
- Mátyás K K, MOROZ-DUBENCO C, Florentin B. Facilitating Model Training With Automated Techniques[J]. Studia Universitatis Babeș-Bolyai Informatica, 2023: 53-68.
在过去的十年中,人工智能 (AI) 已从一个流行词发展成为一项最先进的技术,为欺诈检测、医疗保健、预测性维护、能源管理和零售等各个领域提供可靠的解决方案。人工智能应用程序现在被用作企业核心流程中的独立解决方案。然而,随着对人工智能的需求呈指数级增长,曾经被视为学术实验的传统人工智能模型训练流程现在已成为一个后勤问题。需要迁移到可以自动化所有步骤的可靠流程,从清理原始数据集到训练模型并将其暴露给可以在现实场景中使用它的其他服务。
此外,人们还强调为没有人工智能背景的软件开发人员创建用户友好界面的必要性,这可以遵循灰盒原则,方便维护封装在模块中的人工智能流程。这些要求已经在软件工程领域得到解决,特别是在 Web 编程中,使用持续集成/持续部署 (CI/CD) 机制和 Web 服务。这篇论文的方法可以实现数据预处理的自动化,训练各种人工智能模型并选择性能最佳的模型,将该模型部署为供第三方使用的 Web 服务,同时确保服务的高可用性和可扩展性。
问题 #
在工业环境中开发基于机器学习的解决方案包括两个步骤:构建模型并将其部署到生产中。虽然第一部分可能更有趣,但第二部分花费的时间最长——模型构建和优化后的所有任务。根据 Gartner 的数据,85% 的大数据项目失败的前五个因素之一是部署的复杂性。
Gartner. https://www.gartner.com/en. Accessed: June 16, 2023.
Algorithmia 的“2021 年企业机器学习状况”报告称,64% 的组织至少需要一个月的时间来部署机器学习模型,而 38% 的组织的数据科学家花费超过 50% 的时间来部署机器学习模型生产。
Algorithmia. 2021 state pf enterprise ml. https://info.algorithmia.com/hubfs/ 2020/Reports/2021-Trends-in-ML/Algorithmia_2021_enterprise_ML_trends.pdf. Accessed: June 9, 2023.g
根据 Ashmore,工业环境中基于机器学习的解决方案的开发可以分为四个阶段。
Ashmore, R., Calinescu, R., and Paterson, C. Assuring the machine learning lifecycle: Desiderata, methods, and challenges. ACM Computing Surveys (CSUR) 54, 5 (2021), 1–39.
每个阶段都可以分为更小的步骤,Paleyes 提出了与每个步骤相关的各种问题和关注点,如下所述。
Paleyes, A., Urma, R.-G., and Lawrence, N. D. Challenges in deploying machine learning: a survey of case studies. ACM Computing Surveys 55, 6 (2022), 1–29.
- 数据管理 Data Management
- 模型学习 Model Learning
- 模型验证 Model Validation
- 模型部署 Model Deployment
数据管理 Data Management #
数据收集、汇集和理解。尤其是在大型生产环境中,问题可能会出现,在这种环境中,使用“单一责任”的原则,应用程序通常被构建为多个相互通信的服务,这很容易导致数据被不同的服务存储在不同的位置和形式。
Martin, R. C. The single responsibility principle. The principles, patterns, and practices of Agile Software Development (2002), 149–154.
数据收集后必须进行清理,据 Kim 的研究,数据清理是导致专家怀疑其工作质量的主要原因。
Kim, M., Zimmermann, T., DeLine, R., and Begel, A. Data scientists in software teams: State of the art and challenges. IEEE Transactions on Software Engineering 44, 11 (2017), 1024–1038.
数据不足、有偏差、有噪声、不相关或不平衡可能导致模型拟合不足或过度。此外,如果必须将多个数据源集成到一个数据源中,它们在模式、约定或存储和访问数据的过程方面可能会有所不同。一旦数据经过预处理,可能需要进行增强,因为在现实生活中,数据往往是未标记的,并且由于监督学习技术需要标记数据进行训练,因此可以为大量数据分配标签的过程,这是一项乏味的任务。最后,必须对标记数据进行分析,以发现偏差或意外的分布变化。此步骤中特别具有挑战性的一个领域是数据分析的可视化,因为可用于有效执行此任务的工具很少。
模型学习 Model Learning #
首先,需要选择最适合当前问题的模型。Wagstaff 表示在选择在资源受限的环境中使用的模型时,复杂性是最重要的因素之一。
Wagstaff, K. L., Doran, G., Davies, A., Anwar, S., Chakraborty, S., Cameron, M., Daubar, I., and Phillips, C. Enabling onboard detection of events of scientific interest for the europa clipper spacecraft. In Proceedings of the 25th acm sigkdd international conference on knowledge discovery & data mining (2019), pp. 2191–2201.
在实践中,选择更简单的模型,例如决策树、随机森林、主成分分析等,而不是深度学习或强化学习技术,因为它们需要更少的资源,并且还可以减少开发和部署时间。此外,根据应用领域,能够解释机器学习模型的输出甚至可以超过其性能。 然后,必须训练模型。此步骤通常需要增加计算资源,从而导致成本增加。Sharir 表明 BERT 模型的训练成本至少为 5 万美元,这对于许多公司来说是无法承受的。
Sharir, O., Peleg, B., and Shoham, Y. The cost of training nlp models: A concise overview. arXiv preprint arXiv:2004.08900 (2020).
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018).
更重要的是,在选择超参数以找到模型的最佳设置时可能会出现挑战。在最坏的情况下,超参数优化任务的规模可能呈指数级增长,从而导致严峻的计算挑战。在谈论深度学习技术时,这个过程可能非常昂贵且占用大量资源。
模型验证 Model Validation #
模型训练完成后,必须对其进行验证。此阶段涉及定义模型的要求,不仅应优先考虑提高模型性能,还应考虑用于在生产环境中评估和监控模型的业务驱动指标。除了数学正确性或错误界限之外,所有要求的验证都是必要的,包括遵守业务定义的监管框架。在现实环境中测试模型对于确保质量来说是理想的选择,但这可能会带来安全性和扩展方面的挑战。
模型部署 Model Deployment #
最后,在工业环境中开发基于机器学习的解决方案的最后阶段是模型的部署。必须实现模型才能使用它,并且需要构建用于运行模型的基础设施。由于机器学习模型可以明确依赖于外部数据,因此许多工程反模式(例如校正级联)在使用 ML 的软件中广泛存在。
Sculley, D., Holt, G., Golovin, D., Davydov, E., Phillips, T., Ebner, D., Chaudhary, V., Young, M., Crespo, J.-F., and Dennison, D. Hidden technical debt in machine learning systems. Advances in neural information processing systems 28 (2015).
一旦系统部署到生产中,就会进行维护。系统必须受到监控,但这个过程在机器学习社区中仍处于早期阶段,监控机器学习模型的整体性能仍然是一个悬而未决的问题。然而,当现有模型需要适应新数据并将新模型工件交付生产时,最大的挑战就出现了。虽然软件工程通过持续交付解决了这个问题,但机器学习问题变得更加复杂,因为与仅更改代码的常规软件产品不同,ML解决方案可以在三个方面进行更改:数据、模型和代码。
自动化人工智能训练的进展 #
最近,人工智能已成为一项尖端技术,在不同行业拥有众多用例。人工智能模型已被用作问题的新颖解决方案、辅助系统或完全替代人类干预。然而,这种需求的增长也暴露了一些挑战,例如可靠的模型训练、部署和实时生产消费机制的必要性。大型云服务提供商迅速发现了这一需求,并通过提供一整套促进大规模人工智能模型训练和部署的工具来满足这一需求。此外,还集成了现代 CI/CD 机制,以确保可扩展的解决方案满足高可用性、性能和日志记录的需求。
Li, W., Chen, J., and Huang, W. A survey on continuous integration, delivery and deployment tools. Journal of Systems and Software 147 (2018), 1–15.
AzureML 是 Microsoft 开发的基于云的机器学习平台,提供了针对各种用例实施人工智能模型所需的一整套工具。
Microsoft. Azure machine learning. https://azure.microsoft.com/en-us/services /machine-learning/, 2021. Accessed: February 7, 2023.
凭借其与不同人工智能模型架构集成的能力,它已被多家大公司用作从培训到部署的整个管道的可信生态系统。 例如,美国运通使用 AzureML 开发用于欺诈检测的应用程序,Mediktor 将其用于医疗保健解决方案以检查症状,E-ON 将其用于管理太阳能电池板农场的能源并预测能源解决方案,Belfius 使用它来帮助检测欺诈和金钱洗钱方面,Cognizant 和 Claro 利用 AzureML 个性化并改善用户的学习体验,Epiroc 在其帮助下推进制造创新 [19]。
Microsoft. Microsoft customer stories. Microsoft Azure Blog (January 2022).
AzureML 场景介绍…
自动化模型训练过程 #
管道架构 Pipelines architecture #
在架构头脑风暴过程中,最重要的考虑因素之一是从客户端接收各种数据集并随后触发管道的业务需求。这些数据集来自不同的仓库,采用不同的格式,包括 SQL 数据库、NoSQL 数据库和文件。因此,需要一个层来抽象训练数据的来源并允许管道交互,提供一个公开简单数据下载操作以及结果上传的接口。这种方法使我们能够提供一个无缝且灵活的管道,可以处理各种数据源,同时还有助于将多个数据源集成到管道中。在这种特殊情况下,我们可以认为这些模块将接收数据集作为输入,并通过应用的数据处理操作输出它。
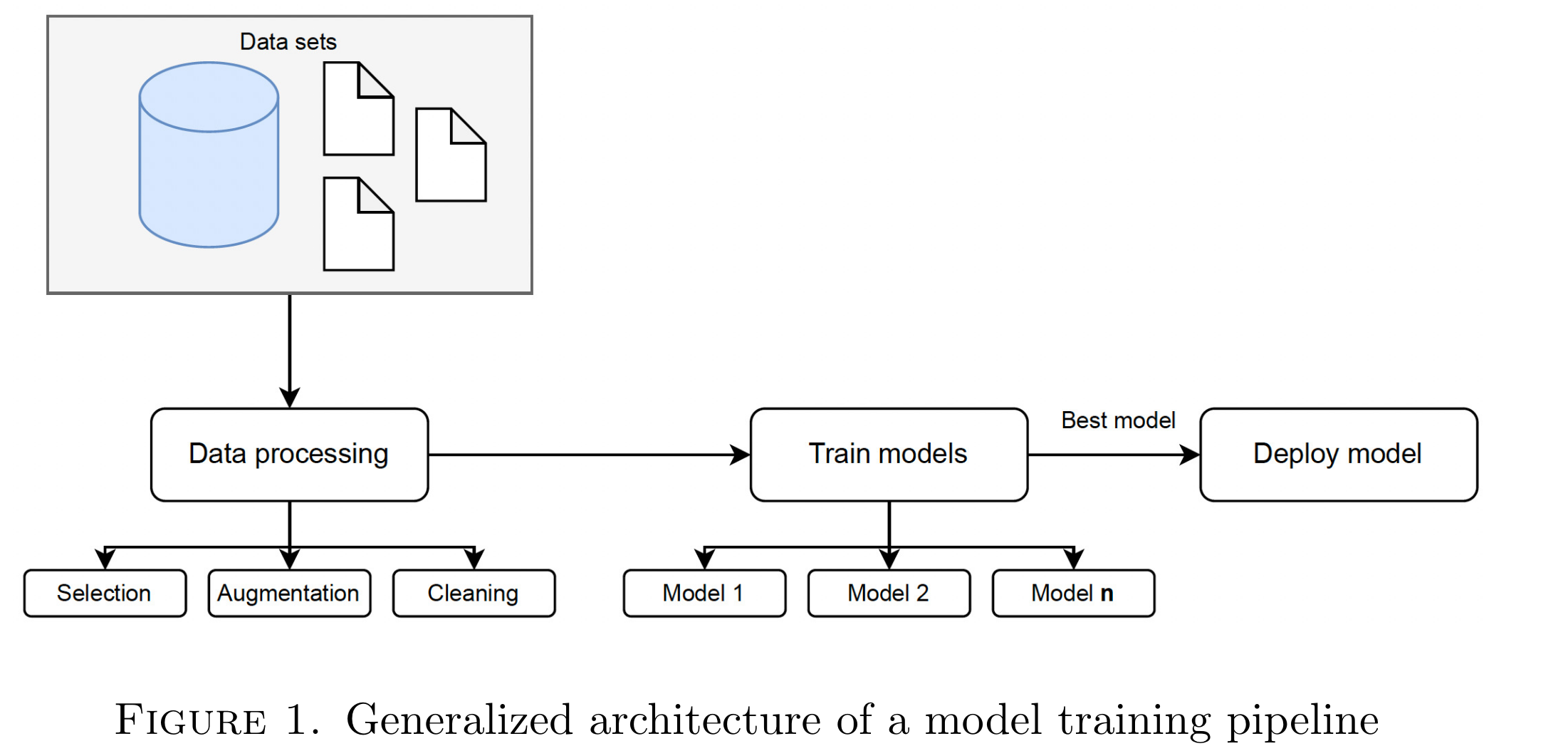
上图概述了拟议的管道,该管道代表了 CI/CD 部署中的软件工程原理与 AI 模型训练过程之间的最先进组合。定义数据接口后,我们继续开发一系列模块,对训练人工智能模型过程中所需的最先进的操作进行编码。每个模块都是通过接口定义的,每个模型都有输入和输出,从而可以在所需的管道内进行无缝组装。为了启动管道,我们首先为最知名的数据处理操作定义模块,从数据清理(即删除空值、重复数据删除和填充不完整数据)、数据增强(即分类数据的单热编码)开始 列或数据标准化)和列选择(即,如果需要,仅选择特定列)。通过这个过程,我们的目标是建立一个灵活且可扩展的管道,能够执行各种数据处理操作,以促进人工智能模型的有效和高效的训练。
数据清理过程之后,我们管道的下一步涉及模型训练。该阶段由一个伞形模块组成,该模块封装了各种子模型,每个子模型代表不同类型的模型,例如神经网络、逻辑回归、决策树等。该模块启动了所有这些模型的训练,随后选择了具有最高指标的模型,该模型是根据其准确性确定的。该管道模块的输出是一个灵活的二进制文件,可以在模型部署的后续阶段进行部署。
为了将经过训练的二进制模型暴露给公司软件堆栈的其他组件,我们实现了一种允许输入新数据和检索推断结果的机制。遵循 Web 开发的最佳实践,我们决定使用微服务,因为它们具有高可用性、版本控制和可扩展性的功能。
AzureML Pipelines #
Microsoft AzureML 平台代表了基于云的技术的重大进步,为用户提供了一系列用于数据处理、模型训练和版本控制以及大规模部署的功能。鉴于我们的架构要求和项目需求,AzureML 被证明是非常适合我们工作的解决方案。
AzureML 的管道设计器功能是一种低代码/无代码解决方案,用于开发用于模型训练和预测的机器学习管道。可视化组件支持管道的配置,只需对底层转换和机器学习算法有有限的了解即可执行管道配置。此外,其预先构建的基础设施和精心设计的环境使我们能够以最小的维护开销运行这些管道,而其多功能的功能套件使我们能够为我们的项目开发必要的模块。 AzureML 平台中的可视化管道设计器和具有策划环境的托管基础设施为寻求简化 AI 工作流程并提高运营效率的组织提供了创新且高效的解决方案。
Microsoft AzureML 通过实施 Azure 数据集提供了另一个重要的接口,用于管理客户端使用的各种数据集。此功能允许从不同来源(包括内部和外部数据存储库)加载表格格式的数据集。此外,Azure 数据集可以进行版本控制,并且其创建可以触发关联管道的执行。
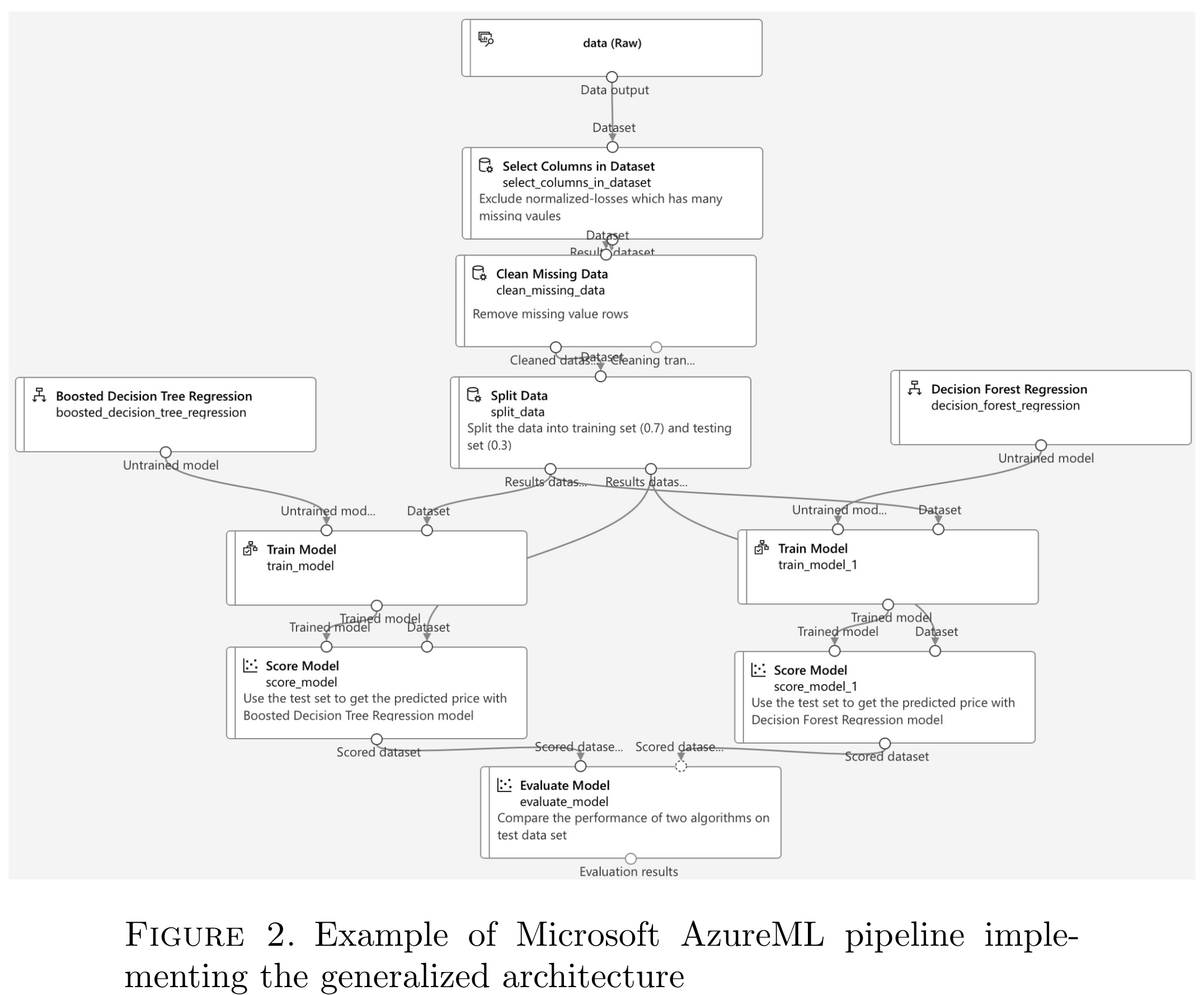
上图中所示的演示管道以 Azure 数据集开始,该数据集充当后续数据处理步骤的主要输入。具体来说,管道执行一系列数据处理模块,包括列选择、缺失数据删除和数据分割。数据分割模块将输入数据集划分为单独的训练集和测试集,随后将其输入到训练模块中以进行模型开发。每个模块都包含可自定义的属性,可以根据特定的用户需求进行调整。例如,数据分割模块中分配给训练集和测试集的数据的百分比可以根据需要进行配置。
在初始数据处理步骤之后,管道中的下一组模块涉及多个人工智能模型的训练,特别是决策树系列的回归模型。每个模型都通过训练模型模块使用指定的训练集进行训练,然后通过评分模型模块使用测试集进行测试。在此阶段结束时,使用评估模型模块来比较和评估每个训练模型的性能,最终目标是确定最佳模型。然后可以使用建立的阈值来确定性能最佳的模型是否满足业务案例的要求。如果模型超过预定义的阈值,则可以将其部署在生产环境中使用。因此,通过使用这些模块,AzureML 可以高效开发、测试和评估多个 AI 模型,最终目标是为给定任务确定最佳解决方案。
AzureML 的灵活性和可扩展性通过其开放的内置组件库得到了进一步体现,该库由充满活力和支持的社区维护。对于许多用例,内置组件满足开发机器学习模型的必要要求。但是,在需要特定和专有步骤的情况下,开发人员可以利用 Python 编程语言和 azureml 库来实现自定义构建的组件。在与外部客户合作的背景下,我们设计和开发了一系列神经网络(特别是 LSTM 和 GRU 模型 ),这些网络经过定制和优化,以满足合作者的需求。然后,这些模型被部署为我们开发的 AzureML 管道中的自定义组件。虽然我们实现的模块和组件是根据我们的特定用例量身定制的,但它们仍然遵循总体原则,即让模型根据各自的准确性水平进行竞争以确定获胜者。通过提供使用预定义组件和实施定制组件的能力,AzureML 为 AI 开发的性能和可维护性提供了显着的提升,即使对于非专业开发人员也是如此。
Hochreiter, S., and Schmidhuber, J. Long short-term memory. Neural computation 9, 8 (1997), 1735–1780.
Chung, J., Gulcehre, C., Cho, K., and Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv preprint arXiv:1412.3555 (2014).
自动化模型训练和部署 #
为了实现模型训练和部署的强大生态系统,必须拥有一个结构良好的自动化管道,该管道可以响应一系列事件,根据预定义的阈值验证模型,并仅在阈值达到时将模型部署初始化为新版本超过了。为了确保流程顺利高效,拟议的管道必须遵循 CI/CD 原则,它提供了一组用于实时训练机器学习模型的协议,并使用 AzureML 提供的基础设施以高可用性和可扩展性部署它们。通过遵循 CI/CD 的原则,可以构建管道以简化模型开发流程、降低管理成本并最大化 AI 开发流程的投资回报。一般来说,CI/CD 原则对于确保模型训练和部署管道的稳健性和可扩展性至关重要,从而促进模型的快速部署,同时最大限度地减少对整个工作流程的干扰。
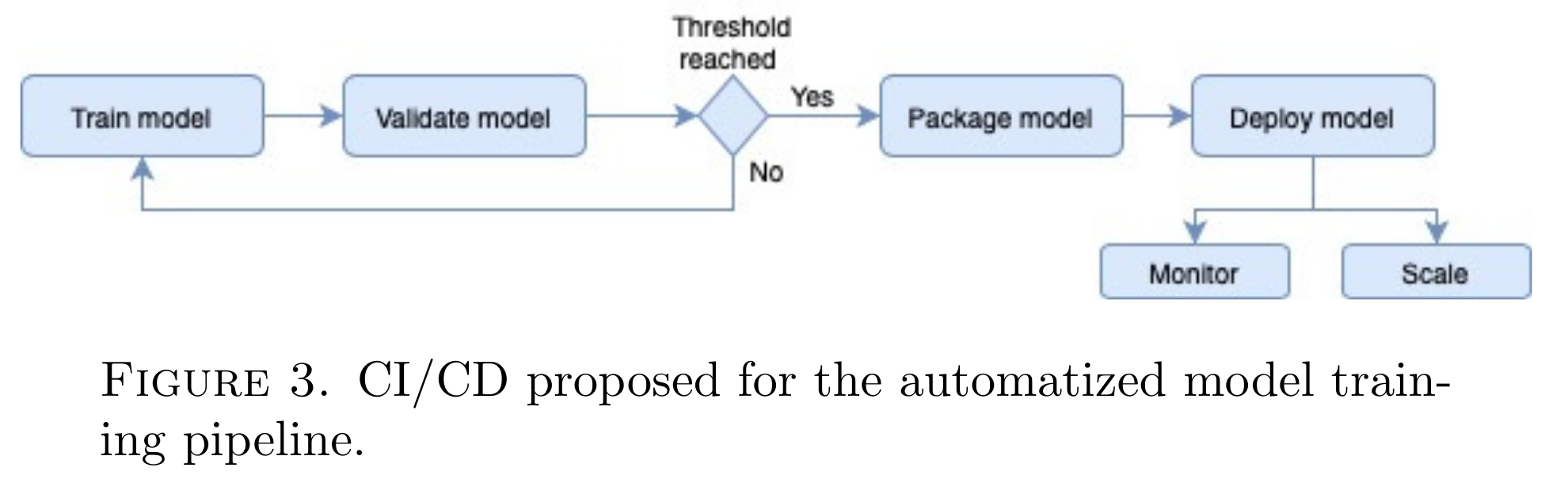
上图描述了在 Microsoft AzureML 生态系统中使用 CI/CD 进行模型训练的建议自动化机制。每当与管道关联的 Azure 数据集发生更改时,都会触发 CI/CD 系统,指示新数据集可用于训练。然后,系统会提取最新版本的数据集并启动管道。如果管道中的组件位于层次结构中的同一级别,则它们将被并行化,从而允许同时执行所有模型训练,从而节省时间和资源,从而节省成本。
在所提出的 CI/CD 管道的训练后阶段,最佳模型的准确性将与阈值进行比较,如果未达到阈值,将触发通知管理员对训练集进行额外的微调或修改组件(例如,通过添加更多清洁方法)。另一方面,如果超过阈值,最佳模型将被打包为二进制模型,封装到 Docker 化的 Web 微服务中。
Merkel, D. Docker: lightweight linux containers for consistent development and deployment. Linux journal 2014, 239 (2014), 2.
该微服务将作为服务部署在 AzureML 基础设施上,它将通过端点公开模型。此过程确保模型可以随时被其他服务使用。
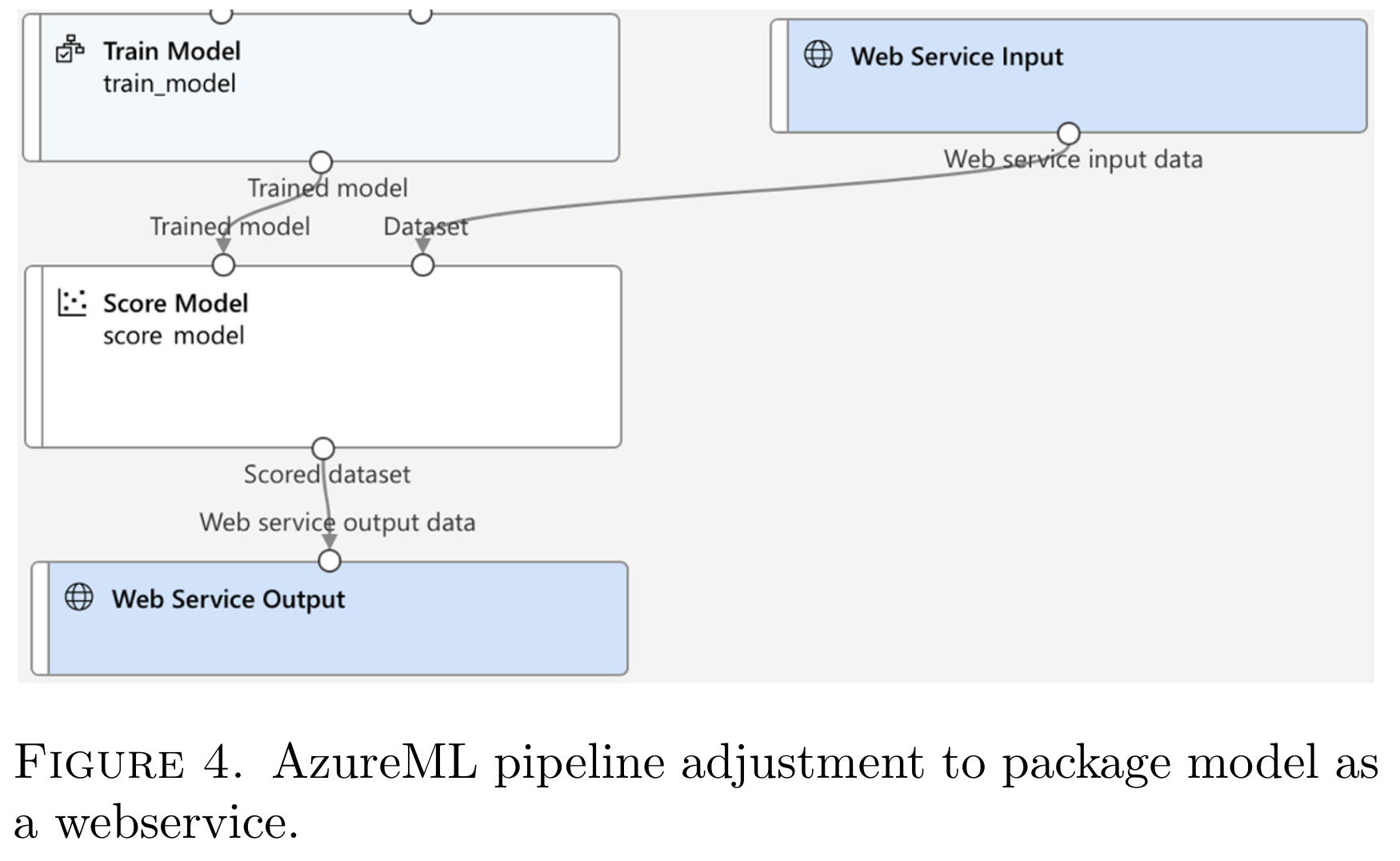
在 AzureML 的上下文中,打包训练模型的机制可以通过使用两个关键组件来实现,即 Web 服务输入模块和 Web 服务输出模块,如下图所示。
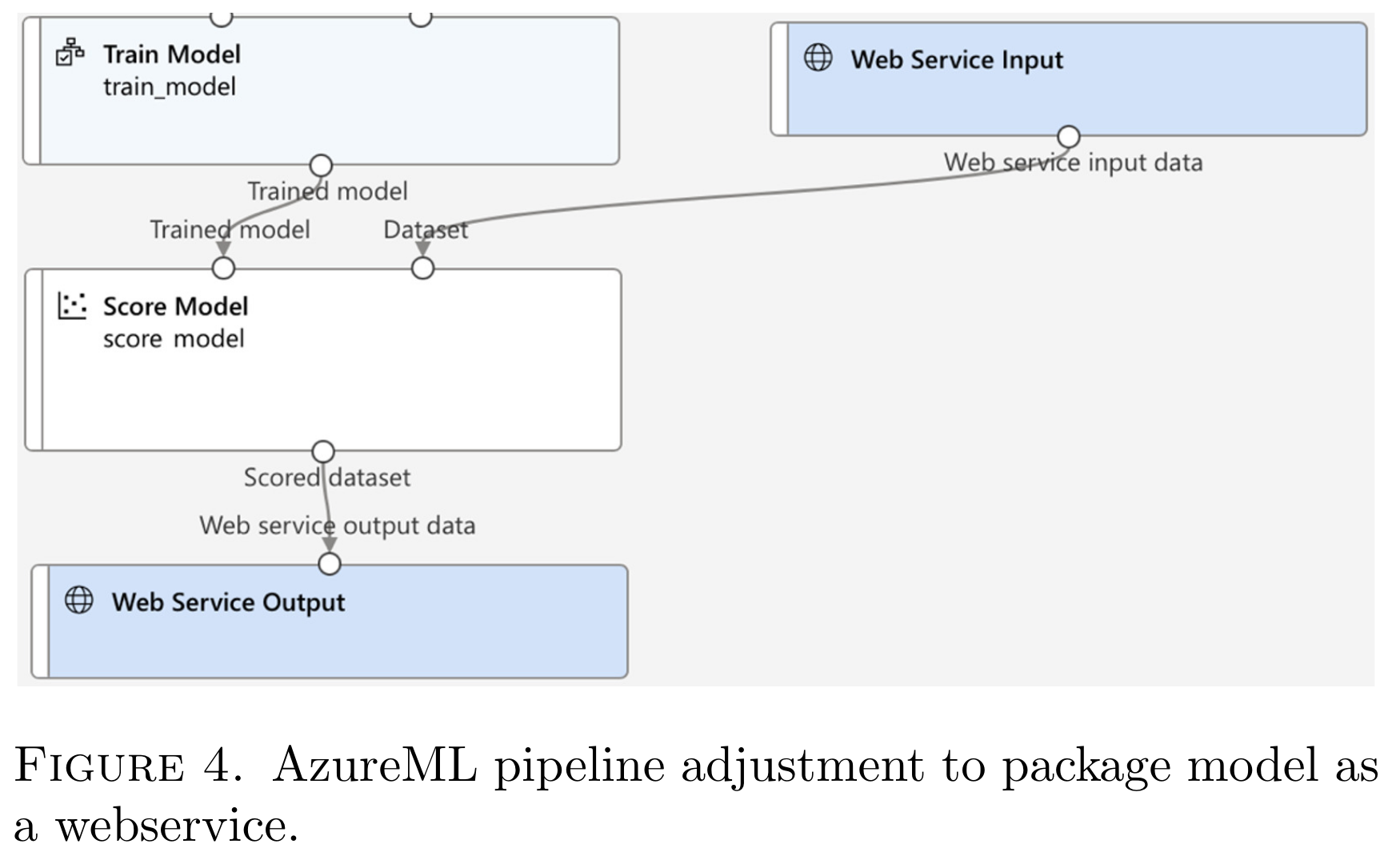
这些组件使 AzureML 能够识别输出火车模型部分的目的是封装在 Web 服务中。Web 服务输入组件负责接收一组输入参数,然后将这些参数传递给负责处理输入并将其提供给模型进行推理的组件。然后,模型输出被传递到 Web 服务输出组件,该组件又将结果返回到发起请求的服务。
CI/CD 管道完成后,生成的 Web 服务可以位于 AzureML 端点部分,该部分提供与模型交互的所有必要详细信息。除了支持微服务的部署之外,AzureML 还包含一系列在部署后阶段特别有用的功能,确保模型的高可用性和性能。我们认为其中两个内置功能非常有用:容错 - AzureML 保证至少一个 Web 服务实例始终处于运行状态 - 以及自动扩展 - 在需求较高的情况下, Web 服务可以扩展到通过负载均衡器管理的多个实例。
用于模型训练、验证和部署的底层基础设施可以配置为在 CPU 或 GPU 上运行。通常,GPU 在训练阶段是必不可少的。虽然 GPU 虚拟机比配备 CPU 的虚拟机贵得多,但权衡模型训练所需的时间与每小时成本可能会产生涉及 GPU 实例的经济高效的解决方案。
建议使用 AzureML 管道进行模型训练和部署的解决方案是一种自动化机制,从将新数据集版本上传到关联的 Azure 数据集开始,一直持续到模型部署的最后一步。这种方法提供了自主且直观的维护过程的好处,因为管道的每个步骤都是根据定义的逻辑自动执行的。该管道及其部署机制适用于实时环境中使用的Web应用程序,满足可用性、易于维护和调试以及快速执行等要求。监控系统还可以快速识别和解决任何问题。由于所有这些,所提出的解决方案为自动化模型训练和部署过程提供了全面且可靠的解决方案。
使用经过训练的模型 #
本节介绍如何将 AzureML 中的模型部署为微服务,以及使用 Swagger 实现 Web 服务或 API 的标准化。 部署模型后,可以通过 HTTP 请求访问它,并且可以在 AzureML 端点部分找到有关 Web 服务的所有相关信息,例如 REST 端点、身份验证类型和监视日志。 此外,通过 AzureML Pipelines 创建的 Web 服务包含其自己的文档,其中提供了有关现有 Web 服务端点、其预期输入结构和预期输出结构的详细信息。 Swagger 是一种用于标准化 Web 服务或 API 的流行标准,它在 AzureML 中实现,以支持与语言无关的解决方案。 因此,任何具有 HTTP 框架的编程语言都可以向模型发出请求,并期望输出遵循其 Swagger 描述的结构。
Swagger: The world’s most popular framework for apis. https://swagger.io, 2022. Accessed: Feb. 7, 2022.