运行教程指南 #
Databricks:开始使用 MLflow 的最简单方法是使用 Databricks 提供的托管 MLflow 服务。这里有两个单独的选项,一个对于 Databricks 客户来说是最方便的,另一个是任何人都可以免费使用的。
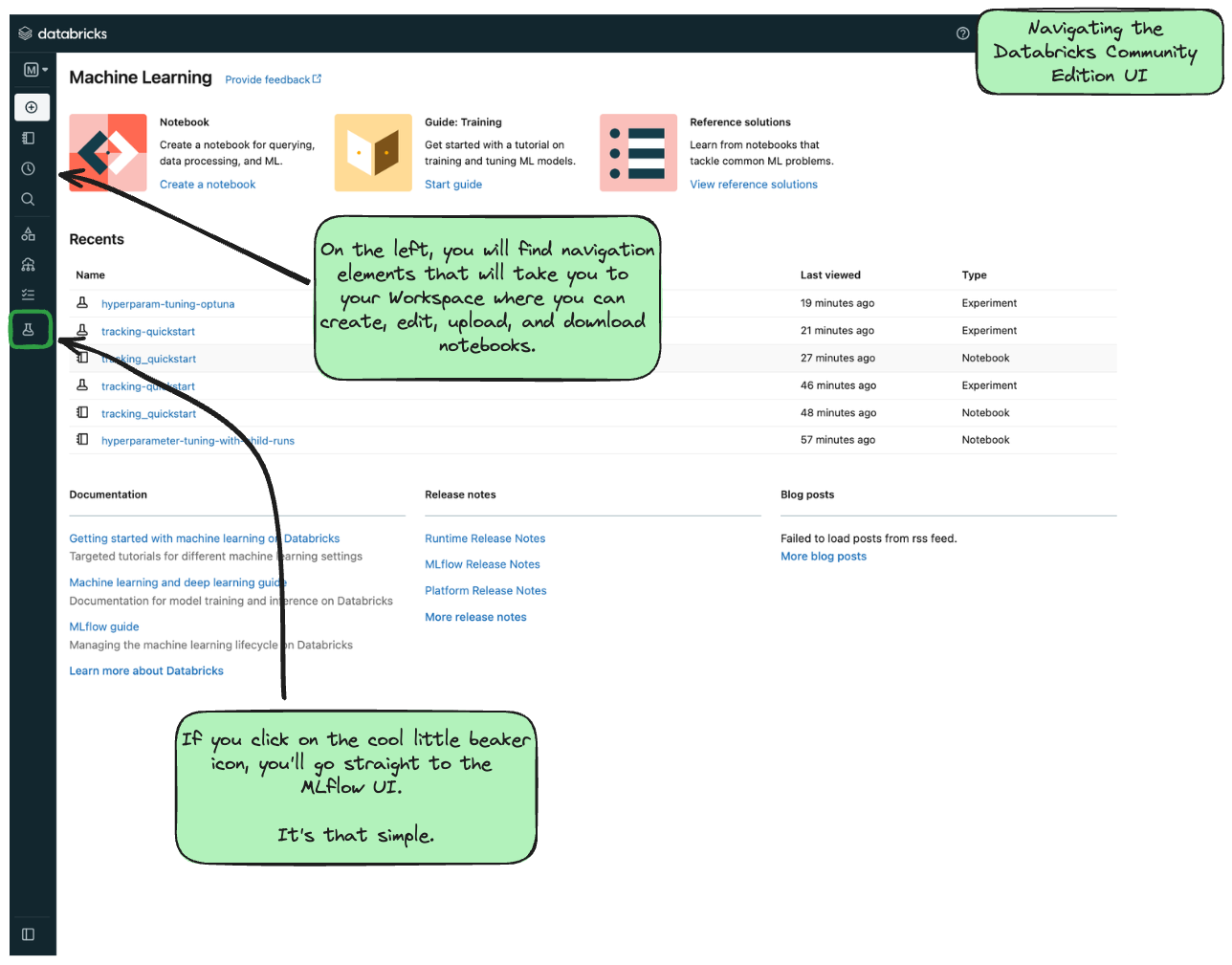
登录社区版后,您将看到如下所示的登录页面:
自己托管 MLflow 服务器:如果您想要使用自己的托管 MLflow 服务器,则只需将 MLflow 跟踪 URI 设置为指向您的服务器即可。如果连接有其他配置或访问限制,请联系管理 MLflow 部署的小组以获取更多信息。
要直接设置 MLflow 跟踪 URI(假设您没有设置额外的安全验证),您需要做的就是在笔记本中:
mlflow.set_tracking_uri(
"http://<your-mlflow-server>:<the port number that is configured to accept traffic>"
)
入门指南 #
MLflow Tracking 快速入门 #
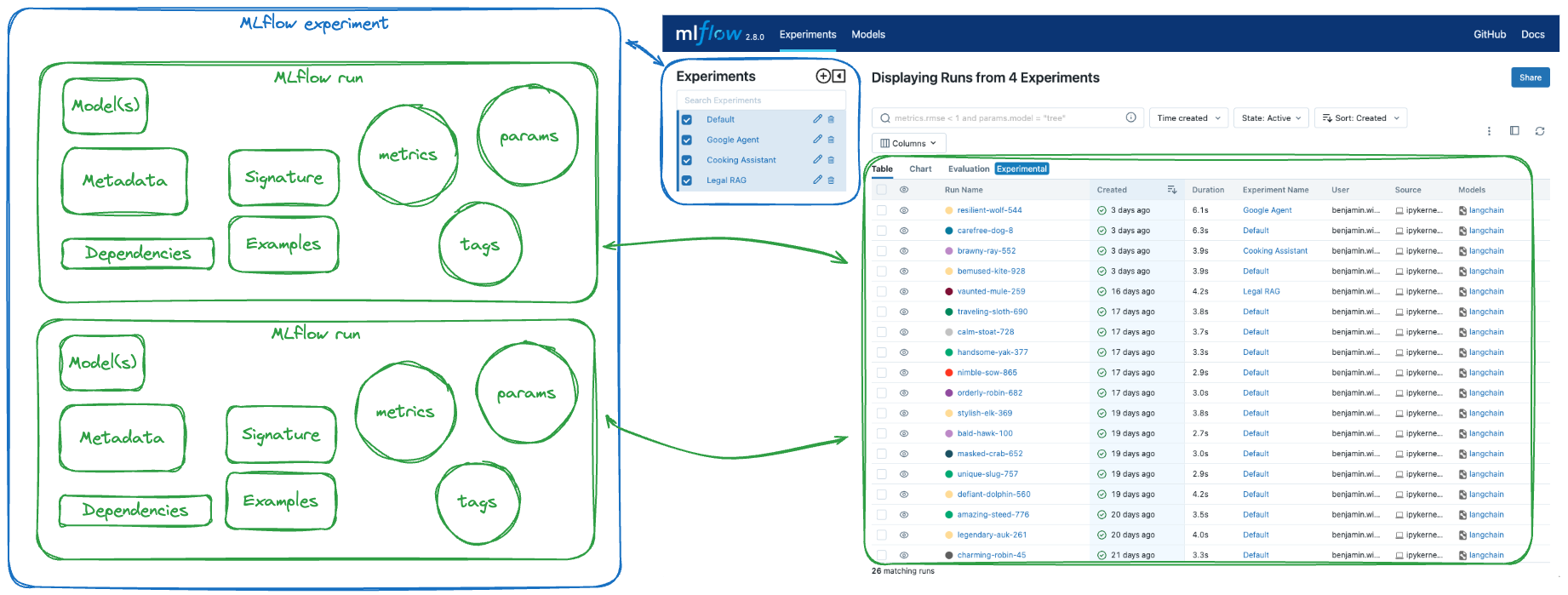
MLflow Tracking 是 MLflow 的主要服务组件之一,可以用来
- 记录模型的训练统计数据(损失、准确性等)和超参数
- 记录(保存)模型以供以后检索
- 使用 MLflow 模型注册表注册模型以启用部署
- 加载模型并将其用于推理
Step 1 - Get MLflow
pip install mlflow
Step 2 - Start a Tracking Server
- Using a Managed MLflow Tracking Server : 有关使用托管 MLflow 跟踪服务器的选项的详细信息,包括如何使用托管 MLflow 创建免费的 Databricks Community Edition 帐户。但是使用这些仓库需要用到 Google Cloud 相关的产品,只有14天的免费日期,之后就要付款

- (Optional) Run a local Tracking Server : 我们将启动一个本地 MLflow 跟踪服务器,我们将连接到该服务器来记录本快速入门的数据。从终端运行
mlflow server --host 127.0.0.1 --port 8080