 初始化之前的处理逻辑 return bean; } @Override public Object postProcessAfterInitialization(Object bean, String beanName) { // 初始化之后的处理逻辑,例如检查Bean是否需要某种代理 return bean; } }通过上述任一方法,您都可以在对象实例化后进行必要的初始化工作。选择哪种方法取决于具体需求以及个人偏好。
@PostConstruct和InitializingBean提供了依赖注入完成后立即执行初始化代码的方式,而BeanPostProcessor则提供了更为灵活的在Bean初始化前后执行自定义逻辑的能力。
候选者:基本重要的流程已经走完了,我们就可以获取到对象去使用了
候选者:销毁的时候就看有没有配置相关的destroy方法,执行就完事了
面试官:嗯,了解,**你看过Spring是怎么解决循环依赖的吗?**如果现在有个A对象,它的属性是B对象,而B对象的属性也是A对象,说白了就是A依赖B,而B又依赖A,Spring是怎么做的?
候选者:嗯,这块我也是看过的,其实也是在Spring的生命周期里面嘛。从上面我们可以知道,对象属性的注入在对象实例化之后的嘛。它的大致过程是这样的:
- 首先A对象实例化,然后对属性进行注入,发现依赖B对象
- B对象此时还没创建出来,所以转头去实例化B对象
- B对象实例化之后,发现需要依赖A对象,那A对象已经实例化了嘛,所以B对象最终能完成创建
- B对象返回到A对象的属性注入的方法上,A对象最终完成创建
上面就是大致的过程;
面试官:听起来你还会原理哦?
候选者:Absolutely。至于原理,其实就是用到了三级的缓存。所谓的三级缓存其实就是三个Map。首先明确一点,我对这里的三级缓存定义是这样的:
- singletonObjects(一级,日常实际获取Bean的地方);
- earlySingletonObjects(二级,还没进行属性注入,由三级缓存放进来);
- singletonFactories(三级,Value是一个对象工厂);

候选者:再回到刚才讲述的过程中,A对象实例化之后,属性注入之前,其实会把A对象放入三级缓存中。key是BeanName,Value是ObjectFactory。等到A对象属性注入时,发现依赖B,又去实例化B时,B属性注入需要去获取A对象,这里就是从三级缓存里拿出ObjectFactory,从ObjectFactory得到对应的Bean(就是对象A),把三级缓存的A记录给干掉,然后放到二级缓存中
候选者。显然,二级缓存存储的key是BeanName,value就是Bean(这里的Bean还没做完属性注入
相关的工作)。等到完全初始化之后,就会把二级缓存给remove掉,塞到一级缓存中。我们自己去getBean的时候,实际上拿到的是一级缓存的,大致的过程就是这样。
面试官:那我想问一下,为什么是三级缓存?
候选者:首先从第三级缓存说起(就是key是BeanName,Value为ObjectFactory)。我们的对象是单例的,有可能A对象依赖的B对象是有AOP的(B对象需要代理)。假设没有第三级缓存,只有第二级缓存(Value存对象,而不是工厂对象)。那如果有AOP的情况下,岂不是在存入第二级缓存之前都需要先去做AOP代理 ?这不合适嘛。
候选者:这里肯定是需要考虑代理的情况的,比如A对象是一个被AOP增量的对象,B依赖A时,得到的A肯定是代理对象的。所以,三级缓存的Value是ObjectFactory,可以从里边拿到代理对象。而二级缓存存在的必要就是为了性能,从三级缓存的工厂里创建出对象,再扔到二级缓存(这样就不用每次都要从工厂里拿)。应该很好懂吧?

面试官:确实。
总结:首先是Spring Bean的生命周期过程,Spring使用BeanDefinition来装载着我们给Bean定义的元数据。实例化Bean的时候实际上就是遍历BeanDefinitionMap,Spring的Bean实例化和属性赋值是分开两步来做的,在Spring Bean的生命周期,Spring预留了很多的hook给我们去扩展:
- Bean实例化之前有BeanFactoryPostProcessor
- Bean实例化之后,初始化时,有相关的Aware接口供我们去拿到Context相关信息
- 环绕着初始化阶段,有BeanPostProcessor(AOP的关键)
- 在初始化阶段,有各种的init方法供我们去自定义
而循环依赖的解决主要通过三级的缓存,在实例化后,会把自己扔到三级缓存(此时的key是BeanName,Value是ObjectFactory),在注入属性时,发现需要依赖B,也会走B的实例化过程,B属性注入依赖A,从三级缓存找到A,删掉三级缓存,放到二级缓存。
关键源码方法 #
强烈建议自己去撸一遍
org.springframework .context.support.AbstractApplicationContext#refresh (入口)org.springframework.context.supportAbstractApplicationContext#finishBeanFactoryInitialization (初始化单例对象入口)org.springframework.beans.factory.configConfigurableListableBeanFactory#preInstantiateSingletons (初始化单例对象入口)org.springframework.beans.factory.support.AbstractBeanFactory#getBean(java.lang.String) (万恶之源,获取并创建Bean的入口)org.springframework.beans.factory.support.AbstractBeanFactory#doGetBean (实际的获取并创建Bean的实现)org.springframework.beans.factory.support.DefaultSingletonBeanRegistry#getSingleton(java.lang.String) (从缓存中尝试获取)org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory#createBean(java.lang.String, org.springframework.beans.factory.support.RootBeanDefinition, java.lang.Object[])(实例化Bean)org.springframework.beans.factory.supportAbstractAutowireCapableBeanFactory#doCreateBean(实例化Bean具体实现)org.springframework.beans.factory.supportAbstractAutowireCapableBeanFactory#createBeanInstance(具体实例化过程)org.springframework.beans.factory.support.DefaultSingletonBeanRegistry#addSingletonFactory (将实例化后的Bean添加到三级缓存)org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory#populateBean (实例化后属性注入)org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory#initializeBean(java.lang.String, java.lang.Object, org.springframework.beans.factory.support.RootBeanDefinition) (初始化入口)