
先是一道算法题
很简单的
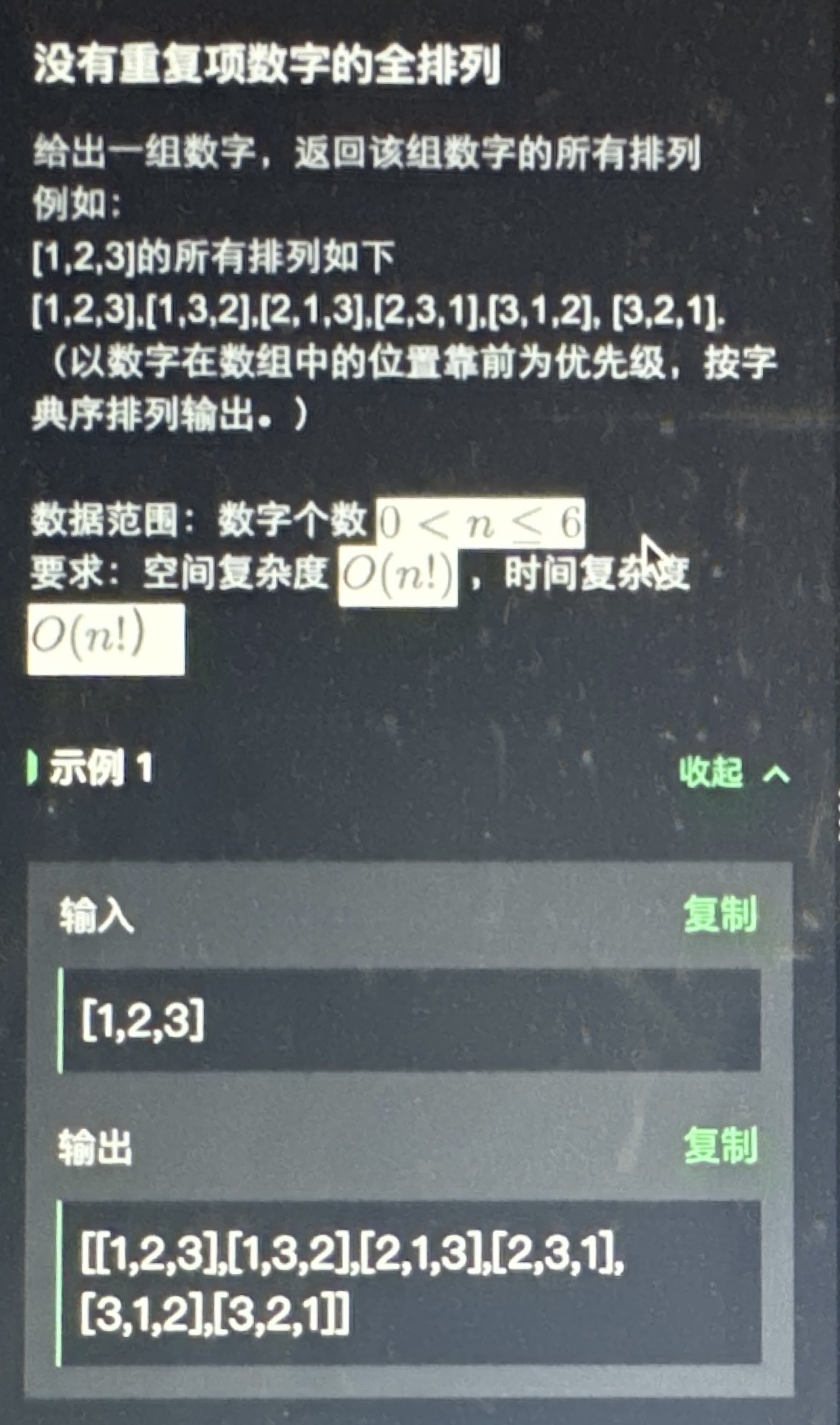
import java.util.ArrayList;
import java.util.Arrays;
public class Solution {
public ArrayList<ArrayList<Integer>> permute(int[] nums) {
ArrayList<ArrayList<Integer>> result = new ArrayList<>();
permuteHelper(nums, 0, result);
return result;
}
private void permuteHelper(int[] nums, int start, ArrayList<ArrayList<Integer>> result) {
if (start == nums.length - 1) {
result.add(new ArrayList<>(Arrays.asList(nums)));
return;
}
for (int i = start; i < nums.length; i++) {
swap(nums, start, i);
permuteHelper(nums, start + 1, result);
swap(nums, start, i); // 回溯
}
}
private void swap(int[] nums, int i, int j) {
int temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}
public static void main(String[] args) {
Solution solution = new Solution();
int[] nums = {1, 2, 3};
ArrayList<ArrayList<Integer>> permutations = solution.permute(nums);
for (ArrayList<Integer> permutation : permutations) {
System.out.println(permutation);
}
}
}
面试先自我介绍,介绍了美团的项目
问
- binlog 同步数据库到es,若没有消费到怎么办?
其实是kafka的可靠性问题
主要考虑 BCP 核对及定时任务主动刷新 ES 数据。
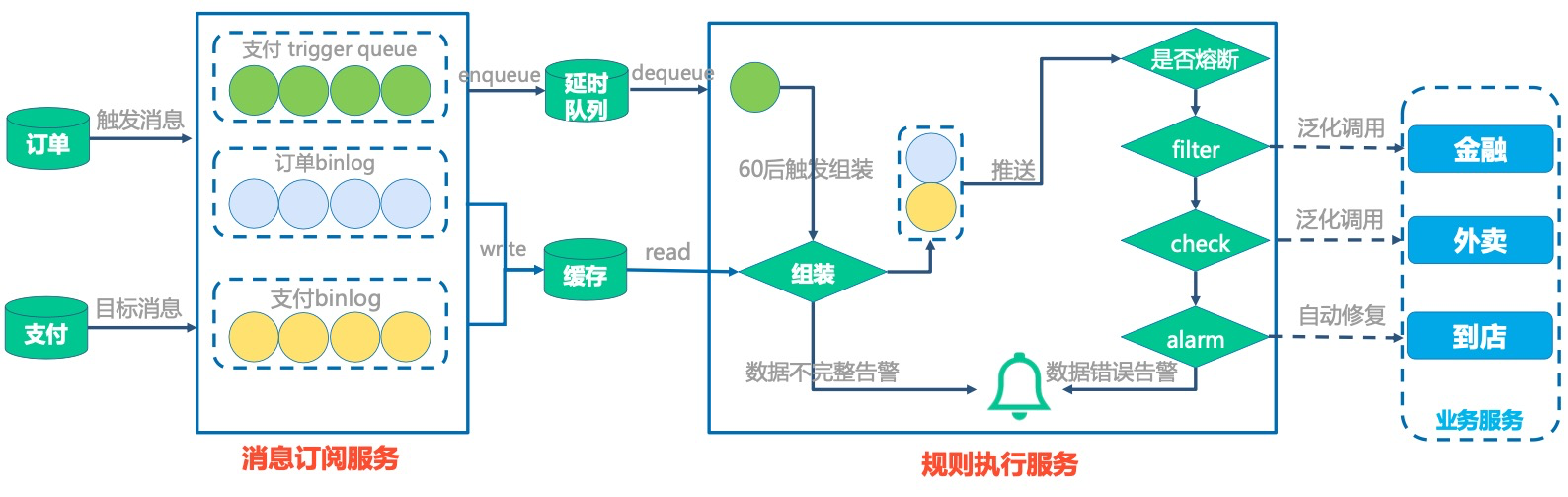
美团业务正确性校验平台 BCP的设计与实践【tool.lu】
为了减少数据反复刷的成本,核心数据使用版本号的概念,相同版本号的数据不再刷新。
例如当前 DB 中版本为 V2,ES 中版本为 V2,在某一次数据更新后,DB 数据版本号更新为 V3,由于网络异常导致 binlog 消费出现问题,ES 中数据未能得到及时更新,定时任务会识别到 DB 中的版本高于 ES 中的版本,会触发主动更新流程。
- 你们的数据库用的是什么隔离级别
数据库的隔离级别主要用于解决并发事务中的一些问题,如脏读、不可重复读和幻读。不同的数据库系统可能支持的隔离级别不同,但通常包括以下几种:
- 读未提交(Read Uncommitted):允许事务读取其他未提交事务的更改。这可能导致脏读。
- 读已提交(Read Committed):只允许事务读取其他已提交事务的更改。这可以防止脏读,但仍然可能遇到不可重复读。
- 可重复读(Repeatable Read):确保在一个事务中多次读取同一数据的结果是一致的,即使其他事务在这期间尝试修改了数据。这可以防止不可重复读,但仍然可能遇到幻读。
- 串行化(Serializable):最高级别的隔离,通过锁定涉及的所有数据来避免脏读、不可重复读和幻读。这会导致事务串行执行,降低并发性能。
一般公司在选择隔离级别时会考虑以下因素:
- 性能:较低的隔离级别(如读已提交)可以提供更好的并发性能,但可能牺牲一些数据一致性。
- 一致性:较高的隔离级别(如可重复读或串行化)可以提供更强的数据一致性保证,但可能会降低并发性能。
- 业务需求:不同的业务场景对数据一致性的需求不同,有些业务可能更注重性能,有些则更注重数据准确性。
在实际应用中,很多公司可能会选择读已提交作为默认的隔离级别,因为它提供了一个较好的平衡点,能够防止脏读,同时保持相对较高的并发性能。然而,对于一些需要严格一致性的业务场景,可能会选择可重复读或串行化。