
01 | 核心原理:能否画张图解释下RPC的通信流程? #
从前,面试的时候,被面试官问过一个问题“你能否给我解释下 RPC 的通信流程”。这问题其实并不难,不过因为我平时都在用各种框架,丹并未停下来思考过框架的原理,所以,我吱唔了半天也没说出所以然来。
面试官继续引导“你想想,如果没有 RPC 框架,那你要怎么调用另外一台服务器上的接口呢”这问题可深可浅,也特别考验候选人的基本功。如果你是候选人,你会怎么回答呢?今天我就来试着回答下这个问题。
什么是 RPC?
我知道你肯定不喜欢听概念,我也是这样,看书的时候一看到概念就直接略过。不过,到后来,我才发现,“定义”是一件多么伟大的事情。当我们能够用一句话把一个东西给定义出来的时候,侧面也说明你已经彻底理解这事了,不仅知道它要解决什么问题,还要知道它的边界。所以,你可以先停下来想想,什么是 RPC
RPC 的全称是 Remote Procedure Call,即远程过程调用。简单解读字面上的意思,远程肯定是指要跨机器而非本机,所以需要用到网络编程才能实现,但是不是只要通过网络通信访问到另一台机器的应用程序,就可以称之为 RPC 调用了?显然并不够。
这就好比建在小河上的桥一样连接着河的两岸,如果没有小桥,我们需要通过划船、绕道等其他方式才能到达对面,但是有了小桥之后,我们就能像在路面上一样行走到达对面,并且跟在路面上行走的体验没有区别。所以我认为,RPC 的作用就是体现在这样两个方面:
- 屏蔽远程调用跟本地调用的区别,让我们感觉就是调用项目内的方法;
- 隐藏底层网络通信的复杂性,让我们更专注于业务逻辑。
RPC 通信流程
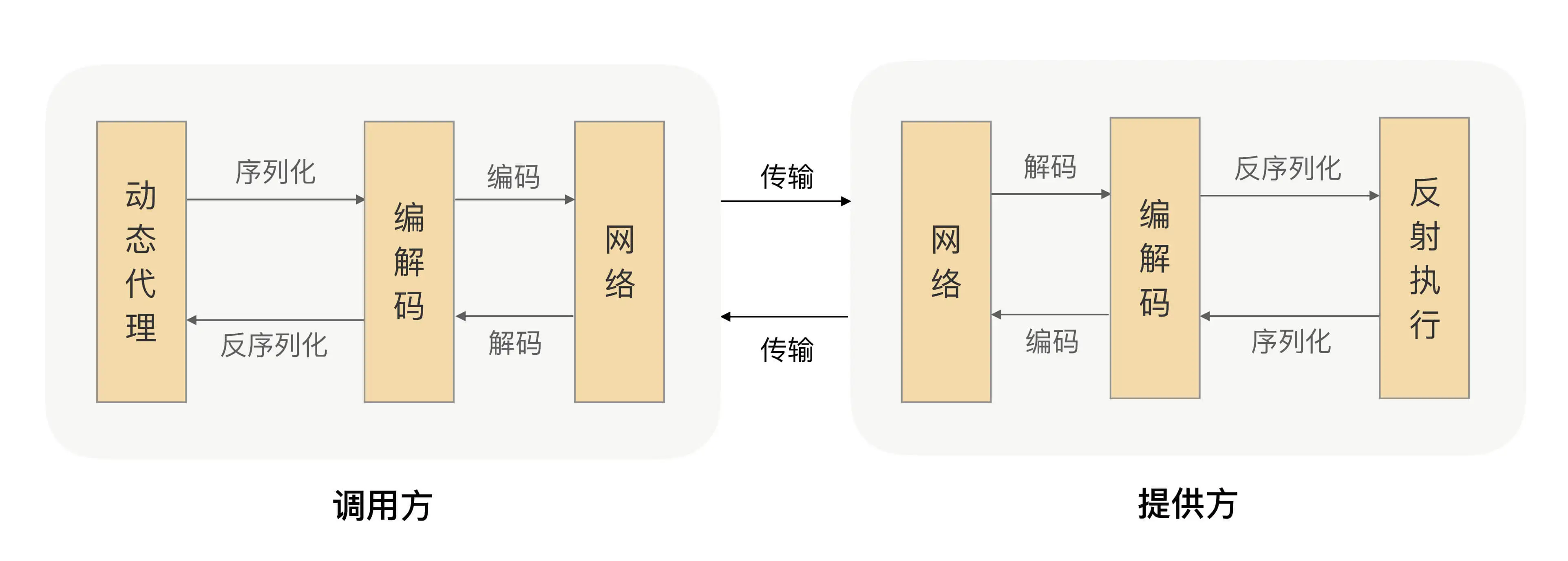
理解了什么是 RPC,接下来我们讲下 RPC 框架的通信流程,方便我们进一步理解 RPC。如前面所讲,RPC 能帮助我们的应用透明地完成远程调用,发起调用请求的那一方叫做调用方,被调用的一方叫做服务提供方。为了实现这个目标,我们就需要在 RPC 框架里面对整个通信细节进行封装,那一个完整的 RPC 会涉及到哪些步骤呢?
我们已经知道 RPC 是一个远程调用,那肯定就需要通过网络来传输数据,并且 RPC 常用于业务系统之间的数据交互,需要保证其可靠性,所以 RPC 一般默认采用 TCP 来传输。我们常用的 HTTP 协议也是建立在 TCP 之上的。
网络传输的数据必须是二进制数据,但调用方请求的出入参数都是对象。对象是肯定没法直接在网络中传输的,需要提前把它转成可传输的二进制,并且要求转换算法是可逆的,这个过程我们一般叫做“序列化”。
调用方持续地把请求参数序列化成二进制后,经过 TCP 传输给了服务提供方。服务提供方从 TCP 通道里面收到二进制数据,那如何知道一个请求的数据到哪里结束,是一个什么类型的请求呢?
在这里我们可以想想高速公路,它上面有很多出口,为了让司机清楚地知道从哪里出去,管理部门会在路上建立很多指示牌,并在指示牌上标明下一个出口是哪里、还有多远。那回到数据包识别这个场景,我们是不是也可以建立一些“指示牌”,并在上面标明数据包的类型和长度,这样就可以正确的解析数据了。确实可以,并且我们把数据格式的约定内容叫做“协议”。大多数的协议会分成两部分,分别是数据头和消息体。数据头一般用于身份识别,包括协议标识、数据大小、请求类型、序列化类型等信息;消息体主要是请求的业务参数信息和扩展属性等。
根据协议格式,服务提供方就可以正确地从二进制数据中分割出不同的请求来,同时根据请求类型和序列化类型,把二进制的消息体逆向还原成请求对象。这个过程叫作“反序列化”。
服务提供方再根据反序列化出来的请求对象找到对应的实现类,完成真正的方法调用,然后把执行结果序列化后,回写到对应的 TCP 通道里面。调用方获取到应答的数据包后,再反序列化成应答对象,这样调用方就完成了一次 RPC 调用。
那上述几个流程就组成了一个完整的 RPC 吗?
在我看来,还缺点东西。因为对于研发人员来说,这样做要掌握太多的 RPC 底层细节,需要手动写代码去构造请求、调用序列化,并进行网络调用,整个 API 非常不友好。
那我们有什么办法来简化 API,屏蔽掉 RPC 细节,让使用方只需要关注业务接口,像调用本地一样来调用远程呢?
如果你了解 Spring,一定对其 AOP 技术很佩服,其核心是采用动态代理的技术,通过字节码增强对方法进行拦截增强,以便于增加需要的额外处理逻辑。其实这个技术也可以应用到 RPC 场景来解决我们刚才面临的问题。
由服务提供者给出业务接口声明,在调用方的程序里面,RPC 框架根据调用的服务接口提前生成动态代理实现类,并通过依赖注入等技术注入到声明了该接口的相关业务逻辑里面。该代理实现类会拦截所有的方法调用,在提供的方法处理逻辑里面完成一整套的远程调用,并把远程调用结果返回给调用方,这样调用方在调用远程方法的时候就获得了像调用本地接口一样的体验。
到这里,一个简单版本的 RPC 框架就实现了。我把整个流程都画出来了,供你参考:
RPC 在架构中的位置
围绕 RPC 我们讲了这么多,那 RPC 在架构中究竟处于什么位置呢?
如刚才所讲,RPC 是解决应用间通信的一种方式,而无论是在一个大型的分布式应用系统还是中小型系统中,应用架构最终都会从“单体”演进成“微服务化”,整个应用系统会被拆分为多个不同功能的应用,并将它们部署在不同的服务器中,而应用之间会通过 RPC 进行通信,可以说 RPC 对应的是整个分布式应用系统,就像是“经络”一样的存在。
那么如果没有 RPC,我们现实中的开发过程是怎样的一个体验呢?
所有的功能代码都会被我们堆砌在一个大项目中,开发过程中你可能要改一行代码,但改完后编译会花掉你 2 分钟,编译完想运行起来验证下结果可能要 5 分钟,是不是很酸爽?更难受的是在人数比较多的团队里面,多人协同开发的时候,如果团队其他人把接口定义改了,你连编译通过的机会都没有,系统直接报错,从而导致整个团队的开发效率都会非常低下。而且当我们准备要上线发版本的时候,QA 也很难评估这次的测试范围,为了保险起见我们只能把所有的功能进行回归测试,这样会导致我们上线新功能的整体周期都特别长。
无论你是研发还是架构师,我相信这种系统架构我们肯定都不能接受,那怎么才能解决这个问题呢?
我们首先都会想到可以采用“分而治之”的思想来进行拆分,但是拆分完的系统怎么保持跟未拆分前的调用方式一样呢?我们总不能因为架构升级,就把所有的代码都推倒重写一遍吧。
RPC 框架能够帮助我们解决系统拆分后的通信问题,并且能让我们像调用本地一样去调用远程方法。利用 RPC 我们不仅可以很方便地将应用架构从“单体”演进成“微服务化”,而且还能解决实际开发过程中的效率低下、系统耦合等问题,这样可以使得我们的系统架构整体清晰、健壮,应用可运维度增强。
当然 RPC 不仅可以用来解决通信问题,它还被用在了很多其他场景,比如:发 MQ、分布式缓存、数据库等。下图是我之前开发的一个应用架构图:
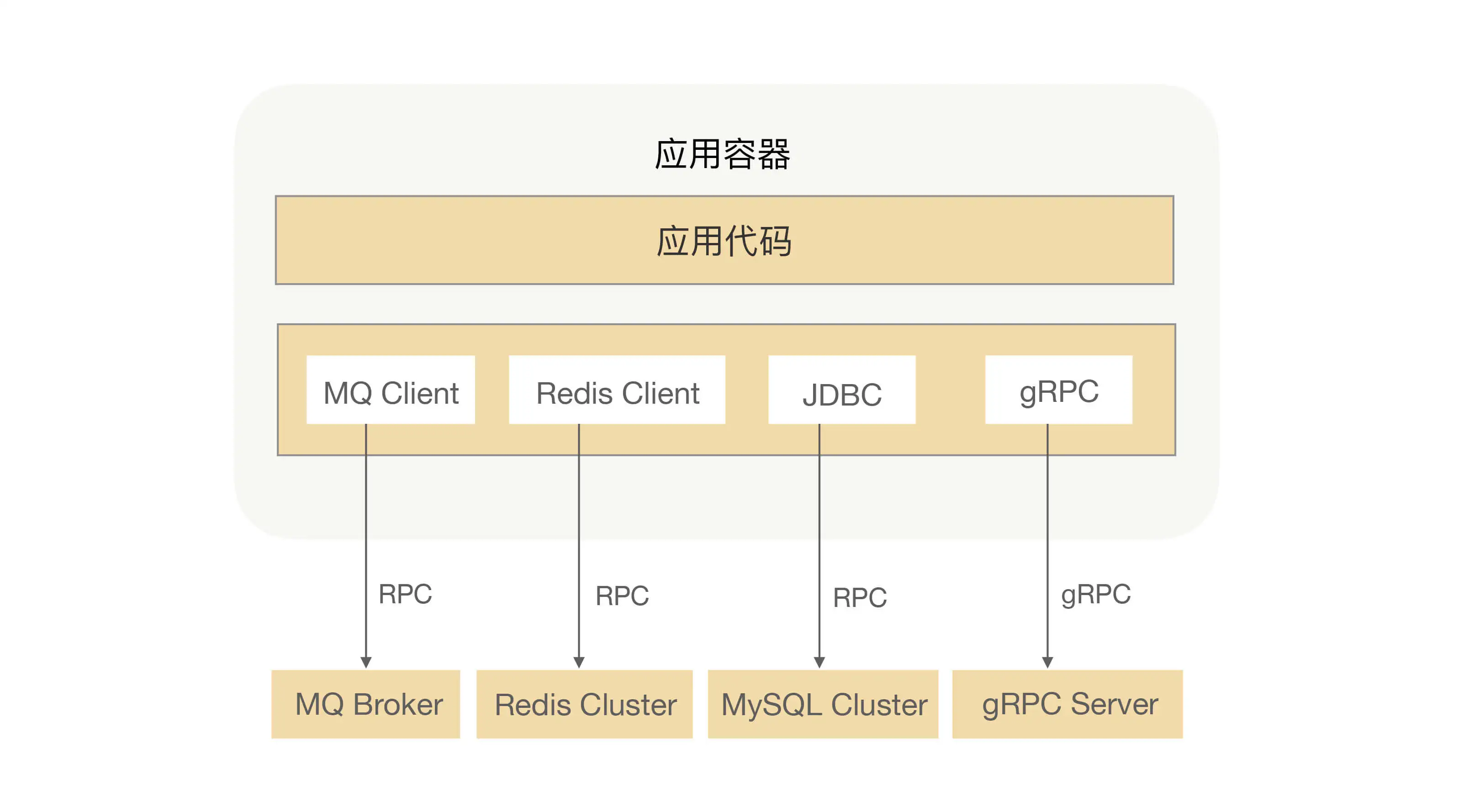
在这个应用中,我使用了 MQ 来处理异步流程、Redis 缓存热点数据、MySQL 持久化数据,还有就是在系统中调用另外一个业务系统的接口,对我的应用来说这些都是属于 RPC 调用,而 MQ、MySQL 持久化的数据也会存在于一个分布式文件系统中,他们之间的调用也是需要用 RPC 来完成数据交互的。
由此可见,RPC 确实是我们日常开发中经常接触的东西,只是被包装成了各种框架,导致我们很少意识到这就是 RPC,让 RPC 变成了我们最“熟悉的陌生人”。现在,回过头想想,我说 RPC 是整个应用系统的“经络”,这不为过吧?我们真的很有必要学好 RPC,不仅因为 RPC 是构建复杂系统的基石,还是提升自身认知的利器。
02 | 协议:怎么设计可扩展且向后兼容的协议? #
一提到协议,你最先想到的可能是 TCP 协议、UDP 协议等等,这些网络传输协议的实现在我看来有点晦涩难懂。虽然在 RPC 中我们也会用到这些协议,但这些协议更多的是对我们上层应用是透明的,我们 RPC 在使用过程中并不太需要关注他们的细节。那我今天要讲的 RPC 协议到底是什么呢?
可能我举个例子,你立马就明白了。HTTP 协议是不是很熟悉(本讲里面所说的 HTTP 默认都是 1.X)? 这应该是我们日常工作中用得最频繁的协议了,每天打开浏览器浏览的网页就是使用的 HTTP 协议。那 HTTP 协议跟 RPC 协议又有什么关系呢?看起来他俩好像不搭边,但他们有一个共性就是都属于应用层协议。
所以我们今天要讲的 RPC 协议就是围绕应用层协议展开的。我们可以先了解下 HTTP 协议,我们先看看它的协议格式是什么样子的。回想一下我们在浏览器里面输入一个 URL 会发生什么?抛开 DNS 解析暂且不谈,浏览器收到命令后会封装一个请求,并把请求发送到 DNS 解析出来的 IP 上,通过抓包工具我们可以抓到请求的数据包,如下图所示:
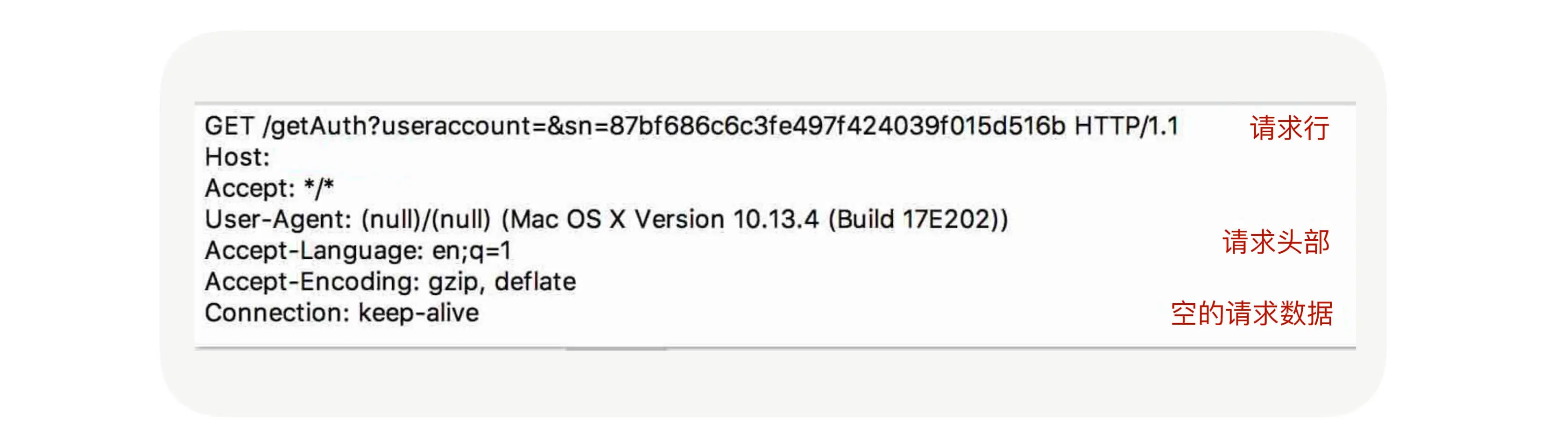
协议的作用
看完 HTTP 协议之后,你可能会有一个疑问,我们为什么需要协议这个东西呢?没有协议就不能通信吗?
我们知道只有二进制才能在网络中传输,所以 RPC 请求在发送到网络中之前,他需要把方法调用的请求参数转成二进制;转成二进制后,写入本地 Socket 中,然后被网卡发送到网络设备中。
但在传输过程中,RPC 并不会把请求参数的所有二进制数据整体一下子发送到对端机器上,中间可能会拆分成好几个数据包,也可能会合并其他请求的数据包(合并的前提是同一个 TCP 连接上的数据),至于怎么拆分合并,这其中的细节会涉及到系统参数配置和 TCP 窗口大小。对于服务提供方应用来说,他会从 TCP 通道里面收到很多的二进制数据,那这时候怎么识别出哪些二进制是第一个请求的呢?这就好比让你读一篇没有标点符号的文章,你要怎么识别出每一句话到哪里结束呢?
很简单啊,我们加上标点,完成断句就好了。
同理在 RPC 传输数据的时候,为了能准确地“断句”,我们也必须在应用发送请求的数据包里面加入“句号”,这样才能帮我们的接收方应用从数据流里面分割出正确的数据。这个数据包里面的句号就是消息的边界,用于标示请求数据的结束位置。举个具体例子,调用方发送 AB、CD、EF 3 个消息,如果没有边界的话,接收端就可能收到 ABCDEF 或者 ABC、DEF 这样的消息,这就会导致接收的语义跟发送的时候不一致了。
所以呢,为了避免语义不一致的事情发生,我们就需要在发送请求的时候设定一个边界,然后在收到请求的时候按照这个设定的边界进行数据分割。这个边界语义的表达,就是我们所说的协议。
如何设计协议?
理解了协议的作用,我们再来看看在 RPC 里面是怎么设计协议的。可能你会问:“前面你不是说了 HTTP 协议跟 RPC 都属于应用层协议,那有了现成的 HTTP 协议,为啥不直接用,还要为 RPC 设计私有协议呢?”
这还要从 RPC 的作用说起,相对于 HTTP 的用处,RPC 更多的是负责应用间的通信,所以性能要求相对更高。但 HTTP 协议的数据包大小相对请求数据本身要大很多,又需要加入很多无用的内容,比如换行符号、回车符等;还有一个更重要的原因是,HTTP 协议属于无状态协议,客户端无法对请求和响应进行关联,每次请求都需要重新建立连接,响应完成后再关闭连接。因此,对于要求高性能的 RPC 来说,HTTP 协议基本很难满足需求,所以 RPC 会选择设计更紧凑的私有协议。
那怎么设计一个私有 RPC 协议呢?
在设计协议前,我们先梳理下要完成 RPC 通信的时候,在协议里面需要放哪些内容。
首先要想到的就是我们前面说的消息边界了,但 RPC 每次发请求发的大小都是不固定的,所以我们的协议必须能让接收方正确地读出不定长的内容。我们可以先固定一个长度(比如 4 个字节)用来保存整个请求数据大小,这样收到数据的时候,我们先读取固定长度的位置里面的值,值的大小就代表协议体的长度,接着再根据值的大小来读取协议体的数据,整个协议可以设计成这样:

但上面这种协议,只实现了正确的断句效果,在 RPC 里面还行不通。因为对于服务提供方来说,他是不知道这个协议体里面的二进制数据是通过哪种序列化方式生成的。如果不能知道调用方用的序列化方式,即使服务提供方还原出了正确的语义,也并不能把二进制还原成对象,那服务提供方收到这个数据后也就不能完成调用了。因此我们需要把序列化方式单独拿出来,类似协议长度一样用固定的长度存放,这些需要固定长度存放的参数我们可以统称为“协议头”,这样整个协议就会拆分成两部分:协议头和协议体。
在协议头里面,我们除了会放协议长度、序列化方式,还会放一些像协议标示、消息 ID、消息类型这样的参数,而协议体一般只放请求接口方法、请求的业务参数值和一些扩展属性。这样一个完整的 RPC 协议大概就出来了,协议头是由一堆固定的长度参数组成,而协议体是根据请求接口和参数构造的,长度属于可变的,具体协议如下图所示:
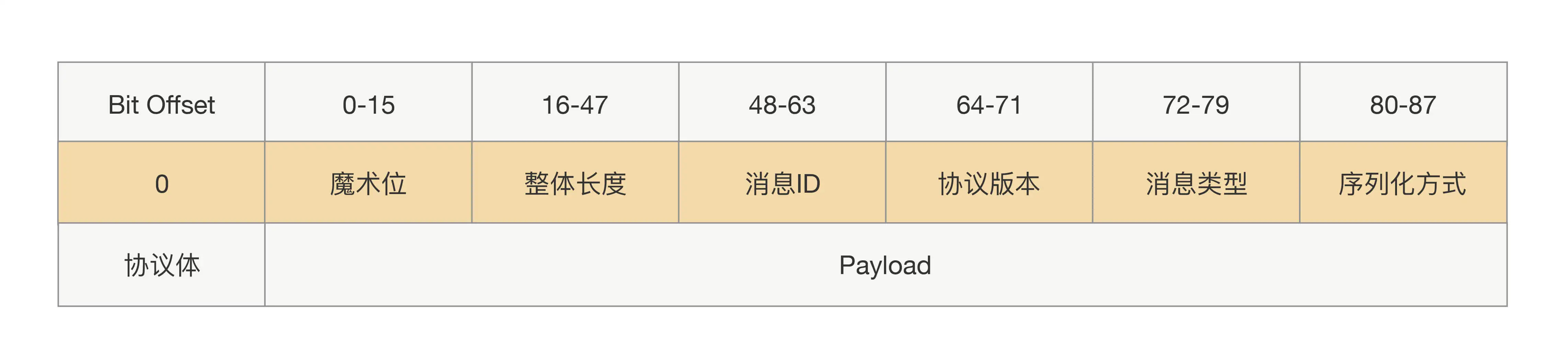
可扩展的协议
刚才讲的协议属于定长协议头,那也就是说往后就不能再往协议头里加新参数了,如果加参数就会导致线上兼容问题。举个具体例子,假设你设计了一个 88Bit 的协议头,其中协议长度占用 32bit,然后你为了加入新功能,在协议头里面加了 2bit,并且放到协议头的最后。升级后的应用,会用新的协议发出请求,然而没有升级的应用收到的请求后,还是按照 88bit 读取协议头,新加的 2 个 bit 会当作协议体前 2 个 bit 数据读出来,但原本的协议体最后 2 个 bit 会被丢弃了,这样就会导致协议体的数据是错的。
可能你会想:“那我把参数加在不定长的协议体里面行不行?而且刚才你也说了,协议体里面会放一些扩展属性。”
没错,协议体里面是可以加新的参数,但这里有一个关键点,就是协议体里面的内容都是经过序列化出来的,也就是说你要获取到你参数的值,就必须把整个协议体里面的数据经过反序列化出来。但在某些场景下,这样做的代价有点高啊!
比如说,服务提供方收到一个过期请求,这个过期是说服务提供方收到的这个请求的时间大于调用方发送的时间和配置的超时时间,既然已经过期,就没有必要接着处理,直接返回一个超时就好了。那要实现这个功能,就要在协议里面传递这个配置的超时时间,那如果之前协议里面没有加超时时间参数的话,我们现在把这个超时时间加到协议体里面是不是就有点重了呢?显然,会加重 CPU 的消耗。
所以为了保证能平滑地升级改造前后的协议,我们有必要设计一种支持可扩展的协议。其关键在于让协议头支持可扩展,扩展后协议头的长度就不能定长了。那要实现读取不定长的协议头里面的内容,在这之前肯定需要一个固定的地方读取长度,所以我们需要一个固定的写入协议头的长度。整体协议就变成了三部分内容:固定部分、协议头内容、协议体内容,前两部分我们还是可以统称为“协议头”,具体协议如下:
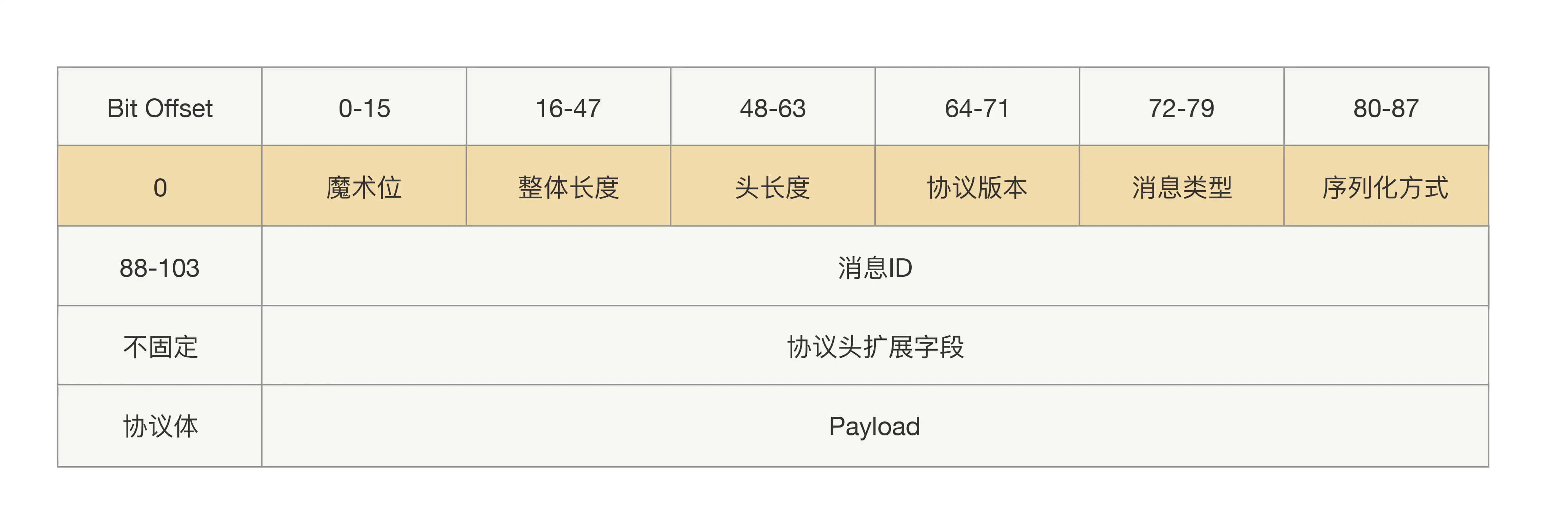
最后,我想说,设计一个简单的 RPC 协议并不难,难的就是怎么去设计一个可“升级”的协议。不仅要让我们在扩展新特性的时候能做到向下兼容,而且要尽可能地减少资源损耗,所以我们协议的结构不仅要支持协议体的扩展,还要做到协议头也能扩展。上述这种设计方法来源于我多年的线上经验,可以说做好扩展性是至关重要的,期待这个协议模版能帮你避掉一些坑。
思考题:在 RPC 里面,我们是怎么实现请求跟响应关联的?
首先我们要弄清楚为什么要把请求与响应关联。这是因为在 RPC 调用过程中,调用端会向服务端发送请求消息,之后它还会收到服务端发送回来的响应消息,但这两个操作并不是同步进行的。在高并发的情况下,调用端可能会在某一时刻向服务端连续发送很多条消息之后,才会陆续收到服务端发送回来的各个响应消息,这时调用端需要一种手段来区分这些响应消息分别对应的是之前的哪条请求消息,所以我们说 RPC 在发送消息时要请求跟响应关联。
解决这个问题不难,只要调用端在收到响应消息之后,从响应消息中读取到一个标识,告诉调用端,这是哪条请求消息的响应消息就可以了。在这一讲中,你会发现我们设计的私有协议都会有消息 ID,这个消息 ID 的作用就是起到请求跟响应关联的作用。调用端为每一个消息生成一个唯一的消息 ID,它收到服务端发送回来的响应消息如果是同一消息 ID,那么调用端就可以认为,这条响应消息是之前那条请求消息的响应消息。
03 | 序列化:对象怎么在网络中传输? #
首先,我们得知道什么是序列化与反序列化。
网络传输的数据必须是二进制数据,但调用方请求的出入参数都是对象。对象是不能直接在网络中传输的,所以我们需要提前把它转成可传输的二进制,并且要求转换算法是可逆的,这个过程我们一般叫做“序列化”。 这时,服务提供方就可以正确地从二进制数据中分割出不同的请求,同时根据请求类型和序列化类型,把二进制的消息体逆向还原成请求对象,这个过程我们称之为“反序列化”。
这两个过程如下图所示:
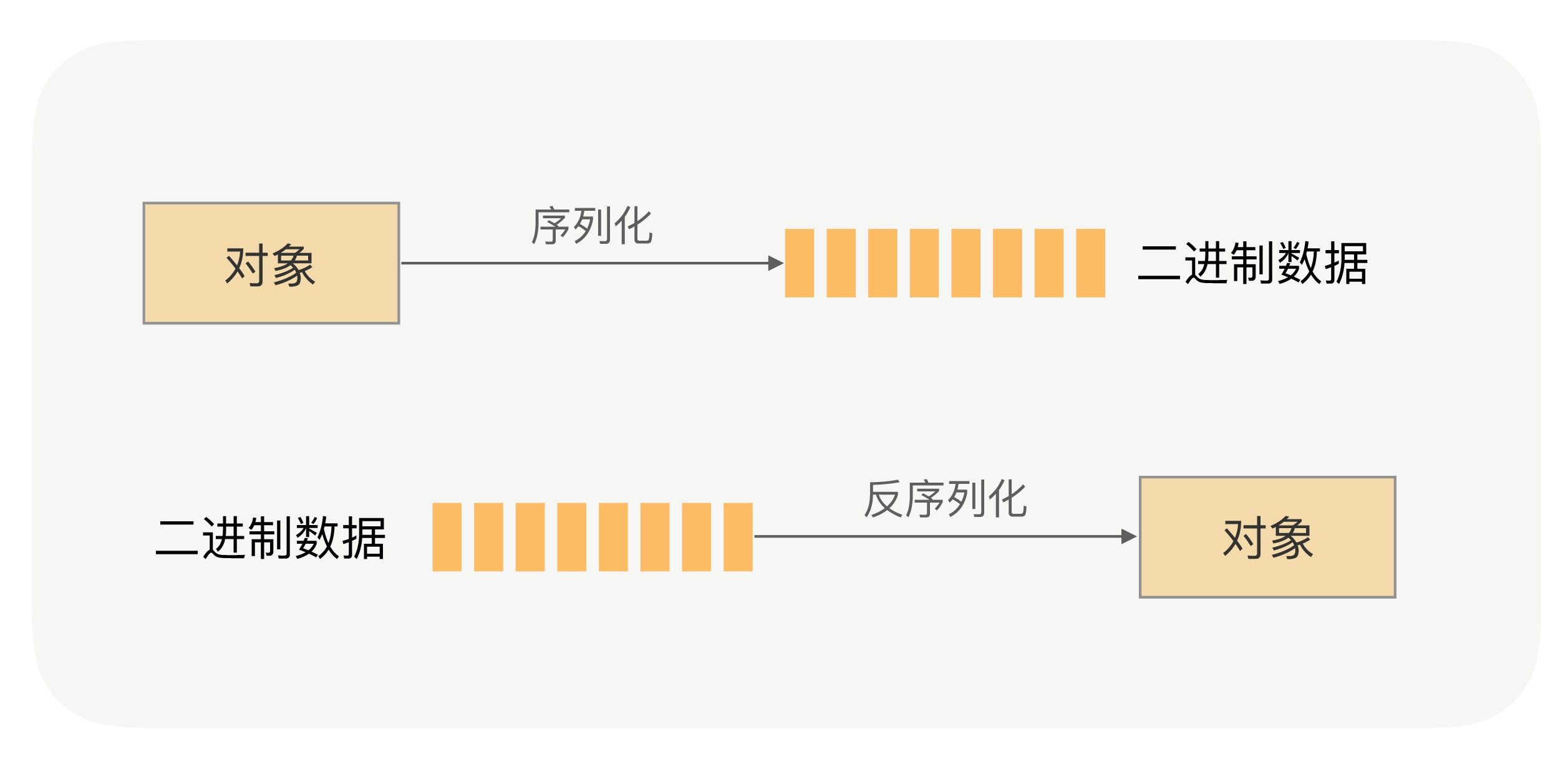
总结来说,序列化就是将对象转换成二进制数据的过程,而反序列就是反过来将二进制转换为对象的过程。
那么 RPC 框架为什么需要序列化呢?还是请你回想下 RPC 的通信流程:
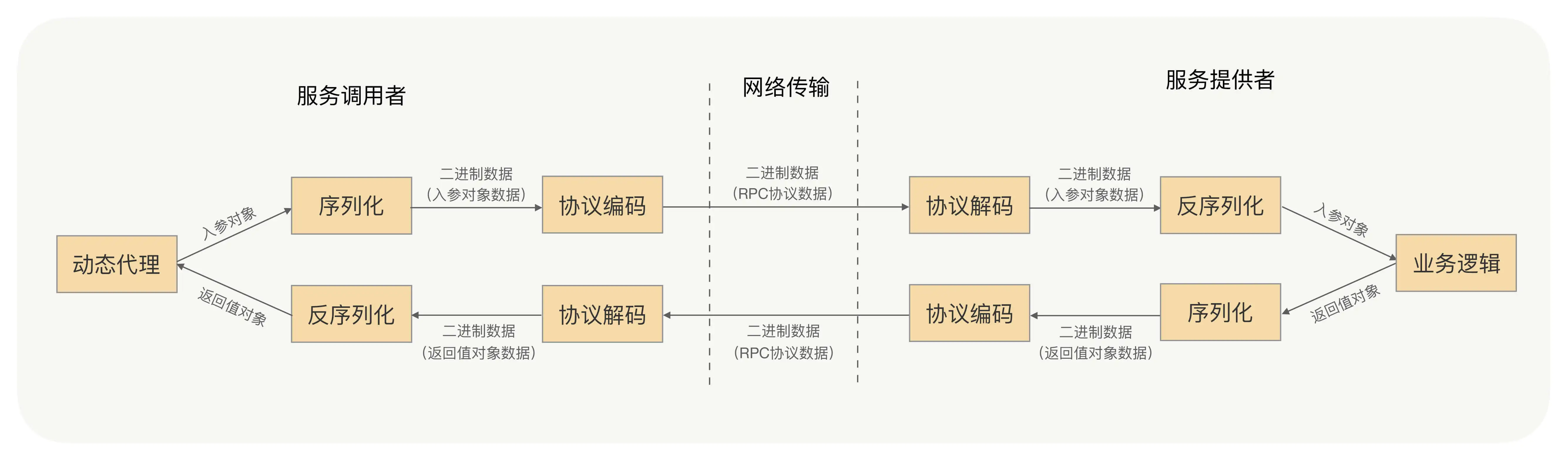
不妨借用个例子帮助你理解,比如发快递,我们要发一个需要自行组装的物件。发件人发之前,会把物件拆开装箱,这就好比序列化;这时候快递员来了,不能磕碰呀,那就要打包,这就好比将序列化后的数据进行编码,封装成一个固定格式的协议;过了两天,收件人收到包裹了,就会拆箱将物件拼接好,这就好比是协议解码和反序列化。
所以现在你清楚了吗?因为网络传输的数据必须是二进制数据,所以在 RPC 调用中,对入参对象与返回值对象进行序列化与反序列化是一个必须的过程。
有哪些常用的序列化?
那这么看来,你会不会觉得这个过程很简单呢?实则不然,很复杂。我们可以先看看都有哪些常用的序列化,下面我来简单地介绍下几种常用的序列化方式。
JDK 原生序列化
如果你会使用 Java 语言开发,那么你一定知道 JDK 原生的序列化,下面是 JDK 序列化的一个例子:
import java.io.*;
public class Student implements Serializable {
//学号
private int no;
//姓名
private String name;
public int getNo() {
return no;
}
public void setNo(int no) {
this.no = no;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Student{" +
"no=" + no +
", name='" + name + '\'' +
'}';
}
public static void main(String[] args) throws IOException, ClassNotFoundException {
String home = System.getProperty("user.home");
String basePath = home + "/Desktop";
FileOutputStream fos = new FileOutputStream(basePath + "student.dat");
Student student = new Student();
student.setNo(100);
student.setName("TEST_STUDENT");
ObjectOutputStream oos = new ObjectOutputStream(fos);
oos.writeObject(student);
oos.flush();
oos.close();
FileInputStream fis = new FileInputStream(basePath + "student.dat");
ObjectInputStream ois = new ObjectInputStream(fis);
Student deStudent = (Student) ois.readObject();
ois.close();
System.out.println(deStudent);
}
}
我们可以看到,JDK 自带的序列化机制对使用者而言是非常简单的。序列化具体的实现是由 ObjectOutputStream 完成的,而反序列化的具体实现是由 ObjectInputStream 完成的。
那么 JDK 的序列化过程是怎样完成的呢?我们看下下面这张图:

序列化过程就是在读取对象数据的时候,不断加入一些特殊分隔符,这些特殊分隔符用于在反序列化过程中截断用。
- 头部数据用来声明序列化协议、序列化版本,用于高低版本向后兼容
- 对象数据主要包括类名、签名、属性名、属性类型及属性值,当然还有开头结尾等数据,除了属性值属于真正的对象值,其他都是为了反序列化用的元数据
- 存在对象引用、继承的情况下,就是递归遍历“写对象”逻辑
实际上任何一种序列化框架,核心思想就是设计一种序列化协议,将对象的类型、属性类型、属性值一一按照固定的格式写到二进制字节流中来完成序列化,再按照固定的格式一一读出对象的类型、属性类型、属性值,通过这些信息重新创建出一个新的对象,来完成反序列化。
JSON
JSON 可能是我们最熟悉的一种序列化格式了,JSON 是典型的 Key-Value 方式,没有数据类型,是一种文本型序列化框架,JSON 的具体格式和特性,网上相关的资料非常多,这里就不再介绍了。
他在应用上还是很广泛的,无论是前台 Web 用 Ajax 调用、用磁盘存储文本类型的数据,还是基于 HTTP 协议的 RPC 框架通信,都会选择 JSON 格式。
但用 JSON 进行序列化有这样两个问题,你需要格外注意:
- JSON 进行序列化的额外空间开销比较大,对于大数据量服务这意味着需要巨大的内存和磁盘开销;
- JSON 没有类型,但像 Java 这种强类型语言,需要通过反射统一解决,所以性能不会太好。
所以如果 RPC 框架选用 JSON 序列化,服务提供者与服务调用者之间传输的数据量要相对较小,否则将严重影响性能。
Hessian
Hessian 是动态类型、二进制、紧凑的,并且可跨语言移植的一种序列化框架。Hessian 协议要比 JDK、JSON 更加紧凑,性能上要比 JDK、JSON 序列化高效很多,而且生成的字节数也更小。
使用代码示例如下:
Student student = new Student();
student.setNo(101);
student.setName("HESSIAN");
//把student对象转化为byte数组
ByteArrayOutputStream bos = new ByteArrayOutputStream();
Hessian2Output output = new Hessian2Output(bos);
output.writeObject(student);
output.flushBuffer();
byte[] data = bos.toByteArray();
bos.close();
//把刚才序列化出来的byte数组转化为student对象
ByteArrayInputStream bis = new ByteArrayInputStream(data);
Hessian2Input input = new Hessian2Input(bis);
Student deStudent = (Student) input.readObject();
input.close();
System.out.println(deStudent);
相对于 JDK、JSON,由于 Hessian 更加高效,生成的字节数更小,有非常好的兼容性和稳定性,所以 Hessian 更加适合作为 RPC 框架远程通信的序列化协议。
但 Hessian 本身也有问题,官方版本对 Java 里面一些常见对象的类型不支持,比如:
- Linked 系列,LinkedHashMap、LinkedHashSet 等,但是可以通过扩展 CollectionDeserializer 类修复;
- Local 类,可以通过扩展 ContextSerializerFactory 类修复;
- Byte/Short 反序列化的时候变成 Integer。
以上这些情况,你在实践时需要格外注意。
Protobuf
Protobuf 是 Google 公司内部的混合语言数据标准,是一种轻便、高效的结构化数据存储格式,可以用于结构化数据序列化,支持 Java、Python、C++、Go 等语言。Protobuf 使用的时候需要定义 IDL(Interface description language),然后使用不同语言的 IDL 编译器,生成序列化工具类,它的优点是:
- 序列化后体积相比 JSON、Hessian 小很多;
- IDL 能清晰地描述语义,所以足以帮助并保证应用程序之间的类型不会丢失,无需类似 XML 解析器;
- 序列化反序列化速度很快,不需要通过反射获取类型;
- 消息格式升级和兼容性不错,可以做到向后兼容。
使用代码示例如下:
/**
*
* // IDl 文件格式
* synax = "proto3";
* option java_package = "com.test";
* option java_outer_classname = "StudentProtobuf";
*
* message StudentMsg {
* //序号
* int32 no = 1;
* //姓名
* string name = 2;
* }
*
*/
StudentProtobuf.StudentMsg.Builder builder = StudentProtobuf.StudentMsg.newBuilder();
builder.setNo(103);
builder.setName("protobuf");
//把student对象转化为byte数组
StudentProtobuf.StudentMsg msg = builder.build();
byte[] data = msg.toByteArray();
//把刚才序列化出来的byte数组转化为student对象
StudentProtobuf.StudentMsg deStudent = StudentProtobuf.StudentMsg.parseFrom(data);
System.out.println(deStudent);
Protobuf 非常高效,但是对于具有反射和动态能力的语言来说,这样用起来很费劲,这一点就不如 Hessian,比如用 Java 的话,这个预编译过程不是必须的,可以考虑使用 Protostuff。
Protostuff 不需要依赖 IDL 文件,可以直接对 Java 领域对象进行反 / 序列化操作,在效率上跟 Protobuf 差不多,生成的二进制格式和 Protobuf 是完全相同的,可以说是一个 Java 版本的 Protobuf 序列化框架。但在使用过程中,我遇到过一些不支持的情况,也同步给你:
- 不支持 null;
- ProtoStuff 不支持单纯的 Map、List 集合对象,需要包在对象里面。
RPC 框架中如何选择序列化?
我刚刚简单地介绍了几种最常见的序列化协议,其实远不止这几种,还有 Message pack、kryo 等。那么面对这么多的序列化协议,在 RPC 框架中我们该如何选择呢?
首先你可能想到的是性能和效率,不错,这的确是一个非常值得参考的因素。我刚才讲过,序列化与反序列化过程是 RPC 调用的一个必须过程,那么序列化与反序列化的性能和效率势必将直接关系到 RPC 框架整体的性能和效率。
那除了这点,你还想到了什么?
对,还有空间开销,也就是序列化之后的二进制数据的体积大小。序列化后的字节数据体积越小,网络传输的数据量就越小,传输数据的速度也就越快,由于 RPC 是远程调用,那么网络传输的速度将直接关系到请求响应的耗时。
现在请你再想想,还有什么因素可以影响到我们的选择?
没错,就是序列化协议的通用性和兼容性。在 RPC 的运营中,序列化问题恐怕是我碰到的和解答过的最多的问题了,经常有业务会向我反馈这个问题,比如某个类型为集合类的入参服务调用者不能解析了,服务提供方将入参类加一个属性之后服务调用方不能正常调用,升级了 RPC 版本后发起调用时报序列化异常了…
在序列化的选择上,与序列化协议的效率、性能、序列化协议后的体积相比,其通用性和兼容性的优先级会更高,因为他是会直接关系到服务调用的稳定性和可用率的,对于服务的性能来说,服务的可靠性显然更加重要。我们更加看重这种序列化协议在版本升级后的兼容性是否很好,是否支持更多的对象类型,是否是跨平台、跨语言的,是否有很多人已经用过并且踩过了很多的坑,其次我们才会去考虑性能、效率和空间开销。
还有一点我要特别强调。除了序列化协议的通用性和兼容性,序列化协议的安全性也是非常重要的一个参考因素,甚至应该放在第一位去考虑。以 JDK 原生序列化为例,它就存在漏洞。如果序列化存在安全漏洞,那么线上的服务就很可能被入侵。

综合上面几个参考因素,现在我们再来总结一下这几个序列化协议。
我们首选的还是 Hessian 与 Protobuf,因为他们在性能、时间开销、空间开销、通用性、兼容性和安全性上,都满足了我们的要求。其中 Hessian 在使用上更加方便,在对象的兼容性上更好;Protobuf 则更加高效,通用性上更有优势。
RPC 框架在使用时要注意哪些问题?
了解了在 RPC 框架中如何选择序列化,那么我们在使用过程中需要注意哪些序列化上的问题呢?
我刚才讲过,在 RPC 的运营中,我遇到的最多的问题就是序列化问题了,除了早期 RPC 框架本身出现的问题以外,大多数问题都是使用方使用不正确导致的,接下来我们就盘点下这些高频出现的人为问题。
- 对象构造得过于复杂:属性很多,并且存在多层的嵌套,比如 A 对象关联 B 对象,B 对象又聚合 C 对象,C 对象又关联聚合很多其他对象,对象依赖关系过于复杂。序列化框架在序列化与反序列化对象时,对象越复杂就越浪费性能,消耗 CPU,这会严重影响 RPC 框架整体的性能;另外,对象越复杂,在序列化与反序列化的过程中,出现问题的概率就越高。
- 对象过于庞大:我经常遇到业务过来咨询,为啥他们的 RPC 请求经常超时,排查后发现他们的入参对象非常得大,比如为一个大 List 或者大 Map,序列化之后字节长度达到了上兆字节。这种情况同样会严重地浪费了性能、CPU,并且序列化一个如此大的对象是很耗费时间的,这肯定会直接影响到请求的耗时。
- 使用序列化框架不支持的类作为入参类:比如 Hessian 框架,他天然是不支持 LinkedHashMap、LinkedHashSet 等,而且大多数情况下最好不要使用第三方集合类,如 Guava 中的集合类,很多开源的序列化框架都是优先支持编程语言原生的对象。因此如果入参是集合类,应尽量选用原生的、最为常用的集合类,如 HashMap、ArrayList。
- 对象有复杂的继承关系:大多数序列化框架在序列化对象时都会将对象的属性一一进行序列化,当有继承关系时,会不停地寻找父类,遍历属性。就像问题 1 一样,对象关系越复杂,就越浪费性能,同时又很容易出现序列化上的问题。
在 RPC 框架的使用过程中,我们要尽量构建简单的对象作为入参和返回值对象,避免上述问题。
04 | 网络通信:RPC框架在网络通信上更倾向于哪种网络IO模型? #

在上面讲解了 RPC 框架中的序列化,我们知道由于网络传输的数据都是二进制数据,所以我们要传递对象,就必须将对象进行序列化,而 RPC 框架在序列化的选择上,我们更关注序列化协议的安全性、通用性、兼容性,其次才关注序列化协议的性能、效率、空间开销。承接上一讲,这一讲,我要专门讲解下 RPC 框架中的网络通信,这也是我们在开篇词中就强调过的重要内容。
RPC 是解决进程间通信的一种方式。一次 RPC 调用,本质就是服务消费者与服务提供者间的一次网络信息交换的过程。服务调用者通过网络 IO 发送一条请求消息,服务提供者接收并解析,处理完相关的业务逻辑之后,再发送一条响应消息给服务调用者,服务调用者接收并解析响应消息,处理完相关的响应逻辑,一次 RPC 调用便结束了。可以说,网络通信是整个 RPC 调用流程的基础。
常见的网络 IO 模型
那说到网络通信,就不得不提一下网络 IO 模型。为什么要讲网络 IO 模型呢?因为所谓的两台 PC 机之间的网络通信,实际上就是两台 PC 机对网络 IO 的操作。
常见的网络 IO 模型分为四种:同步阻塞 IO(BIO)、同步非阻塞 IO(NIO)、IO 多路复用和异步非阻塞 IO(AIO)。在这四种 IO 模型中,只有 AIO 为异步 IO,其他都是同步 IO。
其中,最常用的就是同步阻塞 IO 和 IO 多路复用,这一点通过了解它们的机制,你会 get 到。至于其他两种 IO 模型,因为不常用,则不作为本讲的重点,有兴趣的话我们可以在留言区中讨论。
阻塞 IO(blocking IO)
同步阻塞 IO 是最简单、最常见的 IO 模型,在 Linux 中,默认情况下所有的 socket 都是 blocking 的,先看下操作流程。
首先,应用进程发起 IO 系统调用后,应用进程被阻塞,转到内核空间处理。之后,内核开始等待数据,等待到数据之后,再将内核中的数据拷贝到用户内存中,整个 IO 处理完毕后返回进程。最后应用的进程解除阻塞状态,运行业务逻辑。
这里我们可以看到,系统内核处理 IO 操作分为两个阶段——等待数据和拷贝数据。而在这两个阶段中,应用进程中 IO 操作的线程会一直都处于阻塞状态,如果是基于 Java 多线程开发,那么每一个 IO 操作都要占用线程,直至 IO 操作结束。
这个流程就好比我们去餐厅吃饭,我们到达餐厅,向服务员点餐,之后要一直在餐厅等待后厨将菜做好,然后服务员会将菜端给我们,我们才能享用。
IO 多路复用(IO multiplexing)
多路复用 IO 是在高并发场景中使用最为广泛的一种 IO 模型,如 Java 的 NIO、Redis、Nginx 的底层实现就是此类 IO 模型的应用,经典的 Reactor 模式也是基于此类 IO 模型。
那么什么是 IO 多路复用呢?通过字面上的理解,多路就是指多个通道,也就是多个网络连接的 IO,而复用就是指多个通道复用在一个复用器上。
多个网络连接的 IO 可以注册到一个复用器(select)上,当用户进程调用了 select,那么整个进程会被阻塞。同时,内核会“监视”所有 select 负责的 socket,当任何一个 socket 中的数据准备好了,select 就会返回。这个时候用户进程再调用 read 操作,将数据从内核中拷贝到用户进程。
这里我们可以看到,当用户进程发起了 select 调用,进程会被阻塞,当发现该 select 负责的 socket 有准备好的数据时才返回,之后才发起一次 read,整个流程要比阻塞 IO 要复杂,似乎也更浪费性能。但它最大的优势在于,用户可以在一个线程内同时处理多个 socket 的 IO 请求。用户可以注册多个 socket,然后不断地调用 select 读取被激活的 socket,即可达到在同一个线程内同时处理多个 IO 请求的目的。而在同步阻塞模型中,必须通过多线程的方式才能达到这个目的。
同样好比我们去餐厅吃饭,这次我们是几个人一起去的,我们专门留了一个人在餐厅排号等位,其他人就去逛街了,等排号的朋友通知我们可以吃饭了,我们就直接去享用了。
为什么说阻塞 IO 和 IO 多路复用最为常用?
了解完二者的机制,我们就可以回到起初的问题了——我为什么说阻塞 IO 和 IO 多路复用最为常用。对比这四种网络 IO 模型:阻塞 IO、非阻塞 IO、IO 多路复用、异步 IO。实际在网络 IO 的应用上,需要的是系统内核的支持以及编程语言的支持。
在系统内核的支持上,现在大多数系统内核都会支持阻塞 IO、非阻塞 IO 和 IO 多路复用,但像信号驱动 IO、异步 IO,只有高版本的 Linux 系统内核才会支持。
在编程语言上,无论 C++ 还是 Java,在高性能的网络编程框架的编写上,大多数都是基于 Reactor 模式,其中最为典型的便是 Java 的 Netty 框架,而 Reactor 模式是基于 IO 多路复用的。当然,在非高并发场景下,同步阻塞 IO 是最为常见的。
综合来讲,在这四种常用的 IO 模型中,应用最多的、系统内核与编程语言支持最为完善的,便是阻塞 IO 和 IO 多路复用。这两种 IO 模型,已经可以满足绝大多数网络 IO 的应用场景
Reactor模式
传统I/O服务模型
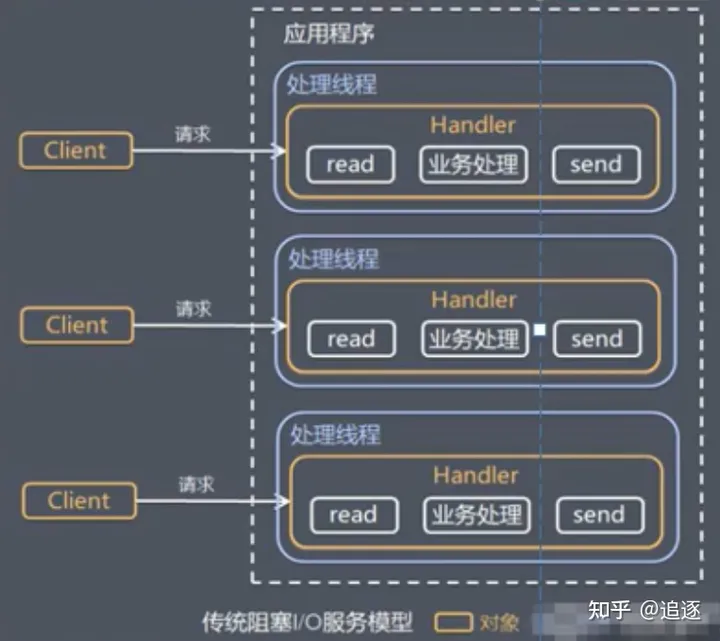
模型特点:
- 采用阻塞I/O模式获取输入数据
- 每个连接都需要独立的线程完成数据的输入,业务处理,数据返回
问题分析:
- 当并发数很大,就会创建大量线程,占用大量的系统资源
- 连接创建后,如果当前线程暂时没有数据可读,该线程会阻塞在read操作,造成线程资源浪费
Reactor模式
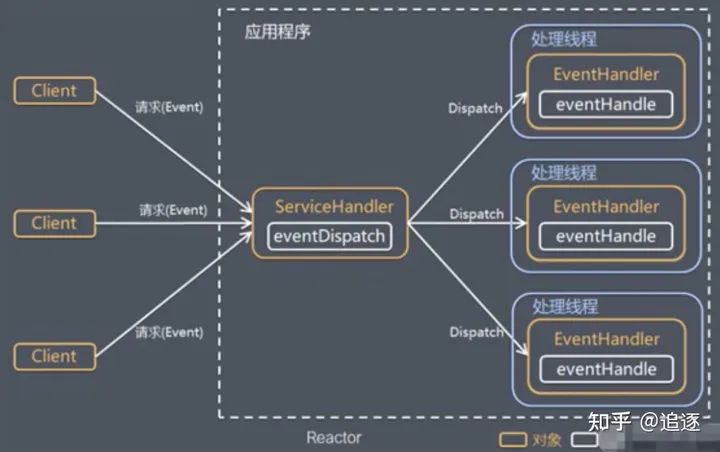
Reactor模式称为反应器模式或应答者模式,是基于事件驱动的设计模式,拥有一个或多个并发输入源,有一个服务处理器和多个请求处理器,服务处理器会同步的将输入的请求事件以多路复用的方式分发给相应的请求处理器。
Reactor设计模式是一种为处理并发服务请求,并将请求提交到一个或多个服务处理程序的事件设计模式。当客户端请求抵达后,服务处理程序使用多路分配策略,由一个非阻塞的线程来接收所有请求,然后将请求派发到相关的工作线程并进行处理的过程。
在事件驱动的应用中,将一个或多个客户端的请求分离和调度给应用程序,同步有序地接收并处理多个服务请求。对于高并发系统经常会使用到Reactor模式,用来替代常用的多线程处理方式以节省系统资源并提高系统的吞吐量。
单Reactor单线程
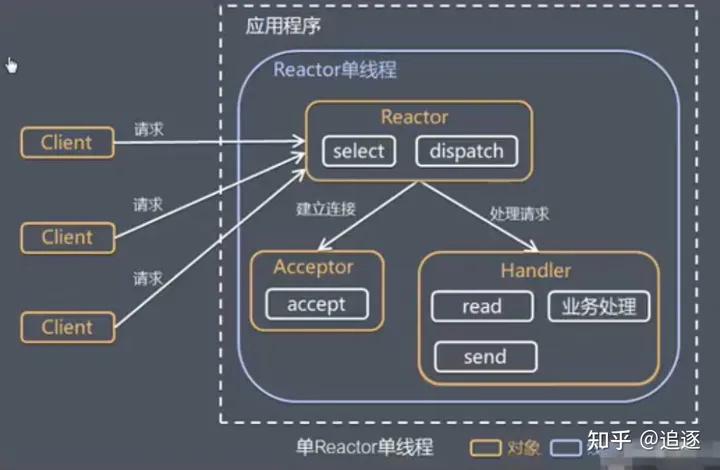
优点:模型简单,没有多线程、进程通信和竞争的问题,全部都在一个线程中完成。
缺点:
-
性能问题,只有一个线程,无法发挥多核CPU的性能,Handler在处理某个连接业务时,整个进程无法处理其他连接事件,很容易导致性能瓶颈。
-
可靠性问题,线程意外终止或进入死循环,会导致整个系统通信模块不可用,不能接收和处理外部消息,造成节点故障。
单Reactor多线程
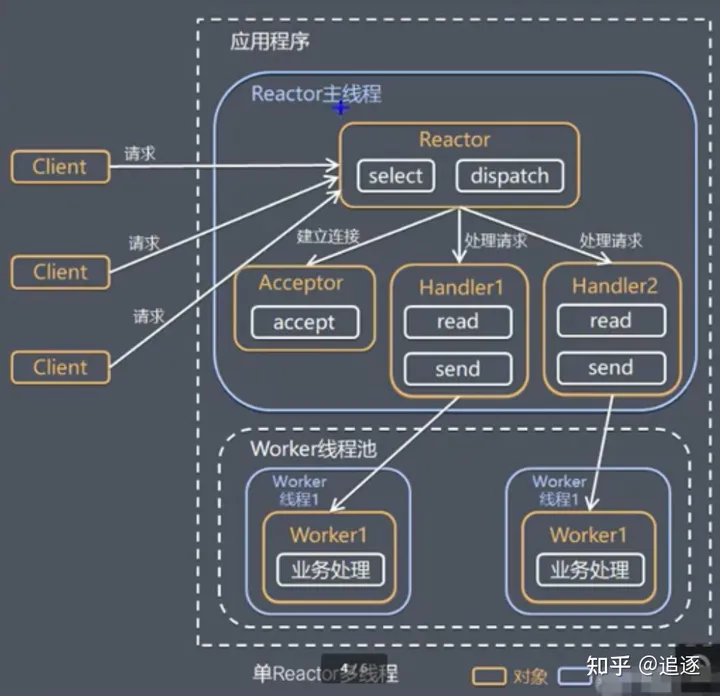
工作流程
- Reactor对象通过select监听客户端请求事件,收到事件后,通过dispatch进行分发。
- 如果建立连接请求,则Acceptor通过accept处理连接请求,然后创建一个Handler对象处理完成连接后的各种事件。
- 如果不是连接请求,则由reactor分发调用连接对应的handler来处理。
- handler只负责相应事件,不做具体的业务处理,通过read读取数据后,会分发给后面的worker线程池的某个线程处理业务。
- worker线程池会分配独立线程完成真正的业务,并将结果返回给handler。
- handler收到响应后,通过send分发将结果返回给client。
- 优点:可以充分利用多核cpu的处理能力
- 缺点:多线程数据共享和访问比较复杂,rector处理所有的事件的监听和响应,在单线程运行,在高并发应用场景下,容易出现性能瓶颈。
主从Reactor多线程
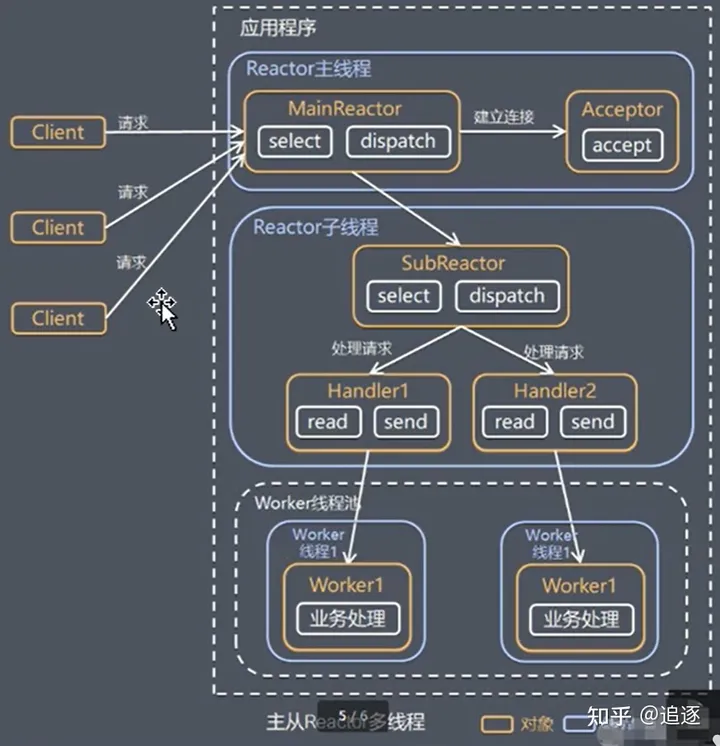
工作流程
- Reactor主线程MainReactor对象通过select监听连接事件,收到事件后,通过Acceptor处理连接事件。
- 当Acceptor处理连接事件后,MainReactor将连接分配给SubAcceptor。
- SubAcceptor将连接加入到连接队列进行监听,并创建handler进行各种事件处理。
- 当有新事件发生时,SubAcceptor就会调用对应的handler进行各种事件处理。
- handler通过read读取数据,分发给后面的work线程处理。
- work线程池分配独立的work线程进行业务处理,并返回结果。
- handler收到响应的结果后,再通过send返回给client。
注意:Reactor主线程可以对应多个Reactor子线程,即SubAcceptor。
Reactor模式总结
3种模式用生活案例来理解
- 单reactor单线程,前台接待员、服务员时同一个人,全程为顾客服务。
- 单reactor多线程,1个前台接待,多个服务员,接待员只负责接待。
- 主从reactor多线程,多个前台接待,多个服务员。
Reactor模式的优点
- 响应块,不必为单个同步时间所阻塞,虽然Reactor本身依然时同步的。
- 可以最大程度的避免复杂的多线程及同步问题,并且避免多线程/进程的切换开销。
- 扩展性好,可以方便的通过增加Reactor实例个数来充分利用CPU资源。
- 复用性好,Reactor模式本身与具体事件处理逻辑无关,具有很高的复用性。
RPC 框架在网络通信上倾向选择哪种网络 IO 模型?
讲完了这两种最常用的网络 IO 模型,我们可以看看它们都适合什么样的场景。
IO 多路复用更适合高并发的场景,可以用较少的进程(线程)处理较多的 socket 的 IO 请求,但使用难度比较高。当然高级的编程语言支持得还是比较好的,比如 Java 语言有很多的开源框架对 Java 原生 API 做了封装,如 Netty 框架,使用非常简便;而 GO 语言,语言本身对 IO 多路复用的封装就已经很简洁了。
而阻塞 IO 与 IO 多路复用相比,阻塞 IO 每处理一个 socket 的 IO 请求都会阻塞进程(线程),但使用难度较低。在并发量较低、业务逻辑只需要同步进行 IO 操作的场景下,阻塞 IO 已经满足了需求,并且不需要发起 select 调用,开销上还要比 IO 多路复用低。
RPC 调用在大多数的情况下,是一个高并发调用的场景,考虑到系统内核的支持、编程语言的支持以及 IO 模型本身的特点,在 RPC 框架的实现中,在网络通信的处理上,我们会选择 IO 多路复用的方式。开发语言的网络通信框架的选型上,我们最优的选择是基于 Reactor 模式实现的框架,如 Java 语言,首选的框架便是 Netty 框架(Java 还有很多其他 NIO 框架,但目前 Netty 应用得最为广泛),并且在 Linux 环境下,也要开启 epoll 来提升系统性能(Windows 环境下是无法开启 epoll 的,因为系统内核不支持)。
了解完以上内容,我们可以继续看这样一个关键问题——零拷贝。在我们应用的过程中,他是非常重要的。
什么是零拷贝?
刚才讲阻塞 IO 的时候我讲到,系统内核处理 IO 操作分为两个阶段——等待数据和拷贝数据。等待数据,就是系统内核在等待网卡接收到数据后,把数据写到内核中;而拷贝数据,就是系统内核在获取到数据后,将数据拷贝到用户进程的空间中。以下是具体流程:
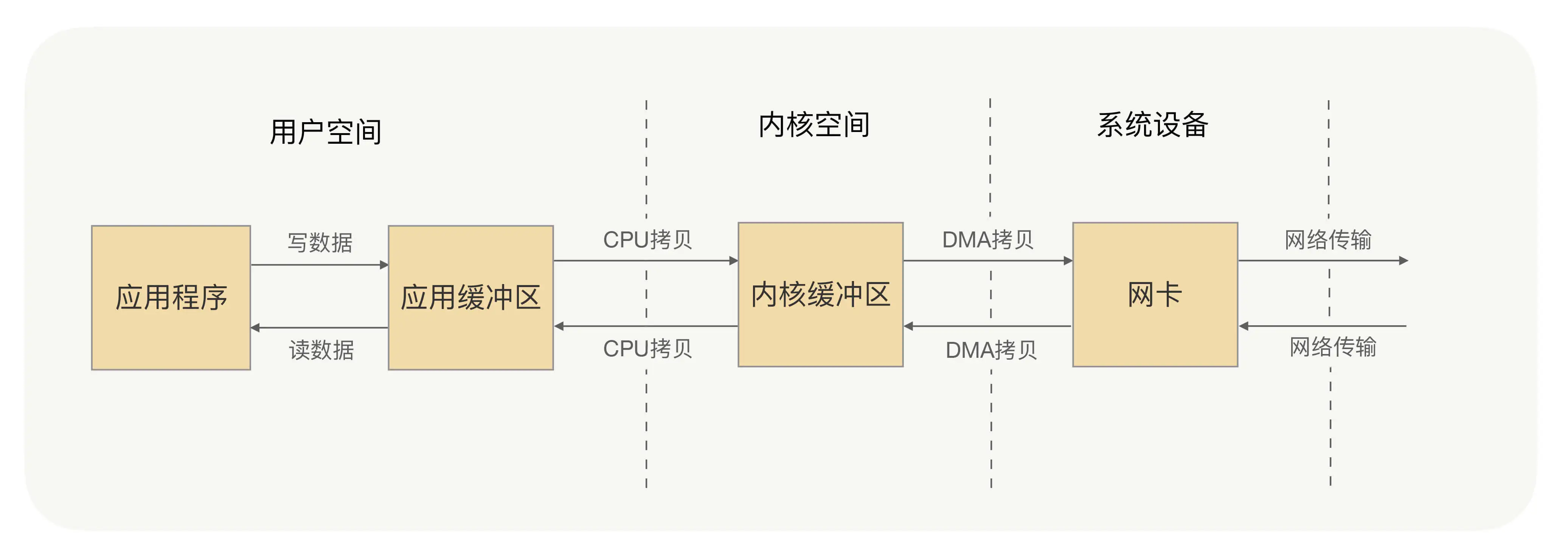
应用进程的每一次写操作,都会把数据写到用户空间的缓冲区中,再由 CPU 将数据拷贝到系统内核的缓冲区中,之后再由 DMA(Direct Memory Access,直接内存访问,一种硬件机制,允许外部设备(如网卡、硬盘驱动器等)直接与系统内存进行数据传输,而无需通过CPU进行中转)将这份数据拷贝到网卡中,最后由网卡发送出去。这里我们可以看到,一次写操作数据要拷贝两次才能通过网卡发送出去,而用户进程的读操作则是将整个流程反过来,数据同样会拷贝两次才能让应用程序读取到数据。
应用进程的一次完整的读写操作,都需要在用户空间与内核空间中来回拷贝,并且每一次拷贝,都需要 CPU 进行一次上下文切换(由用户进程切换到系统内核,或由系统内核切换到用户进程),这样是不是很浪费 CPU 和性能呢?那有没有什么方式,可以减少进程间的数据拷贝,提高数据传输的效率呢?
这时我们就需要零拷贝(Zero-copy)技术。
所谓的零拷贝,就是取消用户空间与内核空间之间的数据拷贝操作,应用进程每一次的读写操作,都可以通过一种方式,让应用进程向用户空间写入或者读取数据,就如同直接向内核空间写入或者读取数据一样,再通过 DMA 将内核中的数据拷贝到网卡,或将网卡中的数据 copy 到内核。
那怎么做到零拷贝?你想一下是不是用户空间与内核空间都将数据写到一个地方,就不需要拷贝了?此时你有没有想到虚拟内存?
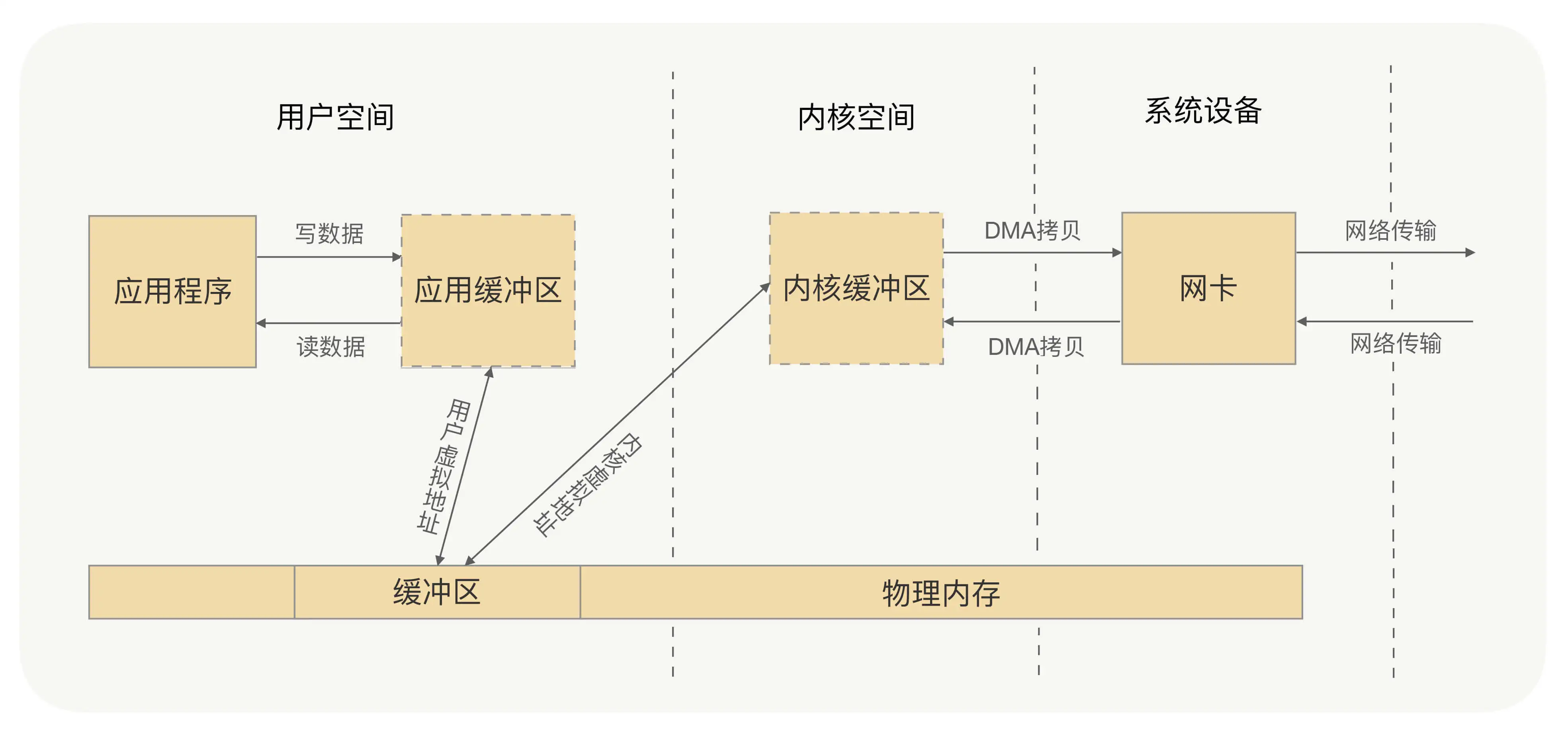
零拷贝有两种解决方式,分别是 mmap+write 方式和 sendfile 方式,mmap+write 方式的核心原理就是通过虚拟内存来解决的。
- mmap+write 方式:
- 原理:mmap(Memory Mapped Files)通过内存映射文件的方式,将文件直接映射到用户空间的内存地址,这样用户空间的应用程序可以直接操作这段内存,而不需要将数据拷贝到用户空间。当需要进行写操作时,应用程序直接写入这段映射的内存区域,操作系统负责将这部分内存区域的内容写入到对应的文件中。
- 优点:减少了用户空间和内核空间之间的数据拷贝,降低了CPU的使用率。
- 代码示例(伪代码):
// 打开文件
int fd = open("file.txt", O_RDONLY);
// 将文件映射到内存
void *map = mmap(NULL, filesize, PROT_READ, MAP_PRIVATE, fd, 0);
// 进行写操作,这里写入的是内存映射区域,而非直接写入文件
write(sockfd, map, filesize);
// 解除内存映射
munmap(map, filesize);
- sendfile 方式:
- 原理:sendfile 是 Linux 内核提供的一个系统调用,用于在两个文件描述符之间直接传输数据,避免了数据在用户空间和内核空间之间的拷贝。在传输数据时,sendfile 直接将数据从磁盘文件(通过文件描述符)发送到网络套接字(通过另一个文件描述符)。
- 优点:不仅减少了数据拷贝,还避免了上下文切换,因为整个操作在内核空间完成。
- 代码示例(伪代码):
// 打开文件
int fd = open("file.txt", O_RDONLY);
// 获取文件大小
off_t offset = lseek(fd, 0, SEEK_END);
// sendfile 系统调用
sendfile(sockfd, fd, &offset, filesize);
9.2 I/O 多路复用:select/poll/epoll
05 | 动态代理:面向接口编程,屏蔽RPC处理流程 #
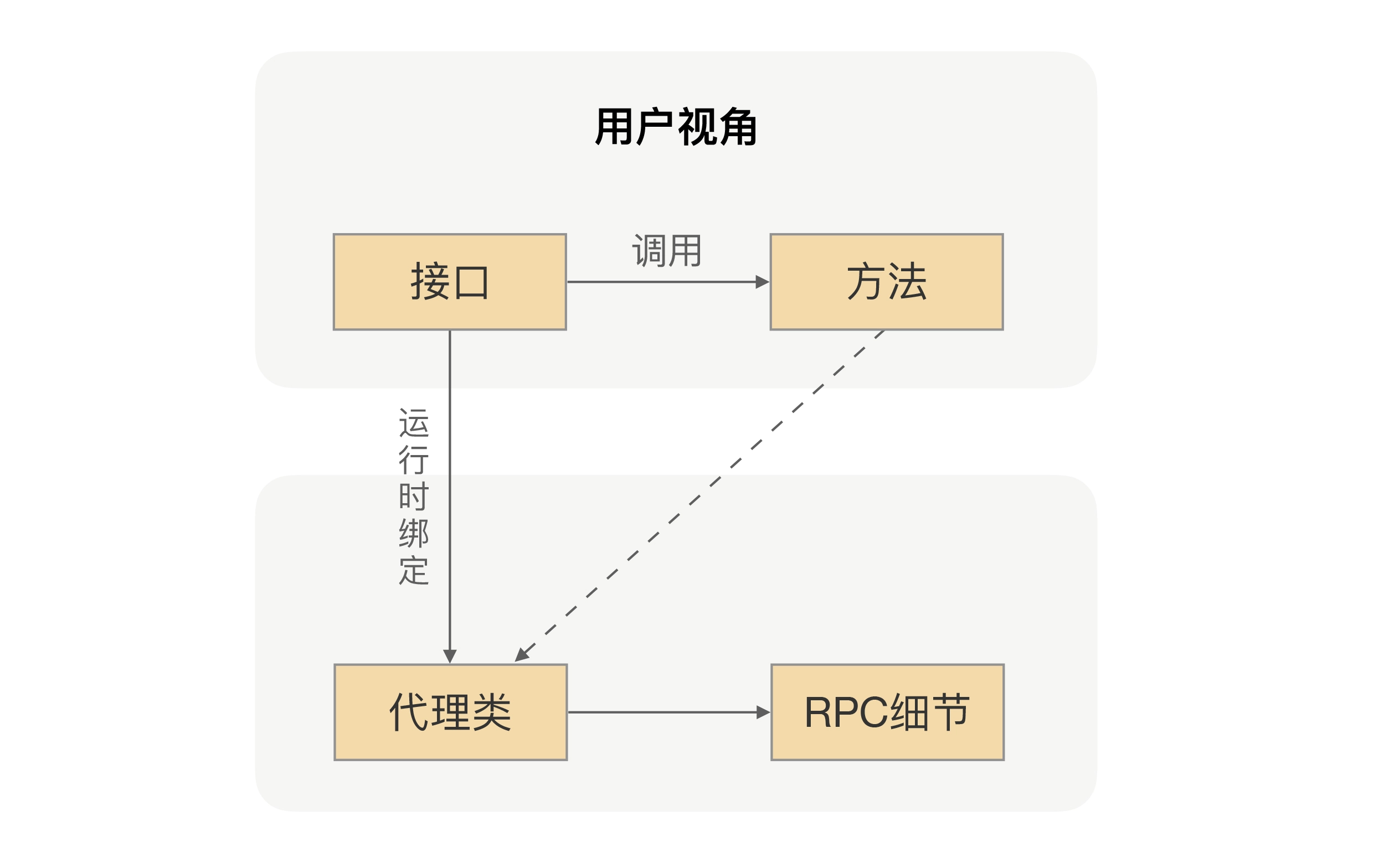
在项目中,当我们要使用 RPC 的时候,我们一般的做法是先找服务提供方要接口,通过 Maven 或者其他的工具把接口依赖到我们项目中。我们在编写业务逻辑的时候,如果要调用提供方的接口,我们就只需要通过依赖注入的方式把接口注入到项目中就行了,然后在代码里面直接调用接口的方法 。
我们都知道,接口里并不会包含真实的业务逻辑,业务逻辑都在服务提供方应用里,但我们通过调用接口方法,确实拿到了想要的结果,是不是感觉有点神奇呢?想一下,在 RPC 里面,我们是怎么完成这个魔术的。
这里面用到的核心技术就是前面说的动态代理。RPC 会自动给接口生成一个代理类,当我们在项目中注入接口的时候,运行过程中实际绑定的是这个接口生成的代理类。这样在接口方法被调用的时候,它实际上是被生成代理类拦截到了,这样我们就可以在生成的代理类里面,加入远程调用逻辑。
通过这种“偷梁换柱”的手法,就可以帮用户屏蔽远程调用的细节,实现像调用本地一样地调用远程的体验,整体流程如下图所示:
实现原理
动态代理在 RPC 里面的作用,就像是个魔术。现在我不妨给你揭秘一下,我们一起看看这是怎么实现的。之后,学以致用自然就不难了。
我们以 Java 为例,看一个具体例子,代码如下所示:
/**
* 要代理的接口
*/
public interface Hello {
String say();
}
/**
* 真实调用对象
*/
public class RealHello {
public String invoke(){
return "i'm proxy";
}
}
/**
* JDK代理类生成
*/
public class JDKProxy implements InvocationHandler {
private Object target;
JDKProxy(Object target) {
this.target = target;
}
@Override
public Object invoke(Object proxy, Method method, Object[] paramValues) {
return ((RealHello)target).invoke();
}
}
/**
* 测试例子
*/
public class TestProxy {
public static void main(String[] args){
// 构建代理器
JDKProxy proxy = new JDKProxy(new RealHello());
ClassLoader classLoader = ClassLoaderUtils.getCurrentClassLoader();
// 把生成的代理类保存到文件
System.setProperty("sun.misc.ProxyGenerator.saveGeneratedFiles","true");
// 生成代理类
Hello test = (Hello) Proxy.newProxyInstance(classLoader, new Class[]{Hello.class}, proxy);
// 方法调用
System.out.println(test.say());
}
}
这段代码想表达的意思就是:给 Hello 接口生成一个动态代理类,并调用接口 say() 方法,但真实返回的值居然是来自 RealHello 里面的 invoke() 方法返回值。你看,短短 50 行的代码,就完成了这个功能,是不是还挺有意思的?
那既然重点是代理类的生成,那我们就去看下 Proxy.newProxyInstance 里面究竟发生了什么?
一起看下下面的流程图,具体代码细节你可以对照着 JDK 的源码看(上文中有类和方法,可以直接定位),我是按照 1.7.X 版本梳理的。
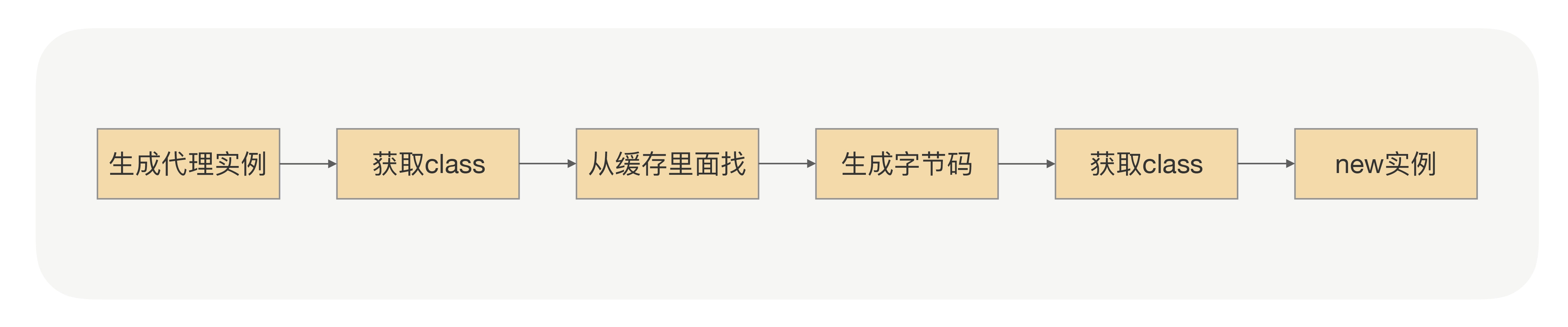
在生成字节码的那个地方,也就是 ProxyGenerator.generateProxyClass() 方法里面,通过代码我们可以看到,里面是用参数 saveGeneratedFiles 来控制是否把生成的字节码保存到本地磁盘。同时为了更直观地了解代理的本质,我们需要把参数 saveGeneratedFiles 设置成 true,但这个参数的值是由 key 为“sun.misc.ProxyGenerator.saveGeneratedFiles”的 Property 来控制的,动态生成的类会保存在工程根目录下的 com/sun/proxy 目录里面。现在我们找到刚才生成的 $Proxy0.class,通过反编译工具打开 class 文件,你会看到这样的代码:
package com.sun.proxy;
import com.proxy.Hello;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
import java.lang.reflect.UndeclaredThrowableException;
public final class $Proxy0 extends Proxy implements Hello {
private static Method m3;
private static Method m1;
private static Method m0;
private static Method m2;
public $Proxy0(InvocationHandler paramInvocationHandler) {
super(paramInvocationHandler);
}
public final String say() {
try {
return (String)this.h.invoke(this, m3, null);
} catch (Error|RuntimeException error) {
throw null;
} catch (Throwable throwable) {
throw new UndeclaredThrowableException(throwable);
}
}
public final boolean equals(Object paramObject) {
try {
return ((Boolean)this.h.invoke(this, m1, new Object[] { paramObject })).booleanValue();
} catch (Error|RuntimeException error) {
throw null;
} catch (Throwable throwable) {
throw new UndeclaredThrowableException(throwable);
}
}
public final int hashCode() {
try {
return ((Integer)this.h.invoke(this, m0, null)).intValue();
} catch (Error|RuntimeException error) {
throw null;
} catch (Throwable throwable) {
throw new UndeclaredThrowableException(throwable);
}
}
public final String toString() {
try {
return (String)this.h.invoke(this, m2, null);
} catch (Error|RuntimeException error) {
throw null;
} catch (Throwable throwable) {
throw new UndeclaredThrowableException(throwable);
}
}
static {
try {
m3 = Class.forName("com.proxy.Hello").getMethod("say", new Class[0]);
m1 = Class.forName("java.lang.Object").getMethod("equals", new Class[] { Class.forName("java.lang.Object") });
m0 = Class.forName("java.lang.Object").getMethod("hashCode", new Class[0]);
m2 = Class.forName("java.lang.Object").getMethod("toString", new Class[0]);
return;
} catch (NoSuchMethodException noSuchMethodException) {
throw new NoSuchMethodError(noSuchMethodException.getMessage());
} catch (ClassNotFoundException classNotFoundException) {
throw new NoClassDefFoundError(classNotFoundException.getMessage());
}
}
}
我们可以看到 $Proxy0 类里面有一个跟 Hello 一样签名的 say() 方法,其中 this.h 绑定的是刚才传入的 JDKProxy 对象,所以当我们调用 Hello.say() 的时候,其实它是被转发到了 JDKProxy.invoke()。到这儿,整个魔术过程就透明了。
实现过程
其实在 Java 领域,除了 JDK 默认的 InvocationHandler 能完成代理功能,我们还有很多其他的第三方框架也可以,比如像 Javassist、Byte Buddy 这样的框架。
单纯从代理功能上来看,JDK 默认的代理功能是有一定的局限性的,它要求被代理的类只能是接口。原因是因为生成的代理类会继承 Proxy 类,但 Java 是不支持多重继承的。
这个限制在 RPC 应用场景里面还是挺要紧的,因为对于服务调用方来说,在使用 RPC 的时候本来就是面向接口来编程的,这个我们刚才在前面已经讨论过了。使用 JDK 默认的代理功能,最大的问题就是性能问题。它生成后的代理类是使用反射来完成方法调用的,而这种方式相对直接用编码调用来说,性能会降低,但好在 JDK8 及以上版本对反射调用的性能有很大的提升,所以还是可以期待一下的。
相对 JDK 自带的代理功能,Javassist 的定位是能够操纵底层字节码,所以使用起来并不简单,要生成动态代理类恐怕是有点复杂了。但好的方面是,通过 Javassist 生成字节码,不需要通过反射完成方法调用,所以性能肯定是更胜一筹的。在使用中,我们要注意一个问题,通过 Javassist 生成一个代理类后,此 CtClass 对象会被冻结起来,不允许再修改;否则,再次生成时会报错。
Byte Buddy 则属于后起之秀,在很多优秀的项目中,像 Spring、Jackson 都用到了 Byte Buddy 来完成底层代理。相比 Javassist,Byte Buddy 提供了更容易操作的 API,编写的代码可读性更高。更重要的是,生成的代理类执行速度比 Javassist 更快。
虽然以上这三种框架使用的方式相差很大,但核心原理却是差不多的,区别就只是通过什么方式生成的代理类以及在生成的代理类里面是怎么完成的方法调用。同时呢,也正是因为这些细小的差异,才导致了不同的代理框架在性能方面的表现不同。因此,我们在设计 RPC 框架的时候,还是需要进行一些比较的,具体你可以综合它们的优劣以及你的场景需求进行选择。
思考题:如果没有动态代理帮我们完成方法调用拦截,用户该怎么完成 RPC 调用?
这个问题我们可以参考下 gRPC 框架。gRPC 框架中就没有使用动态代理,它是通过代码生成的方式生成 Service 存根,当然这个 Service 存根起到的作用和 RPC 框架中的动态代理是一样的。
gRPC 框架用代码生成的 Service 存根来代替动态代理主要是为了实现多语言的客户端,因为有些语言是不支持动态代理的,比如 C++、go 等,但缺点也是显而易见的。如果你使用过 gRPC,你会发现这种代码生成 Service 存根的方式与动态代理相比还是很麻烦的,并不如动态代理的方式使用起来方便、透明。
06 | RPC实战:剖析gRPC源码,动手实现一个完整的RPC #
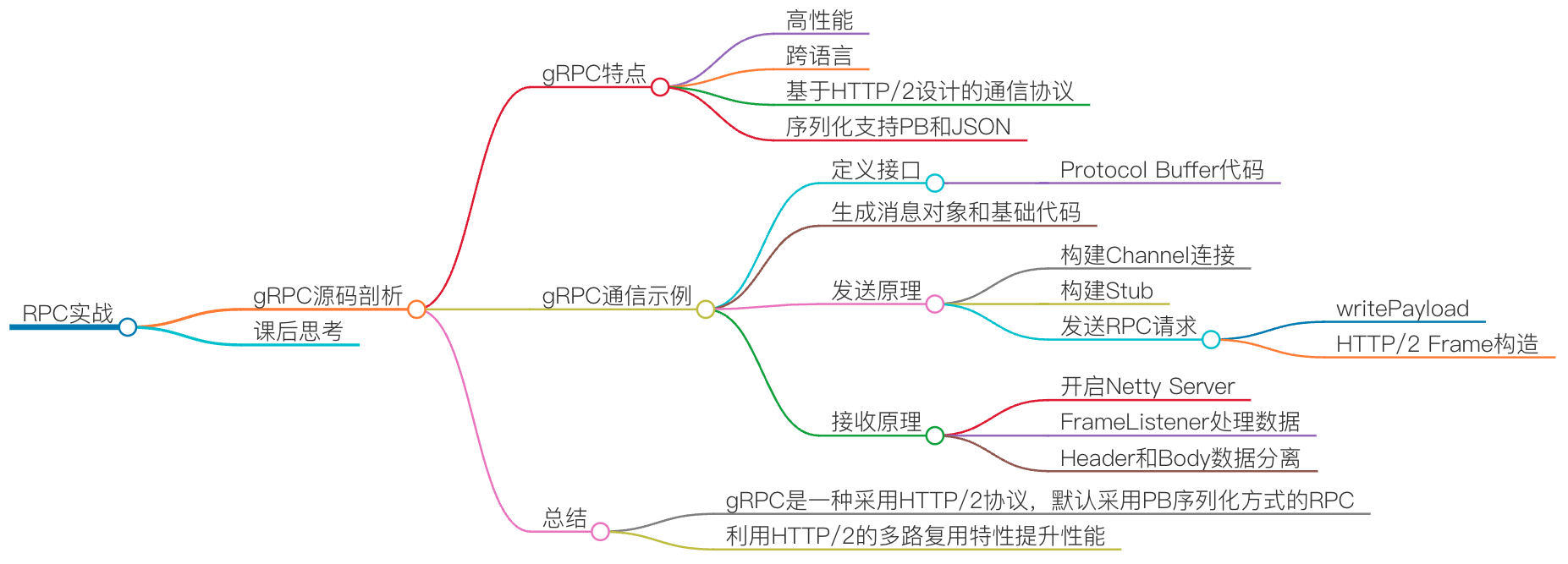
gRPC 是由 Google 开发并且开源的一款高性能、跨语言的 RPC 框架,当前支持 C、Java 和 Go 等语言,当前 Java 版本最新 Release 版为 1.27.0。gRPC 有很多特点,比如跨语言,通信协议是基于标准的 HTTP/2 设计的,序列化支持 PB(Protocol Buffer)和 JSON,整个调用示例如下图所示:
如果你想快速地了解一个全新框架的工作原理,我个人认为最快的方式就是从使用示例开始,所以现在我们就以最简单的 HelloWord 为例开始了解。
在这个例子里面,我们会定义一个 say 方法,调用方通过 gRPC 调用服务提供方,然后服务提供方会返回一个字符串给调用方。
为了保证调用方和服务提供方能够正常通信,我们需要先约定一个通信过程中的契约,也就是我们在 Java 里面说的定义一个接口,这个接口里面只会包含一个 say 方法。在 gRPC 里面定义接口是通过写 Protocol Buffer 代码,从而把接口的定义信息通过 Protocol Buffer 语义表达出来。HelloWord 的 Protocol Buffer 代码如下所示:
syntax = "proto3";
option java_multiple_files = true;
option java_package = "io.grpc.hello";
option java_outer_classname = "HelloProto";
option objc_class_prefix = "HLW";
package hello;
service HelloService{
rpc Say(HelloRequest) returns (HelloReply) {}
}
message HelloRequest {
string name = 1;
}
message HelloReply {
string message = 1;
}
有了这段代码,我们就可以为客户端和服务器端生成消息对象和 RPC 基础代码。我们可以利用 Protocol Buffer 的编译器 protoc,再配合 gRPC Java 插件(protoc-gen-grpc-java),通过命令行 protoc3 加上 plugin 和 proto 目录地址参数,我们就可以生成消息对象和 gRPC 通信所需要的基础代码。如果你的项目是 Maven 工程的话,你还可以直接选择使用 Maven 插件来生成同样的代码。
发送原理
生成完基础代码以后,我们就可以基于生成的代码写下调用端代码,具体如下:
package io.grpc.hello;
import io.grpc.ManagedChannel;
import io.grpc.ManagedChannelBuilder;
import io.grpc.StatusRuntimeException;
import java.util.concurrent.TimeUnit;
public class HelloWorldClient {
private final ManagedChannel channel;
private final HelloServiceGrpc.HelloServiceBlockingStub blockingStub;
/**
* 构建Channel连接
**/
public HelloWorldClient(String host, int port) {
this(ManagedChannelBuilder.forAddress(host, port)
.usePlaintext()
.build());
}
/**
* 构建Stub用于发请求
**/
HelloWorldClient(ManagedChannel channel) {
this.channel = channel;
blockingStub = HelloServiceGrpc.newBlockingStub(channel);
}
/**
* 调用完手动关闭
**/
public void shutdown() throws InterruptedException {
channel.shutdown().awaitTermination(5, TimeUnit.SECONDS);
}
/**
* 发送rpc请求
**/
public void say(String name) {
// 构建入参对象
HelloRequest request = HelloRequest.newBuilder().setName(name).build();
HelloReply response;
try {
// 发送请求
response = blockingStub.say(request);
} catch (StatusRuntimeException e) {
return;
}
System.out.println(response);
}
public static void main(String[] args) throws Exception {
HelloWorldClient client = new HelloWorldClient("127.0.0.1", 50051);
try {
client.say("world");
} finally {
client.shutdown();
}
}
}
调用端代码大致分成三个步骤:
- 首先用 host 和 port 生成 channel 连接;
- 然后用前面生成的 HelloService gRPC 创建 Stub 类;
- 最后我们可以用生成的这个 Stub 调用 say 方法发起真正的 RPC 调用,后续其它的 RPC 通信细节就对我们使用者透明了。
为了能看清楚里面具体发生了什么,我们需要进入到 ClientCalls.blockingUnaryCall 方法里面看下逻辑细节。但是为了避免太多的细节影响你理解整体流程,我在下面这张图中只画下了最重要的部分。
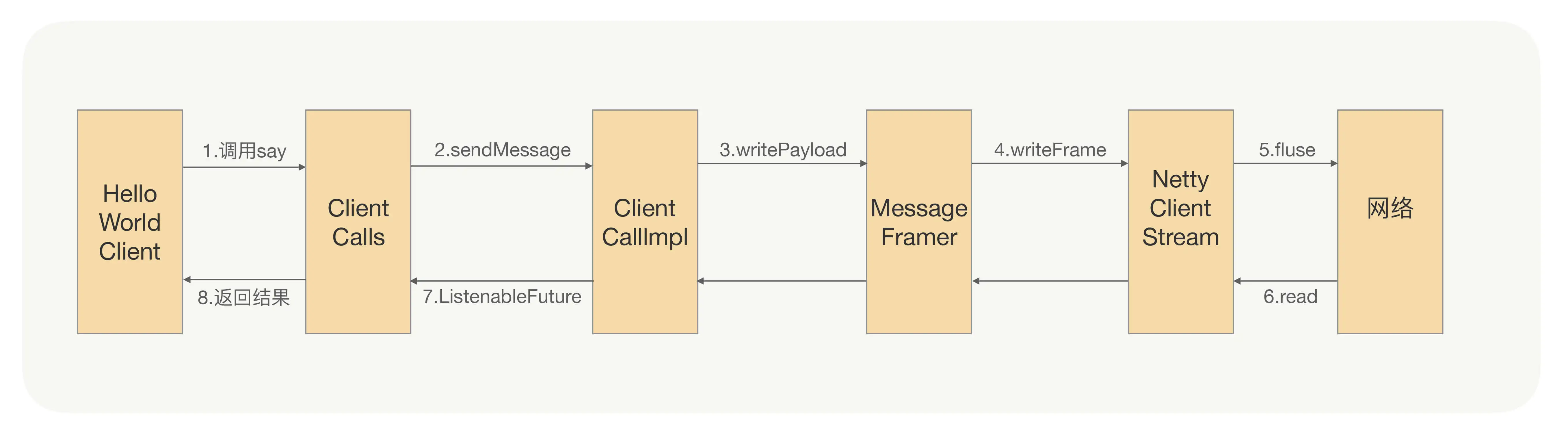
我们可以看到,在调用端代码里面,我们只需要一行(第 48 行)代码就可以发起一个 RPC 调用,而具体这个请求是怎么发送到服务提供者那端的呢?这对于我们 gRPC 使用者来说是完全透明的,我们只要关注是怎么创建出 stub 对象的就可以了。
比如入参是一个字符对象,gRPC 是怎么把这个对象传输到服务提供方的呢?只有二进制才能在网络中传输,但是目前调用端代码的入参是一个字符对象,那在 gRPC 里面我们是怎么把对象转成二进制数据的呢?
回到上面流程图的第 3 步,在 writePayload 之前,ClientCallImpl 里面有一行代码就是 method.streamRequest(message),看方法签名我们大概就知道它是用来把对象转成一个 InputStream,有了 InputStream 我们就很容易获得入参对象的二进制数据。这个方法返回值很有意思,就是为啥不直接返回我们想要的二进制数组,而是返回一个 InputStream 对象呢?你可以先停下来想下原因,我们会在最后继续讨论这个问题。(避免二次拷贝(序列化+encode))
我们接着看 streamRequest 方法的拥有者 method 是个什么对象?我们可以看到 method 是 MethodDescriptor 对象关联的一个实例,而 MethodDescriptor 是用来存放要调用 RPC 服务的接口名、方法名、服务调用的方式以及请求和响应的序列化和反序列化实现类。
大白话说就是,MethodDescriptor 是用来存储一些 RPC 调用过程中的元数据,而在 MethodDescriptor 里面 requestMarshaller 是在绑定请求的时候用来序列化方式对象的,所以当我们调用 method.streamRequest(message) 的时候,实际是调用 requestMarshaller.stream(requestMessage) 方法,而 requestMarshaller 里面会绑定一个 Parser,这个 Parser 才真正地把对象转成了 InputStream 对象。
讲完序列化在 gRPC 里面的应用后,我们再来看下在 gRPC 里面是怎么完成请求数据“断句”的,就是那个问题——二进制流经过网络传输后,怎么正确地还原请求前语义?
我们在 gRPC 文档中可以看到,gRPC 的通信协议是基于标准的 HTTP/2 设计的,而 HTTP/2 相对于常用的 HTTP/1.X 来说,它最大的特点就是多路复用、双向流,该怎么理解这个特点呢?这就好比我们生活中的单行道和双行道,HTTP/1.X 就是单行道,HTTP/2 就是双行道。
那既然在请求收到后需要进行请求“断句”,那肯定就需要在发送的时候把断句的符号加上,我们看下在 gRPC 里面是怎么加的?
因为 gRPC 是基于 HTTP/2 协议,而 HTTP/2 传输基本单位是 Frame,Frame 格式是以固定 9 字节长度的 header,后面加上不定长的 payload 组成,协议格式如下图所示:

那在 gRPC 里面就变成怎么构造一个 HTTP/2 的 Frame 了。
现在回看我们上面那个流程图的第 4 步,在 write 到 Netty 里面之前,我们看到在 MessageFramer.writePayload 方法里面会间接调用 writeKnownLengthUncompressed 方法,该方法要做的两件事情就是构造 Frame Header 和 Frame Body,然后再把构造的 Frame 发送到 NettyClientHandler,最后将 Frame 写入到 HTTP/2 Stream 中,完成请求消息的发送。
接收原理
讲完 gRPC 的请求发送原理,我们再来看下服务提供方收到请求后会怎么处理?我们还是接着前面的那个例子,先看下服务提供方代码,具体如下:
static class HelloServiceImpl extends HelloServiceGrpc.HelloServiceImplBase {
@Override
public void say(HelloRequest req, StreamObserver<HelloReply> responseObserver) {
HelloReply reply = HelloReply.newBuilder().setMessage("Hello " + req.getName()).build();
responseObserver.onNext(reply);
responseObserver.onCompleted();
}
}
上面 HelloServiceImpl 类是按照 gRPC 使用方式实现了 HelloService 接口逻辑,但是对于调用者来说并不能把它调用过来,因为我们没有把这个接口对外暴露,在 gRPC 里面我们是采用 Build 模式对底层服务进行绑定,具体代码如下:
package io.grpc.hello;
import io.grpc.Server;
import io.grpc.ServerBuilder;
import io.grpc.stub.StreamObserver;
import java.io.IOException;
public class HelloWorldServer {
private Server server;
/**
* 对外暴露服务
**/
private void start() throws IOException {
int port = 50051;
server = ServerBuilder.forPort(port)
.addService(new HelloServiceImpl())
.build()
.start();
Runtime.getRuntime().addShutdownHook(new Thread() {
@Override
public void run() {
HelloWorldServer.this.stop();
}
});
}
/**
* 关闭端口
**/
private void stop() {
if (server != null) {
server.shutdown();
}
}
/**
* 优雅关闭
**/
private void blockUntilShutdown() throws InterruptedException {
if (server != null) {
server.awaitTermination();
}
}
public static void main(String[] args) throws IOException, InterruptedException {
final HelloWorldServer server = new HelloWorldServer();
server.start();
server.blockUntilShutdown();
}
}
服务对外暴露的目的是让过来的请求在被还原成信息后,能找到对应接口的实现。在这之前,我们需要先保证能正常接收请求,通俗地讲就是要先开启一个 TCP 端口,让调用方可以建立连接,并把二进制数据发送到这个连接通道里面,这里依然只展示最重要的部分。
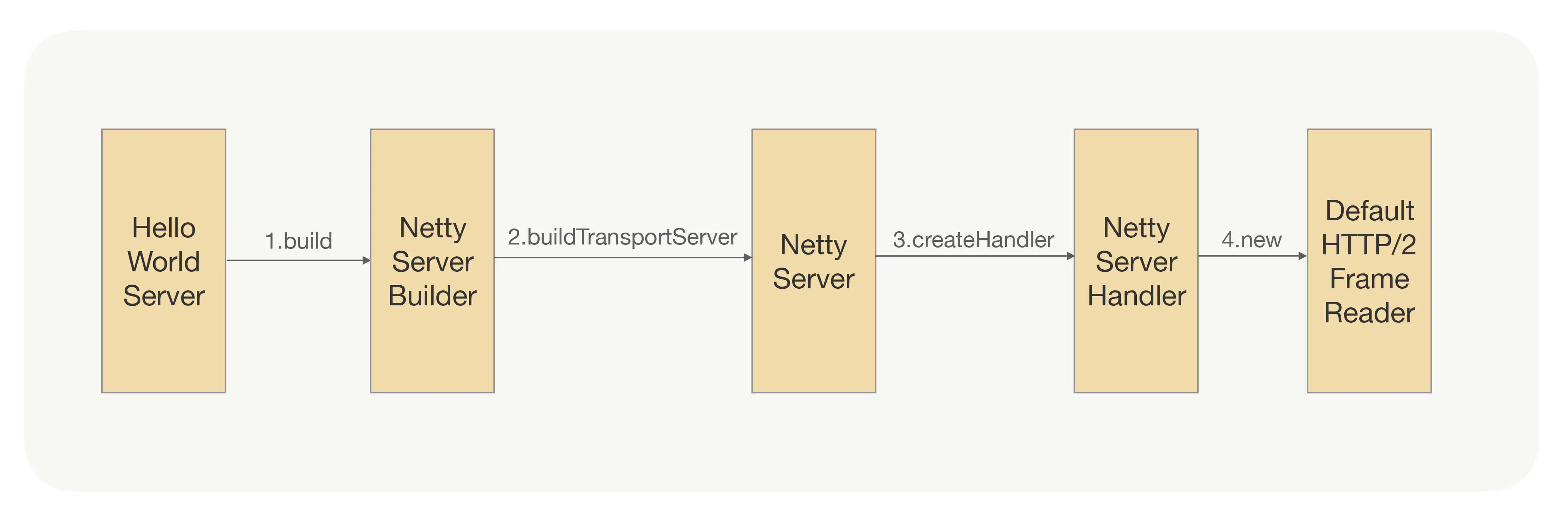
这四个步骤是用来开启一个 Netty Server,并绑定编解码逻辑的,如果你暂时看不懂,没关系的,我们可以先忽略细节。我们重点看下 NettyServerHandler 就行了,在这个 Handler 里面会绑定一个 FrameListener,gRPC 会在这个 Listener 里面处理收到数据请求的 Header 和 Body,并且也会处理 Ping、RST 命令等,具体流程如下图所示:
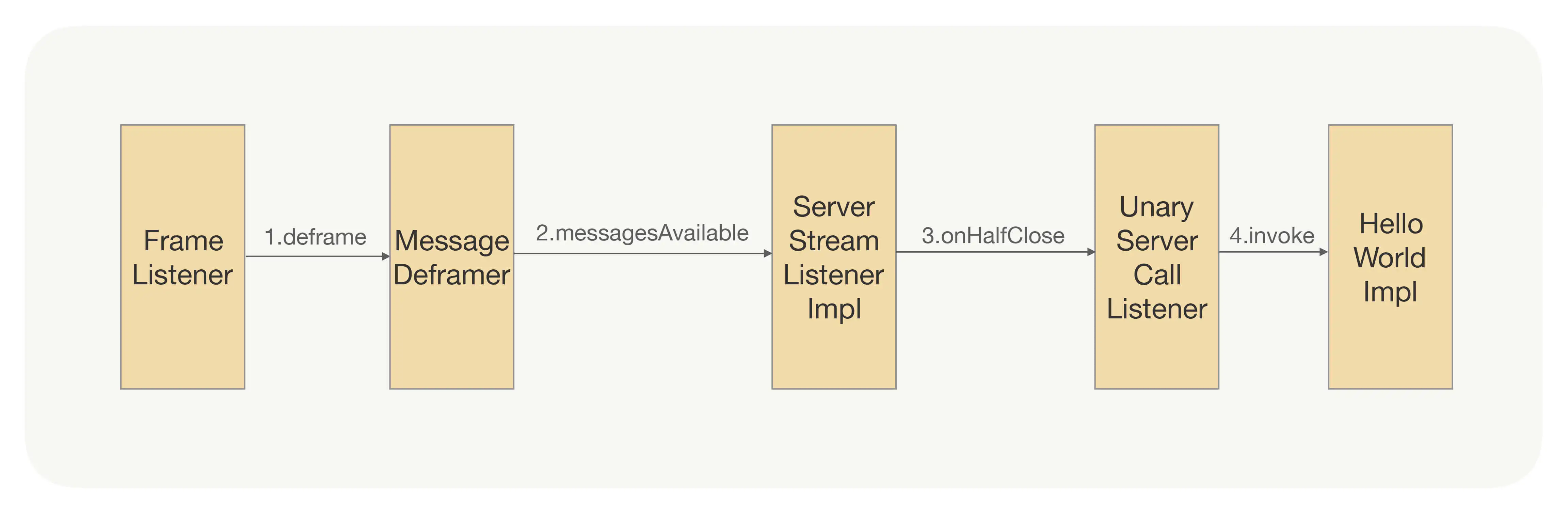
在收到 Header 或者 Body 二进制数据后,NettyServerHandler 上绑定的 FrameListener 会把这些二进制数据转到 MessageDeframer 里面,从而实现 gRPC 协议消息的解析。
那你可能会问,这些 Header 和 Body 数据是怎么分离出来的呢?按照我们前面说的,调用方发过来的是一串二进制数据,这就是我们前面开启 Netty Server 的时候绑定 Default HTTP/2FrameReader 的作用,它能帮助我们按照 HTTP/2 协议的格式自动切分出 Header 和 Body 数据来,而对我们上层应用 gRPC 来说,它可以直接拿拆分后的数据来用。
思考题:在 gRPC 调用的时候,我们有一个关键步骤就是把对象转成可传输的二进制,但是在 gRPC 里面,我们并没有直接转成二进制数组,而是返回一个 InputStream,你知道这样做的好处是什么吗?
RPC 调用在底层传输过程中也是需要使用 Stream 的,直接返回一个 InputStream 而不是二进制数组,可以避免数据的拷贝。