转载自 https://www.showmeai.tech/article-detail/60 本文为笔者自学的资料,读者若需要请支持原版。
一、多目标优化介绍 #
什么是多目标优化场景
多目标排序是推荐排序系统中常见的技术实现,在很多推荐与排序常见中,有多个业务目标,找到一种综合排序方法使得多个目标都达到整体最优,能有最好的总体收益。
为什么需要多目标优化
为什么需要多目标排序呢,在实际互联网的推荐系统产品中,大多数用户反馈都不是直接评分,而是各式各样的隐式反馈,比如说用户的点击、收藏、分享、观看时长、下单购买等。 在评估用户满意度与设定优化目标时,可能有一些偏差:

- 全局偏差/Global bias:不同目标表达不同的偏好程度。
- 电商场景中,购买行为表达的偏好高于点击浏览和收藏
- 新闻场景中,浏览时长超过20s这个行为表达的偏好高于点击
- 短视频场景,完播行为表达的偏好高于点击
- 物品偏差/Item bias:单个目标衡量不全面。
- 信息流产品中,标题党增加点击率,但降低满意度
- 短视频场景中,悬念设计提升完播率,但需要观看下一个引发用户更多操作的不满
- 自媒体资讯产品,鼓励转发率,可能会提升『转发保平安』等恶性操作
- 用户偏差/User bias:⽤户表达满意度的⽅式不同
- 信息流产品中,用户有 深度阅读、点赞、收藏 等不同表达满意的方式
- 短视频场景中,用户有 点赞、收藏、转发 等不同表达满意的方式
下图为部分互联网产品下,用户包含信息反馈的行为路径。
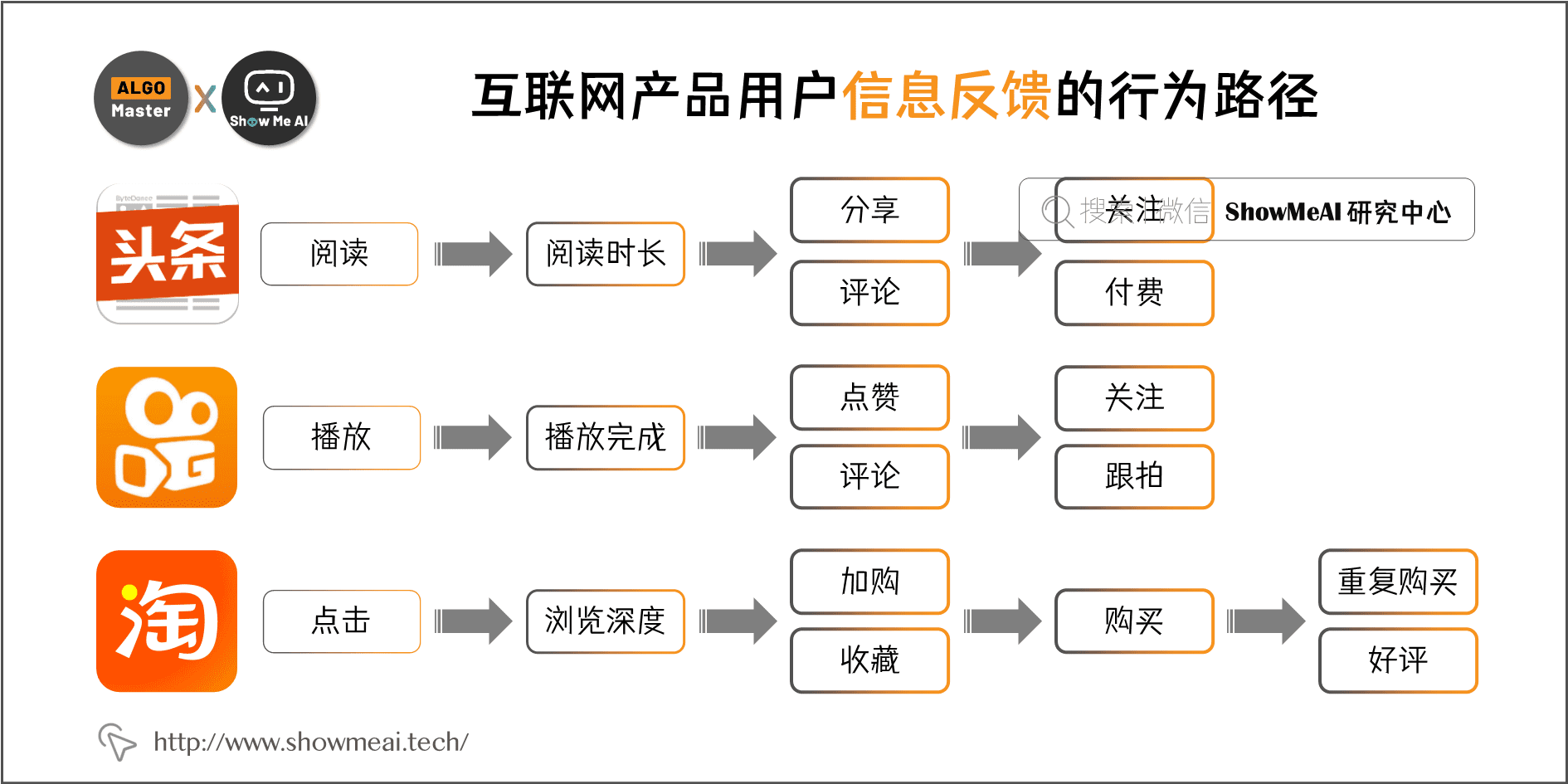
在上述众多互联网业务中,工程师优化和提升的目标可能是多个,比如,短视频推荐任务,既要点击率又要完播率;电商排序,既要点击率又要转化率。

多目标优化的难点
多目标优化的主要技术实现是在推荐系统的『排序』环节完成,如下所示的信息流推荐中,排序环节影响最终展示结果,进而对目标效果影响最为直接。
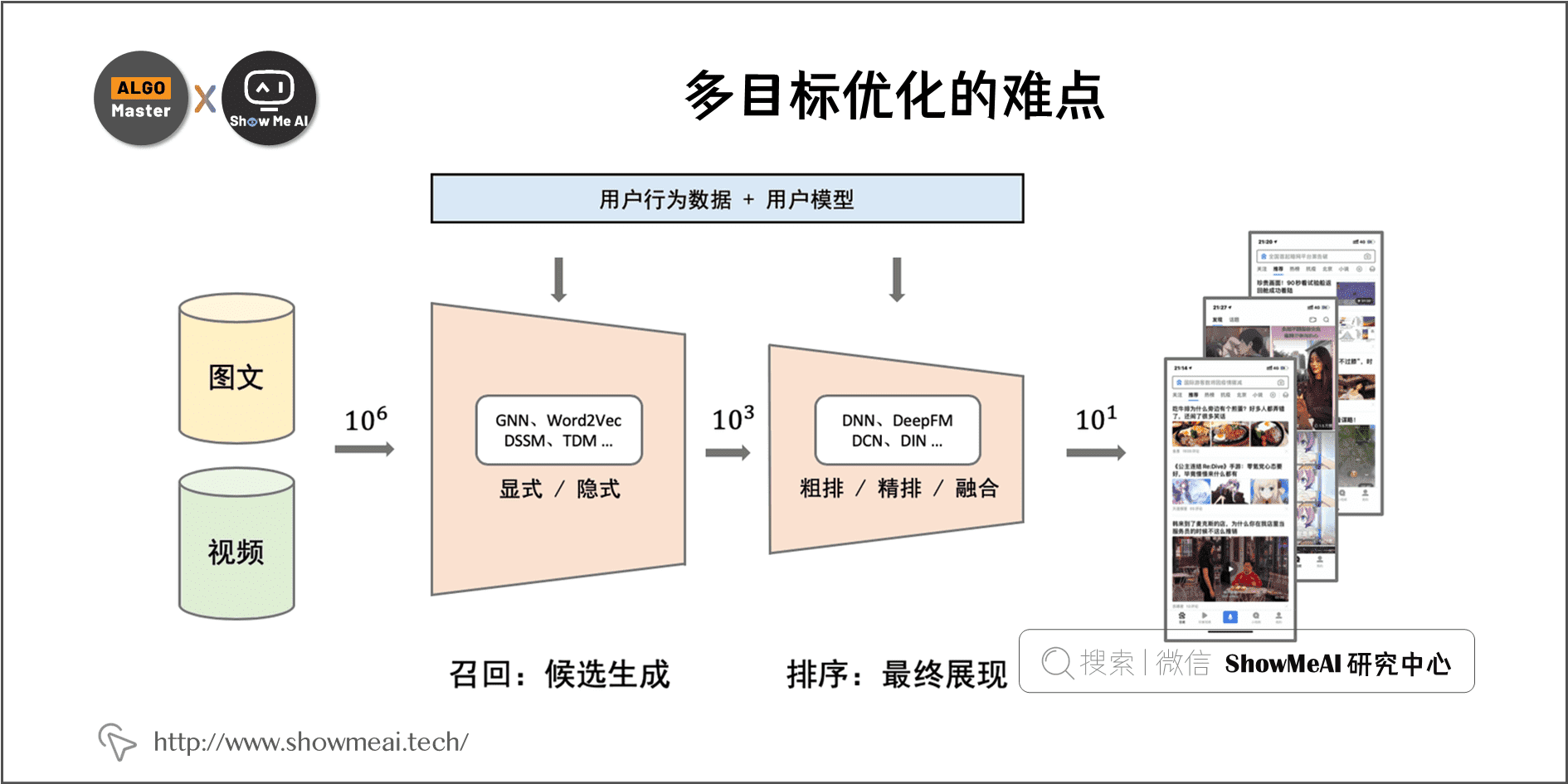
排序环节多使用CTR预估(click through rate prediction)技术来完成,业界有非常成熟的机器学习与深度学习技术方法与方案。但是,应用在多目标学习优化中,有五大难点:
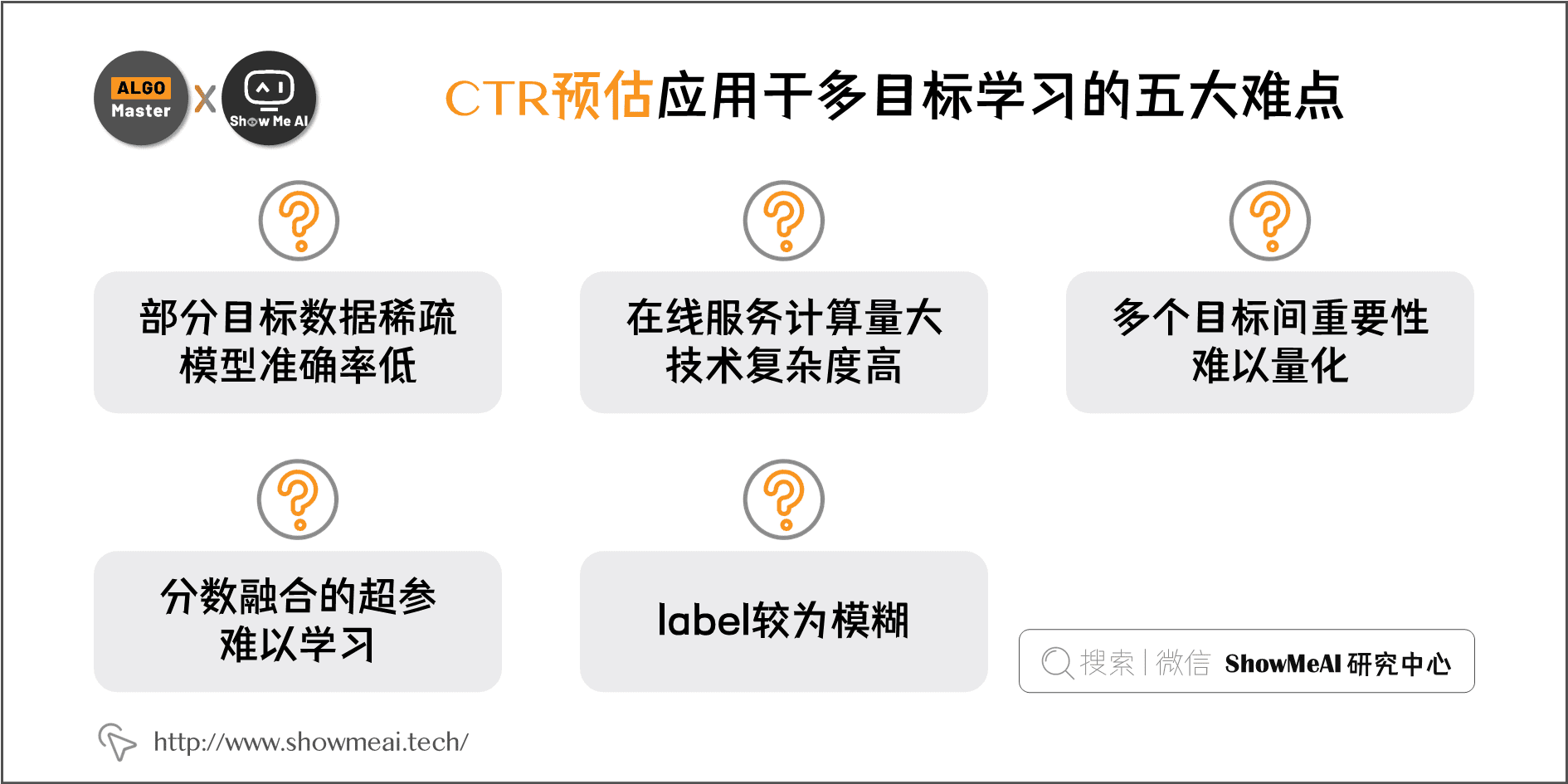
- 部分目标数据稀疏,模型准确率低。 比如在电商产品中,用户下单行为显著稀疏于点击行为,下单的标签正样本数量和比例都偏小
- 在线服务计算量⼤。通常多目标优化的模型有着更为复杂的模型结构,在线预估时,计算复杂度也更高;实时推荐任务需要有短响应时间和高并发支撑的稳定性,技术复杂度高一些。
- 多个目标间重要性难以量化。在追求点击率又追求完播率的短视频中,这两个target如何量化权衡重要度?
- 分数融合的超参难以学习。很多建模方案中,我们会量化得到不同的目标score,但最终融合时,涉及到的融合计算超参数不容易通过业务直接敲定,也没有合适的方法让模型学习
- Label较为模糊。很多业务中,连标签本身也是模糊的,比如资讯类产品中的阅读时长多长算长?
多目标vs多任务
实际技术解决方案中,有几个非常相似的概念,分别是 多任务、多目标、多类别,他们的定义和关联如下图所示:
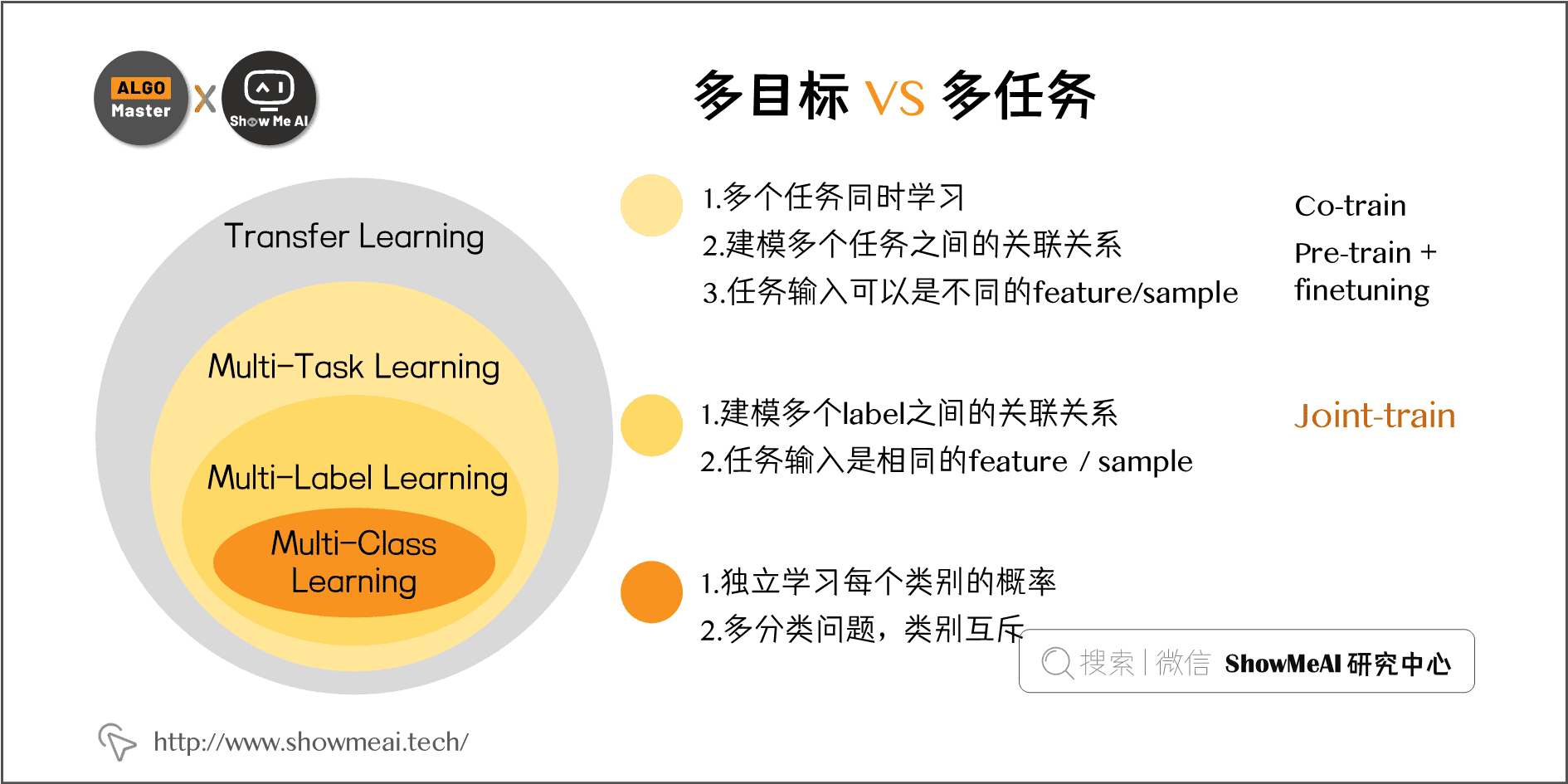
在我们这里提到的推荐多目标优化中,其实不同的目标也对应不同的 task。 比如电商场景下,在推荐的排序阶段进行CTR建模,对同一输入样本同时预估点击率、转化率多个目标,在这个场景下,我们认为多目标多任务优化可以采用同一套方法。
我们经常使用联合训练Joint-train的模式进行多目标优化学习,公式如下:
$$ L=min_{\theta} \sum^{T}_{t=1} \alpha ^t L^t (\theta ^{sh}, \theta ^{t}) $$
- $\theta ^ t$ 是任务 $t$ 的独享参数,总 $Loss$ 是每个子任务对应 $Loss$ 的带权求和。
二、多目标学习与共享参数 #
多任务多目标学习的实现,我们现在多采用『共享』机制完成,可以在不同任务的模型参数和特征共享两方面做设计。

- 模型架构方面:在深度学习网络中可以共享embedding特征,或者共享中间层的某些隐藏单元,也可以是模型某一层或者最后一层的结果,并且共享之外的部分各自独立。在模型的设计中,层间关系自由组合搭配。
- 特征组合方面:多个任务可以采用不同的特征组合,有的特征只属于模型架构的某个部分,有些特征整个模型都可以使用。
典型的一些参数共享机制
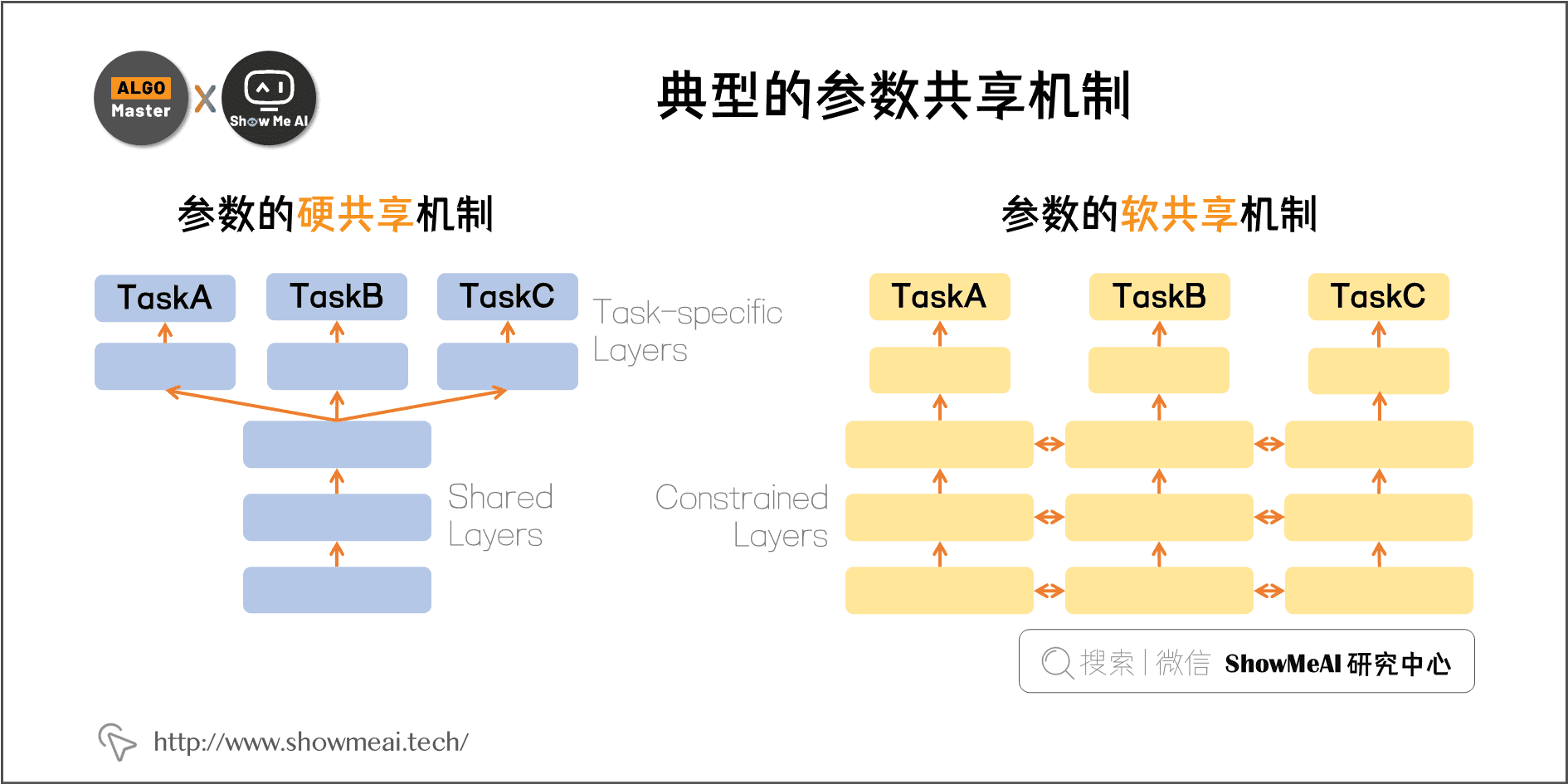
- 参数的硬共享机制(基于参数的共享,Parameter Based):基于参数的共享是多目标学习最常用的方法。在深度学习的网络中,通过共享特征和特征的embedding以及隐藏层的网络架构,在最后一层通过全连接+softmax的方式来区分不同任务,最后做一个线性融合来实现多目标排序。
- 参数的软共享机制(基于约束的共享,Regularization Based):参数的软共享机制,每个任务都有自己的参数和模型结构,可以选择哪些共享哪些不共享。最后通过正则化的方式,来拉近模型参数之间的距离,例如使用 L2 进行正则化。
多目标优化的4种结果
实际多目标优化,在采用共享机制设计的各种模型结构后,可能有『Well Done』、『还不错』、『不理想』、『无法接受』 这 $4$ 种不同的结果:
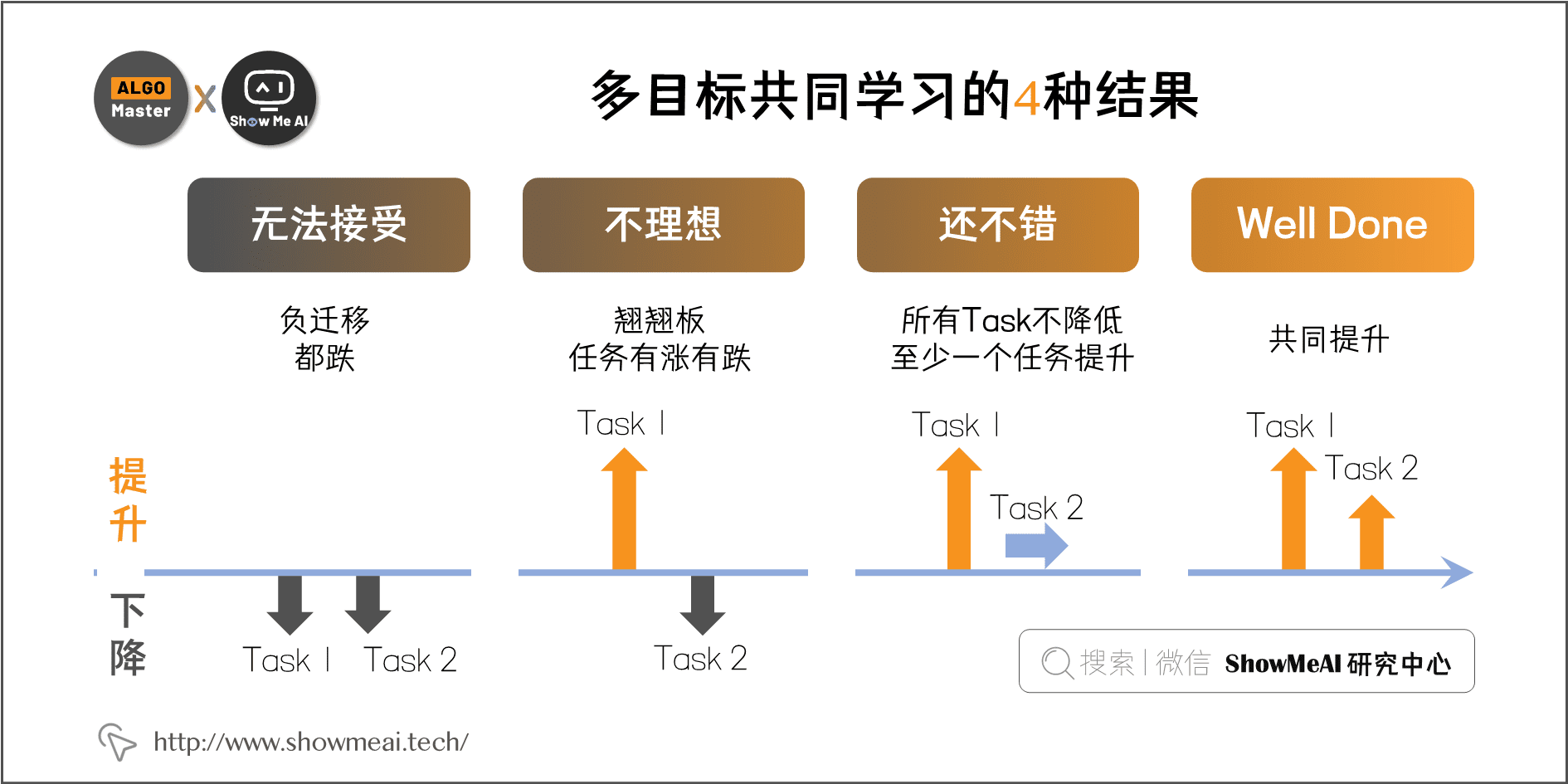
- 『Well Done』:最好的状态,所有share任务实现共同提升。
- 『还不错』:其次的状态,所有任务不降低,至少一个任务提升。如果是 主任务 + 辅助任务 的搭配,能够实现牺牲辅助任务达到主任务提升的效果,也是 well done。
- 『不理想』:跷跷板现象,任务有涨有跌。
- 『无法接受』:负迁移现象,所有任务都不如从前。
三、多目标学习两大优化方向 #
为了能够更好地『共享参数』,让同个模型中多个任务和谐共存、相辅相成、相得益彰,研究界有两大优化方向,分别是:
- 网络结构优化,设计更好的参数共享位置与方式
- 优化策略提升,设计更好的优化策略以提升优化 $Loss$ 过程中的多任务平衡

- 优化方向1:网络结构设计。网络结构设计方向思考哪些参数共享,在什么位置,如何共享等。
- 优化方向2:优化方法与策略。多目标优化策略从loss与梯度的视角去思考任务与任务之间的关系。平衡loss体量(Magnitude),调节loss更新速度(velocity),优化Gradient更新方向(direction)。在微观层面缓解梯度冲突,参数撕扯,在宏观层面达到多任务的平衡优化。
四、优化方向1:网络结构优化 #
4.1 总体思想与演进思路 #
网络结构设计是目前多任务研究和应用的主要焦点,它主要思考哪些参数共享,在什么位置,如何共享。优秀合理的共享网络结构对于最终效果提升作用巨大。
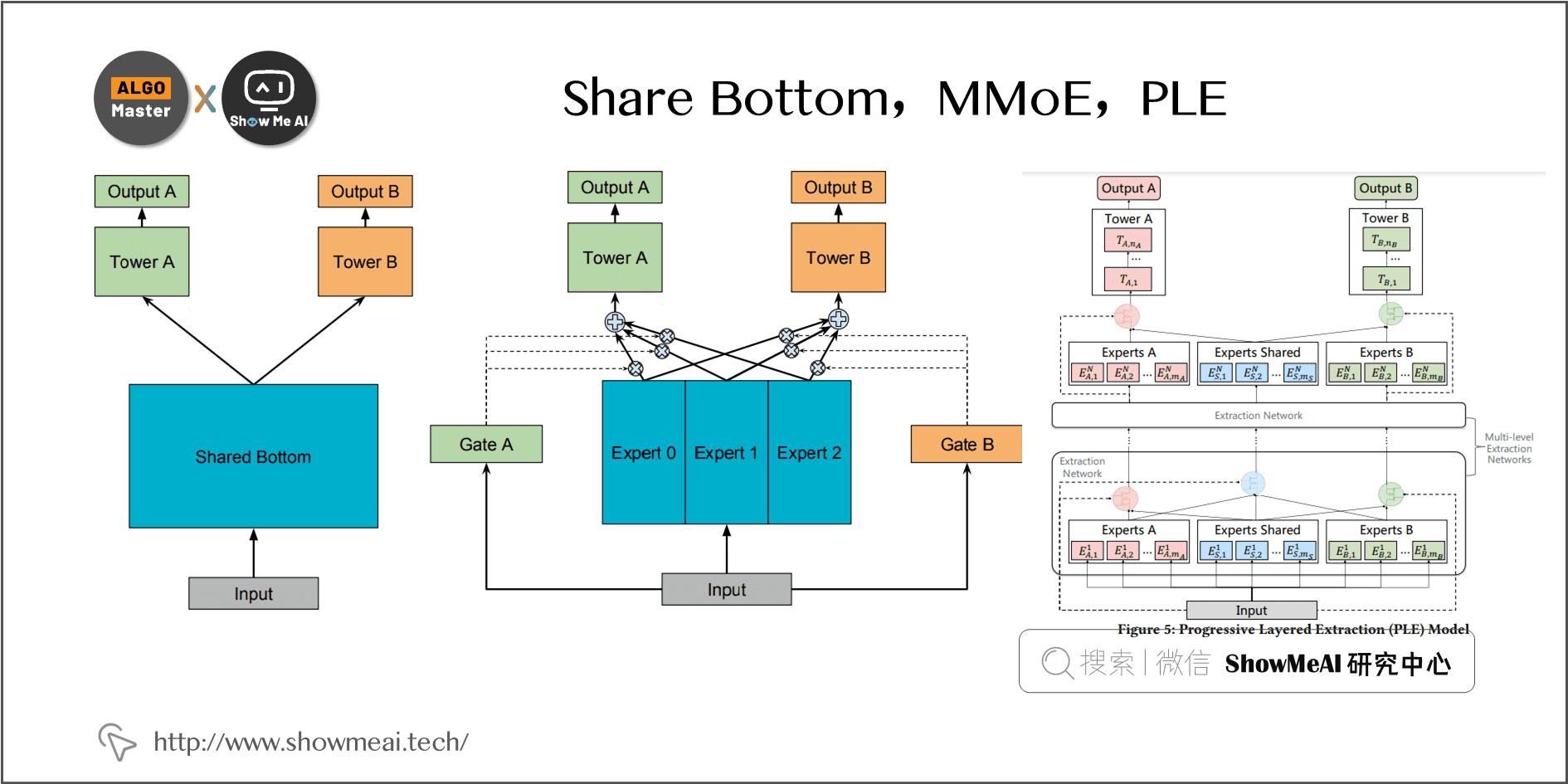
近年来网络结构设计经历了 Share Bottom 公式 MMoE 公式 PLE 的典型结构变迁,重要的业界顶尖企业研究人员发表的多任务网络结构设计论文包括:
- Share Bottom:早期一直在使用的方式,参数共享(hard或者soft)的方式来对多任务建模。
- 2018 Google MMOE:将hard的参数共享变成多个 expert,通过门控来控制不同loss对每个expert的影响。
- 2019 Google SNR:借助简单的 NAS(Neural Architecture Search),对 Sub-Network 进行组合,为不同目标学习各自的网络结构。
- 2020 腾讯 PLE:在 MMOE 的基础上增加了各任务独有的 Expert。
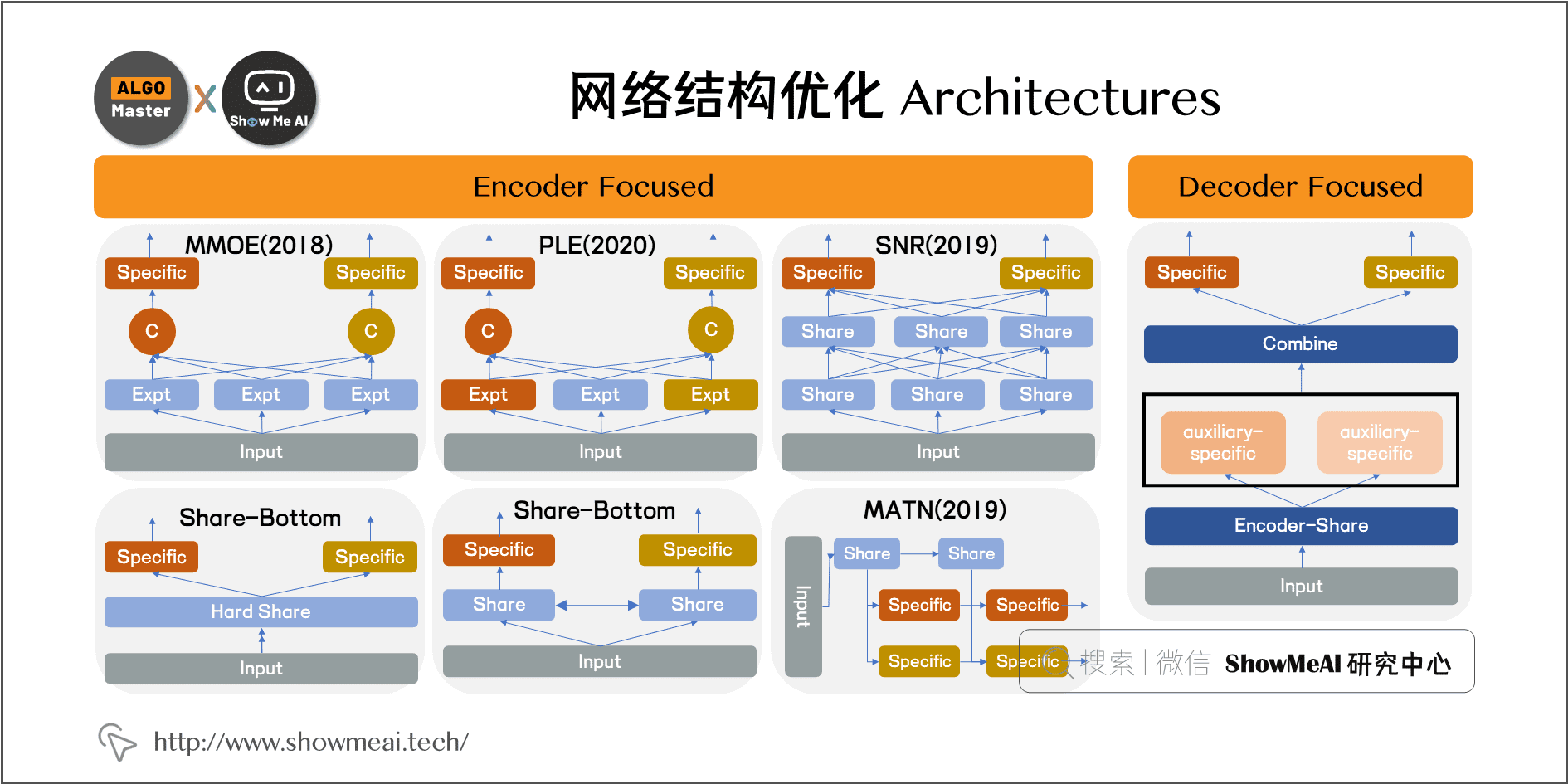
下图中对早期的Share Bottom,MMoE,PLE三种典型网络结构及对应的动机和公式做了总结。
- Shared Bottom 公式 MMoE:MMoE将shared bottom分解成多个Expert,然后通过门控网络自动控制不同任务对这些Expert的梯度贡献。
- MMoE 公式 PLE:PLE在MMoE的基础上又为每个任务增加了自有的Expert,仅由本任务对其梯度更新。