
RPC 的全称是 Remote Procedure Call Protocol,中文名是远程过程调用协议。
通俗点讲就是:客户端在不知道调用细节的情况下,调用存在于远程计算机上的某个对象,就像调用本地应用程序中的对象一样。举个例子:两个不同的服务 A、B 部署在两台不同的机器上,服务 A 如果想要调用服务 B 中的某个方法的话就可以通过 RPC 来做。
官方的描述是:一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。
RPC 的特点
- RPC 是一种协议。RPC实现包括:Dubbo、Thrift、GRPC、Netty等。
- 网络协议和网络 IO 模型对其透明。RPC 的客户端认为自己是在调用本地对象,因此其对使用的网络协议( HTTP 协议等)以及网络 IO 模型,是不关心的。
- 信息格式对其透明。调用方法是需要传递参数的,对于远程调用来说,传递过程中参数的信息格式是怎样构成,以及提供者如何使用这些参数,都是不用关心的。
- 有跨语言能力。因为调用方实际上也不清楚远程服务器的应用程序是使用什么语言运行的。那么对于调用方来说,无论服务器方使用的是什么语言,本次调用都应该成功,并且返回值也应该按照调用方程序语言所能理解的形式进行描述。
RPC 原理 #
- 客户端(服务消费端):调用远程方法的一端。
- 客户端 Stub(桩):这其实就是一代理类。代理类主要做的事情很简单,就是把你调用方法、类、方法参数等信息传递到服务端。
- 网络传输:网络传输就是你要把你调用的方法的信息比如说参数啊这些东西传输到服务端,然后服务端执行完之后再把返回结果通过网络传输给你传输回来。网络传输的实现方式有很多种比如最基本的 Socket 或者性能以及封装更加优秀的 Netty(推荐)。
- 服务端 Stub(桩):这个桩就不是代理类了。我觉得理解为桩实际不太好,大家注意一下就好。这里的服务端 Stub 实际指的就是接收到客户端执行方法的请求后,去执行对应的方法然后返回结果给客户端的类。
- 服务端(服务提供端):提供远程方法的一端。
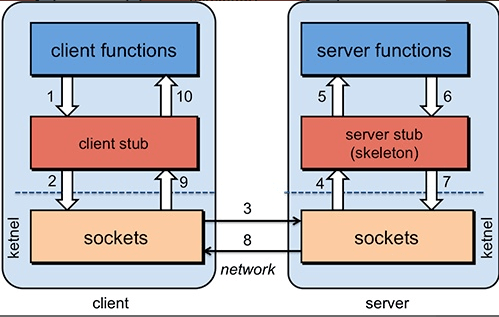
- 服务消费端(client)以本地调用的方式调用远程服务;
- 客户端 Stub(client stub) 接收到调用后负责将方法、参数等组装成能够进行网络传输的消息体(序列化):RpcRequest;
- 客户端 Stub(client stub) 找到远程服务的地址,并将消息发送到服务提供端;
- 服务端 Stub(桩)收到消息将消息反序列化为 Java 对象: RpcRequest;
- 服务端 Stub(桩)根据RpcRequest中的类、方法、方法参数等信息调用本地的方法;
- 服务端 Stub(桩)得到方法执行结果并将组装成能够进行网络传输的消息体:RpcResponse(序列化)发送至消费方;
- 客户端 Stub(client stub)接收到消息并将消息反序列化为 Java 对象: RpcResponse ,这样也就得到了最终结果。over!
哪些框架支持 RPC? #
Dubbo #

Apache Dubbo 是一款微服务框架,为大规模微服务实践提供高性能 RPC 通信、流量治理、可观测性等解决方案, 涵盖 Java、Golang 等多种语言 SDK 实现。
Dubbo 提供了从服务定义、服务发现、服务通信到流量管控等几乎所有的服务治理能力,支持 Triple 协议(基于 HTTP/2 之上定义的下一代 RPC 通信协议)、应用级服务发现、Dubbo Mesh (Dubbo3 赋予了很多云原生友好的新特性)等特性。

- GitHub:https://github.com/apache/incubator-dubbo
- 官网:https://dubbo.apache.org/zh/
Motan
Motan 是新浪微博开源的一款 RPC 框架,据说在新浪微博正支撑着千亿次调用。不过笔者倒是很少看到有公司使用,而且网上的资料也比较少。
很多人喜欢拿 Motan 和 Dubbo 作比较,毕竟都是国内大公司开源的。笔者在查阅了很多资料,以及简单查看了其源码之后发现:Motan 更像是一个精简版的 Dubbo,可能是借鉴了 Dubbo 的思想,Motan 的设计更加精简,功能更加纯粹。
不过,我不推荐你在实际项目中使用 Motan。如果你要是公司实际使用的话,还是推荐 Dubbo ,其社区活跃度以及生态都要好很多。
- 从 Motan 看 RPC 框架设计:http://kriszhang.com/motan-rpc-impl/
- Motan 中文文档:https://github.com/weibocom/motan/wiki/zh_overview
gRPC
gRPC 是 Google 开源的一个高性能、通用的开源 RPC 框架。其由主要面向移动应用开发并基于 HTTP/2 协议标准而设计(支持双向流、消息头压缩等功能,更加节省带宽),基于 ProtoBuf 序列化协议开发,并且支持众多开发语言。
ProtoBuf 是一种更加灵活、高效的数据格式,可用于通讯协议、数据存储等领域,基本支持所有主流编程语言且与平台无关。不过,通过 ProtoBuf 定义接口和数据类型还挺繁琐的,这是一个小问题。
Thrift
Apache Thrift 是 Facebook 开源的跨语言的 RPC 通信框架,目前已经捐献给 Apache 基金会管理,由于其跨语言特性和出色的性能,在很多互联网公司得到应用,有能力的公司甚至会基于 thrift 研发一套分布式服务框架,增加诸如服务注册、服务发现等功能。
Thrift支持多种不同的编程语言,包括C++、Java、Python、PHP、Ruby等(相比于 gRPC 支持的语言更多 )。
- 官网:https://thrift.apache.org/
- Thrift 简单介绍:https://www.jianshu.com/p/8f25d057a5a9
有了 HTTP 协议,为什么还要有 RPC ? #
作为一个程序员,假设我们需要在 A 电脑的进程发一段数据到 B 电脑的进程,我们一般会在代码里使用 socket 进行编程。
这时候,我们可选项一般也就TCP 和 UDP 二选一。TCP 可靠,UDP 不可靠。 除非是马总这种神级程序员(早期 QQ 大量使用 UDP),否则,只要稍微对可靠性有些要求,普通人一般无脑选 TCP 就对了。
类似下面这样。
fd = socket(AF_INET,SOCK_STREAM,0);
其中SOCK_STREAM,是指使用字节流传输数据,说白了就是TCP 协议。
在定义了 socket 之后,我们就可以愉快的对这个 socket 进行操作,比如用bind()绑定 IP 端口,用connect()发起建连。
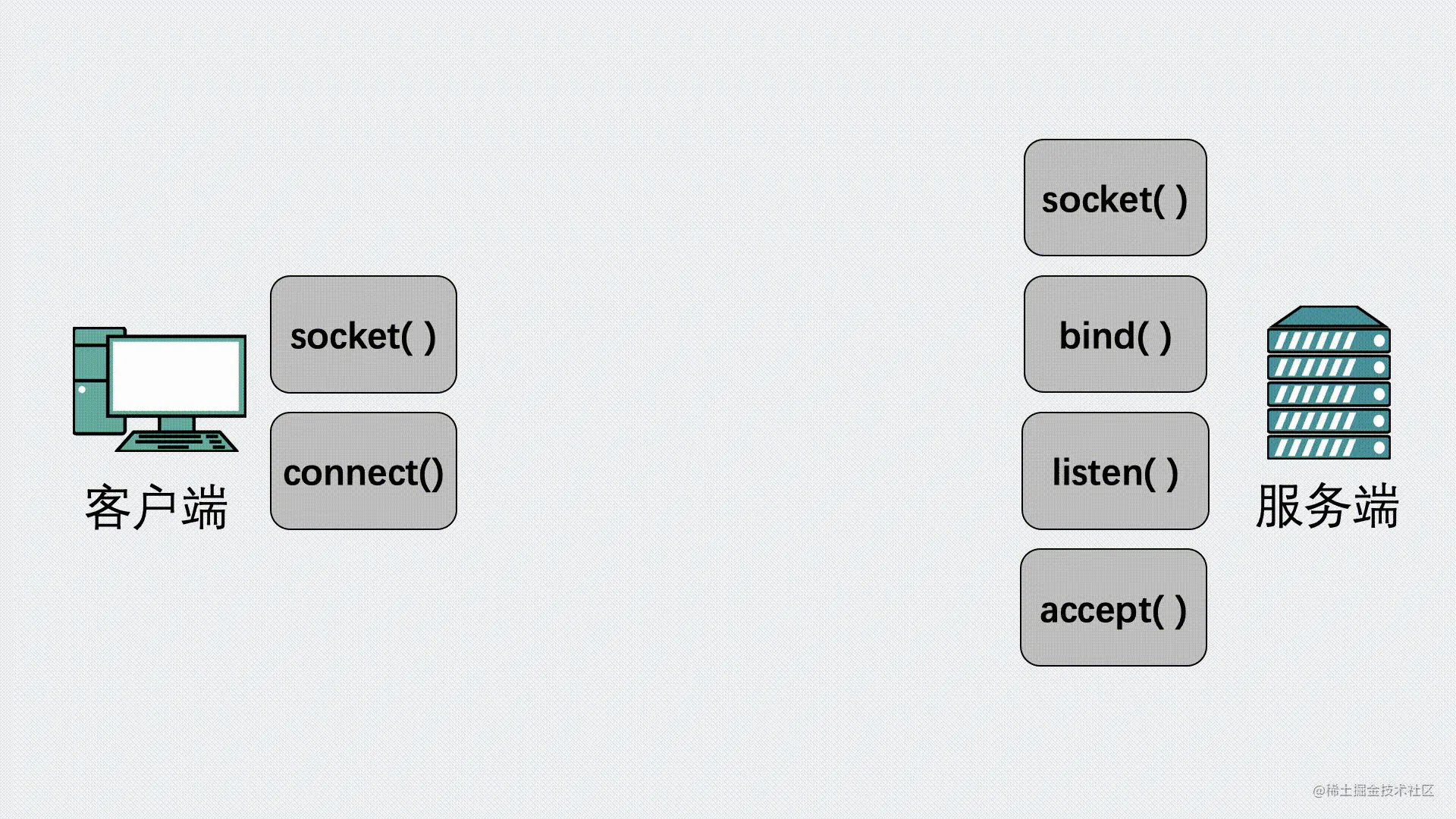
在连接建立之后,我们就可以使用send()发送数据,recv()接收数据。
光这样一个纯裸的 TCP 连接,就可以做到收发数据了,那是不是就够了?
不行,这么用会有问题。
八股文常背,TCP 是有三个特点,面向连接、可靠、基于字节流。
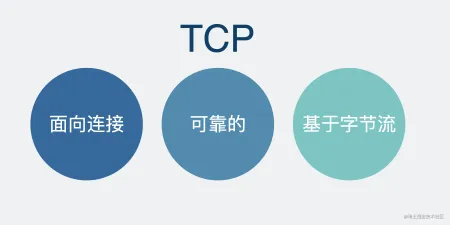
这三个特点真的概括的非常精辟,这个八股文我们没白背。
每个特点展开都能聊一篇文章,而今天我们需要关注的是基于字节流这一点。
字节流可以理解为一个双向的通道里流淌的二进制数据,也就是 01 串 。纯裸 TCP 收发的这些 01 串之间是没有任何边界的,你根本不知道到哪个地方才算一条完整消息。
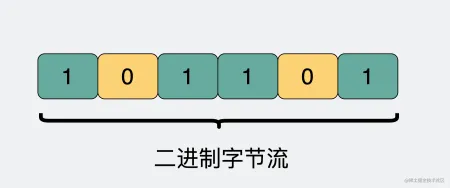
正因为这个没有任何边界的特点,所以当我们选择使用 TCP 发送 “夏洛"和"特烦恼” 的时候,接收端收到的就是 “夏洛特烦恼” ,这时候接收端没发区分你是想要表达 “夏洛”+“特烦恼” 还是 “夏洛特”+“烦恼”
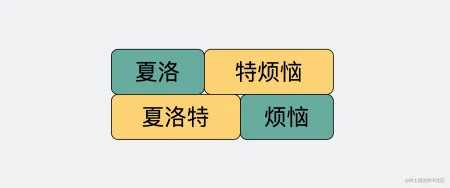
这就是所谓的粘包问题。说这个的目的是为了告诉大家,纯裸 TCP 是不能直接拿来用的,你需要在这个基础上加入一些自定义的规则,用于区分消息边界。
于是我们会把每条要发送的数据都包装一下,比如加入消息头,消息头里写清楚一个完整的包长度是多少,根据这个长度可以继续接收数据,截取出来后它们就是我们真正要传输的消息体。

而这里头提到的消息头,还可以放各种东西,比如消息体是否被压缩过和消息体格式之类的,只要上下游都约定好了,互相都认就可以了,这就是所谓的协议。
每个使用 TCP 的项目都可能会定义一套类似这样的协议解析标准,他们可能 有区别,但原理都类似。
于是基于TCP,就衍生了非常多的协议,比如 HTTP 和 RPC。
HTTP 和 RPC #
RPC 其实是一种调用方式
我们回过头来看网络的分层图。
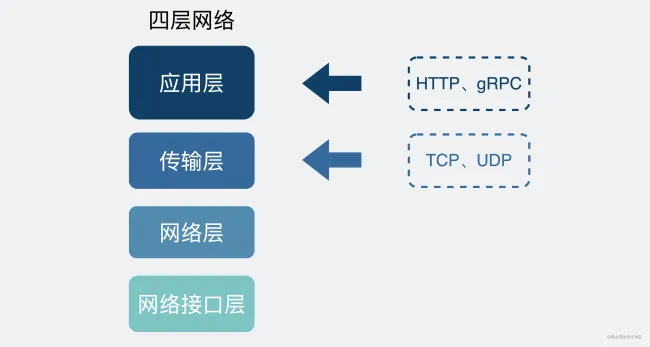
TCP 是传输层的协议 ,而基于 TCP 造出来的 HTTP 和各类 RPC 协议,它们都只是定义了不同消息格式的 应用层协议 而已。
HTTP(Hyper Text Transfer Protocol)协议又叫做 超文本传输协议 。我们用的比较多,平时上网在浏览器上敲个网址就能访问网页,这里用到的就是 HTTP 协议。
而 RPC(Remote Procedure Call)又叫做 远程过程调用,它本身并不是一个具体的协议,而是一种 调用方式 。
举个例子,我们平时调用一个 本地方法 就像下面这样。
res = localFunc(req)
如果现在这不是个本地方法,而是个远端服务器暴露出来的一个方法remoteFunc,如果我们还能像调用本地方法那样去调用它,这样就可以屏蔽掉一些网络细节,用起来更方便,岂不美哉?
res = remoteFunc(req)
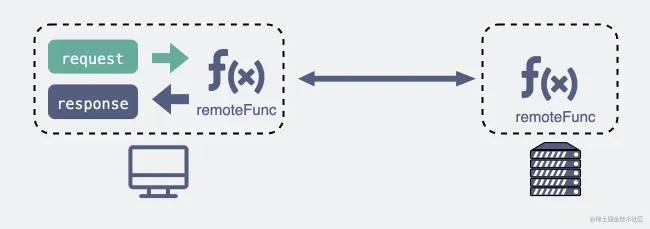
基于这个思路,大佬们造出了非常多款式的 RPC 协议,比如比较有名的gRPC,thrift。
值得注意的是,虽然大部分 RPC 协议底层使用 TCP,但实际上它们不一定非得使用 TCP,改用 UDP 或者 HTTP,其实也可以做到类似的功能。
那既然有 RPC 了,为什么还要有 HTTP 呢?
其实,TCP 是 70 年 代出来的协议,而 HTTP 是 90 年代 才开始流行的。而直接使用裸 TCP 会有问题,可想而知,这中间这么多年有多少自定义的协议,而这里面就有 80 年代 出来的RPC。
所以我们该问的不是 既然有 HTTP 协议为什么要有 RPC ,而是 为什么有 RPC 还要有 HTTP 协议?
现在电脑上装的各种联网软件,比如 xx 管家,xx 卫士,它们都作为客户端(Client) 需要跟服务端(Server) 建立连接收发消息,此时都会用到应用层协议,在这种 Client/Server (C/S) 架构下,它们可以使用自家造的 RPC 协议,因为它只管连自己公司的服务器就 ok 了。
但有个软件不同,浏览器(Browser) ,不管是 Chrome 还是 IE,它们不仅要能访问自家公司的服务器(Server) ,还需要访问其他公司的网站服务器,因此它们需要有个统一的标准,不然大家没法交流。于是,HTTP 就是那个时代用于统一 Browser/Server (B/S) 的协议。
也就是说在多年以前,HTTP 主要用于 B/S 架构,而 RPC 更多用于 C/S 架构。但现在其实已经没分那么清了,B/S 和 C/S 在慢慢融合。 很多软件同时支持多端,比如某度云盘,既要支持网页版,还要支持手机端和 PC 端,如果通信协议都用 HTTP 的话,那服务器只用同一套就够了。而 RPC 就开始退居幕后,一般用于公司内部集群里,各个微服务之间的通讯。
那这么说的话,都用 HTTP 得了,还用什么 RPC?
仿佛又回到了文章开头的样子,那这就要从它们之间的区别开始说起。
HTTP 和 RPC 有什么区别 #
服务发现 #
首先要向某个服务器发起请求,你得先建立连接,而建立连接的前提是,你得知道IP 地址和端口。这个找到服务对应的 IP 端口的过程,其实就是服务发现。
在 HTTP 中,你知道服务的域名,就可以通过 DNS 服务 去解析得到它背后的 IP 地址,默认 80 端口。
而 RPC 的话,就有些区别,一般会有专门的中间服务去保存服务名和 IP 信息,比如 Consul、Etcd、Nacos、ZooKeeper,甚至是 Redis。想要访问某个服务,就去这些中间服务去获得 IP 和端口信息。由于 DNS 也是服务发现的一种,所以也有基于 DNS 去做服务发现的组件,比如 CoreDNS。
可以看出服务发现这一块,两者是有些区别,但不太能分高低。
底层连接形式 #
以主流的 HTTP1.1 协议为例,其默认在建立底层 TCP 连接之后会一直保持这个连接(keep alive),之后的请求和响应都会复用这条连接。
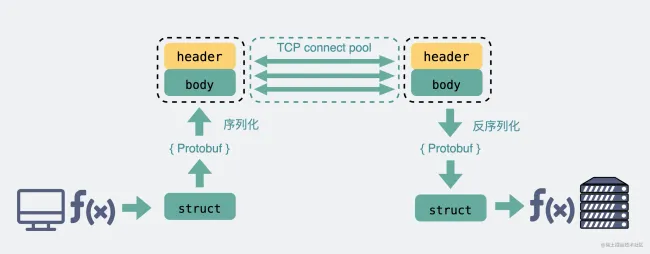
而 RPC 协议,也跟 HTTP 类似,也是通过建立 TCP 长链接进行数据交互,但不同的地方在于,RPC 协议一般还会再建个 连接池,在请求量大的时候,建立多条连接放在池内,要发数据的时候就从池里取一条连接出来,用完放回去,下次再复用,可以说非常环保。
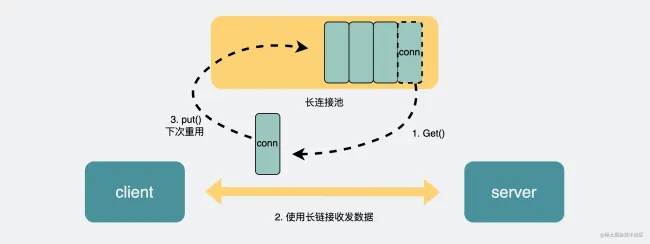
由于连接池有利于提升网络请求性能,所以不少编程语言的网络库里都会给 HTTP 加个连接池,比如 Go 就是这么干的。
可以看出这一块两者也没太大区别,所以也不是关键。
传输的内容 #
基于 TCP 传输的消息,说到底,无非都是 消息头 Header 和消息体 Body。
Header 是用于标记一些特殊信息,其中最重要的是 消息体长度。
Body 则是放我们真正需要传输的内容,而这些内容只能是二进制 01 串,毕竟计算机只认识这玩意。所以 TCP 传字符串和数字都问题不大,因为字符串可以转成编码再变成 01 串,而数字本身也能直接转为二进制。但结构体呢,我们得想个办法将它也转为二进制 01 串,这样的方案现在也有很多现成的,比如 JSON,Protocol Buffers (Protobuf) 。
这个将结构体转为二进制数组的过程就叫 序列化 ,反过来将二进制数组复原成结构体的过程叫 反序列化。
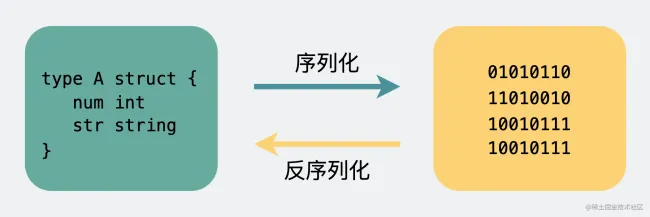
对于主流的 HTTP1.1,虽然它现在叫超文本协议,支持音频视频,但 HTTP 设计 初是用于做网页文本展示的,所以它传的内容以字符串为主。Header 和 Body 都是如此。在 Body 这块,它使用 JSON 来 序列化 结构体数据。
我们可以随便截个图直观看下。
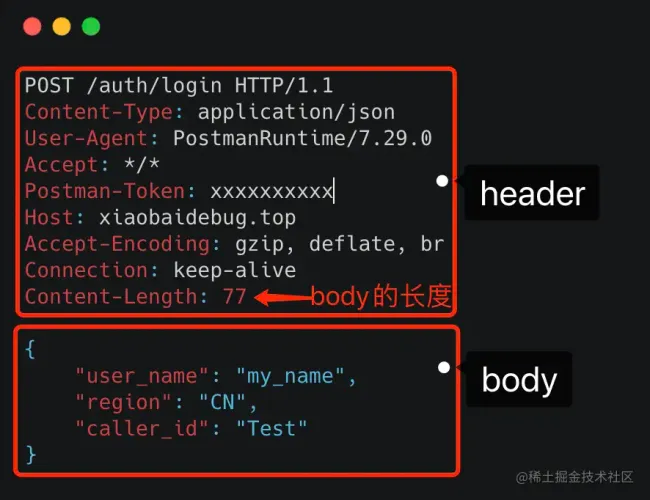
可以看到这里面的内容非常多的冗余,显得非常啰嗦。最明显的,像 Header 里的那些信息,其实如果我们约定好头部的第几位是 Content-Type,就不需要每次都真的把 Content-Type 这个字段都传过来,类似的情况其实在 Body 的 JSON 结构里也特别明显。
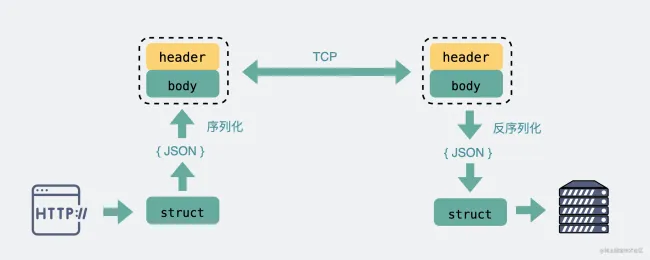
而 RPC,因为它定制化程度更高,可以采用体积更小的 Protobuf 或其他序列化协议去保存结构体数据,同时也不需要像 HTTP 那样考虑各种浏览器行为,比如 302 重定向跳转啥的。因此性能也会更好一些,这也是在公司内部微服务中抛弃 HTTP,选择使用 RPC 的最主要原因。
当然上面说的 HTTP,其实 特指的是现在主流使用的 HTTP1.1,HTTP2在前者的基础上做了很多改进,所以 性能可能比很多 RPC 协议还要好,甚至连gRPC底层都直接用的HTTP2。
为什么既然有了 HTTP2,还要有 RPC 协议?
这个是由于 HTTP2 是 2015 年出来的。那时候很多公司内部的 RPC 协议都已经跑了好些年了,基于历史原因,一般也没必要去换了。